


[ad_1]
Pandas is a strong and widely-used open-source library for knowledge manipulation and evaluation utilizing Python. One in every of its key options is the flexibility to group knowledge utilizing the groupby operate by splitting a DataFrame into teams primarily based on a number of columns after which making use of numerous aggregation capabilities to every one among them.

Picture from Unsplash
The groupby operate is extremely highly effective, because it permits you to rapidly summarize and analyze massive datasets. For instance, you’ll be able to group a dataset by a particular column and calculate the imply, sum, or rely of the remaining columns for every group. You can too group by a number of columns to get a extra granular understanding of your knowledge. Moreover, it permits you to apply customized aggregation capabilities, which is usually a very highly effective device for complicated knowledge evaluation duties.
On this tutorial, you’ll learn to use the groupby operate in Pandas to group various kinds of knowledge and carry out totally different aggregation operations. By the tip of this tutorial, it is best to be capable to use this operate to investigate and summarize knowledge in numerous methods.
Ideas are internalized when practiced nicely and that is what we’re going to do subsequent i.e. get hands-on with Pandas groupby operate. It’s endorsed to make use of a Jupyter Notebook for this tutorial as you’ll be able to see the output at every step.
Generate Pattern Information
Import the next libraries:
- Pandas: To create a dataframe and apply group by
- Random – To generate random knowledge
- Pprint – To print dictionaries
import pandas as pd
import random
import pprint
Subsequent, we are going to initialize an empty dataframe and fill in values for every column as proven beneath:
df = pd.DataFrame()
names = [
"Sankepally",
"Astitva",
"Shagun",
"SURAJ",
"Amit",
"RITAM",
"Rishav",
"Chandan",
"Diganta",
"Abhishek",
"Arpit",
"Salman",
"Anup",
"Santosh",
"Richard",
]
main = [
"Electrical Engineering",
"Mechanical Engineering",
"Electronic Engineering",
"Computer Engineering",
"Artificial Intelligence",
"Biotechnology",
]
yr_adm = random.pattern(checklist(vary(2018, 2023)) * 100, 15)
marks = random.pattern(vary(40, 101), 15)
num_add_sbj = random.pattern(checklist(vary(2)) * 100, 15)
df["St_Name"] = names
df["Major"] = random.pattern(main * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Bonus tip – a cleaner solution to do the identical process is by making a dictionary of all variables and values and later changing it to a dataframe.
student_dict = {
"St_Name": [
"Sankepally",
"Astitva",
"Shagun",
"SURAJ",
"Amit",
"RITAM",
"Rishav",
"Chandan",
"Diganta",
"Abhishek",
"Arpit",
"Salman",
"Anup",
"Santosh",
"Richard",
],
"Main": random.pattern(
[
"Electrical Engineering",
"Mechanical Engineering",
"Electronic Engineering",
"Computer Engineering",
"Artificial Intelligence",
"Biotechnology",
]
* 100,
15,
),
"Year_adm": random.pattern(checklist(vary(2018, 2023)) * 100, 15),
"Marks": random.pattern(vary(40, 101), 15),
"num_add_sbj": random.pattern(checklist(vary(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
The dataframe seems to be just like the one proven beneath. When working this code, among the values gained’t match as we’re utilizing a random pattern.

Making Teams
Let’s group the information by the “Main” topic and apply the group filter to see what number of information fall into this group.
teams = df.groupby('Main')
teams.get_group('Electrical Engineering')
So, 4 college students belong to the Electrical Engineering main.
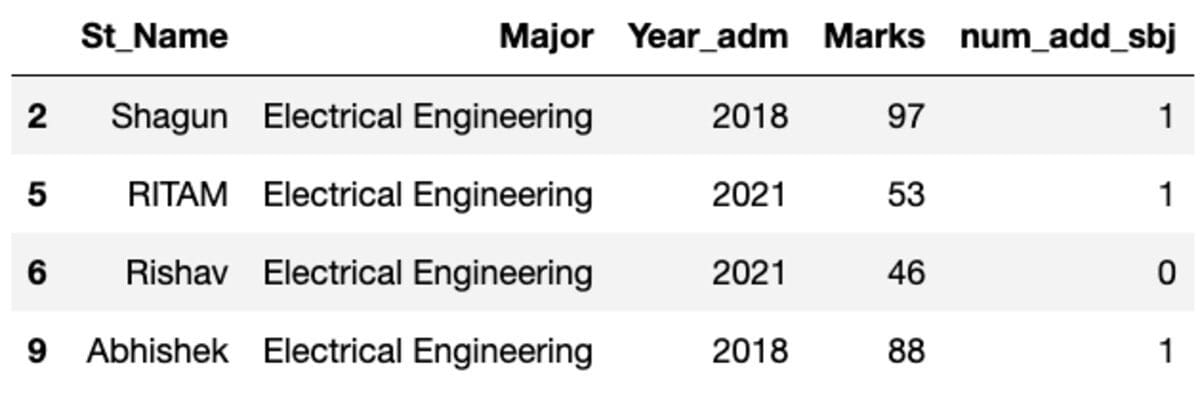
You can too group by multiple column (Main and num_add_sbj on this case).
teams = df.groupby(['Major', 'num_add_sbj'])
Word that every one the combination capabilities that may be utilized to teams with one column will be utilized to teams with a number of columns. For the remainder of the tutorial, let’s give attention to the various kinds of aggregations utilizing a single column for instance.
Let’s create teams utilizing groupby on the “Main” column.
teams = df.groupby('Main')
Making use of Direct Features
Let’s say you need to discover the common marks in every Main. What would you do?
- Select Marks column
- Apply imply operate
- Apply spherical operate to spherical off marks to 2 decimal locations (elective)
teams['Marks'].imply().spherical(2)
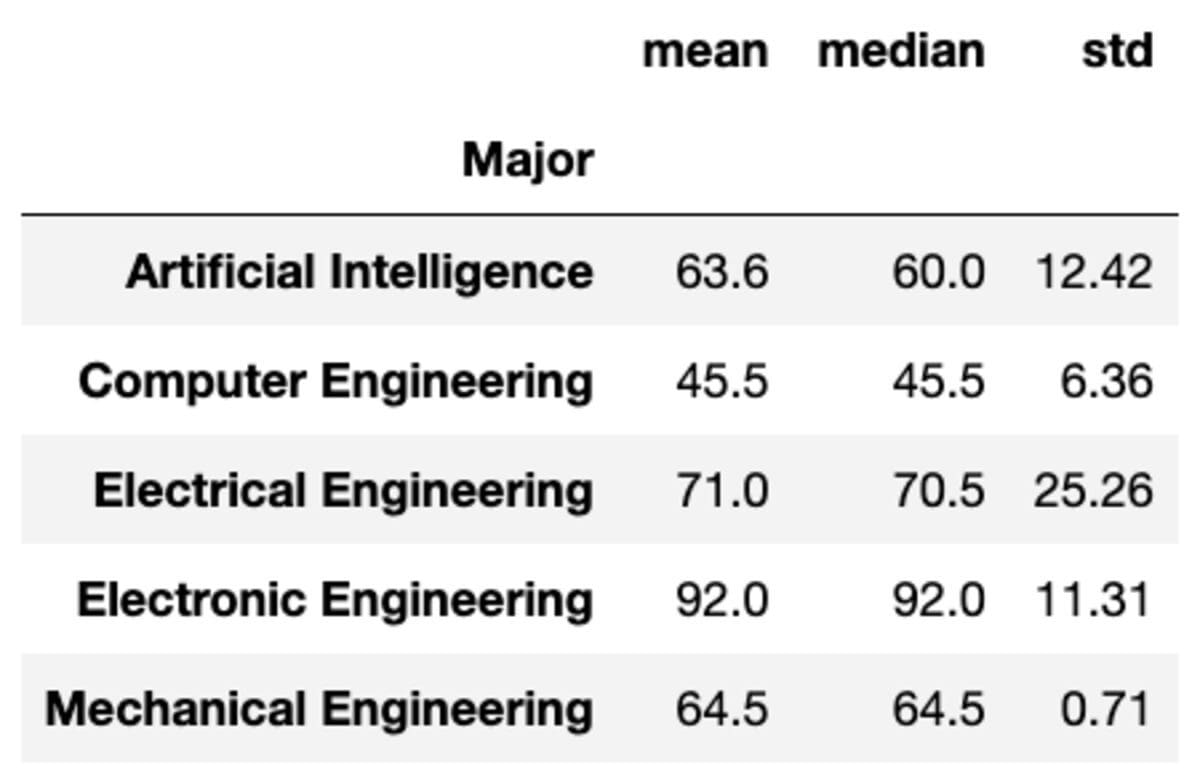
Main
Synthetic Intelligence 63.6
Pc Engineering 45.5
Electrical Engineering 71.0
Digital Engineering 92.0
Mechanical Engineering 64.5
Identify: Marks, dtype: float64
Combination
One other solution to obtain the identical result’s through the use of an mixture operate as proven beneath:
teams['Marks'].mixture('imply').spherical(2)
You can too apply a number of aggregations to the teams by passing the capabilities as an inventory of strings.
teams['Marks'].mixture(['mean', 'median', 'std']).spherical(2)
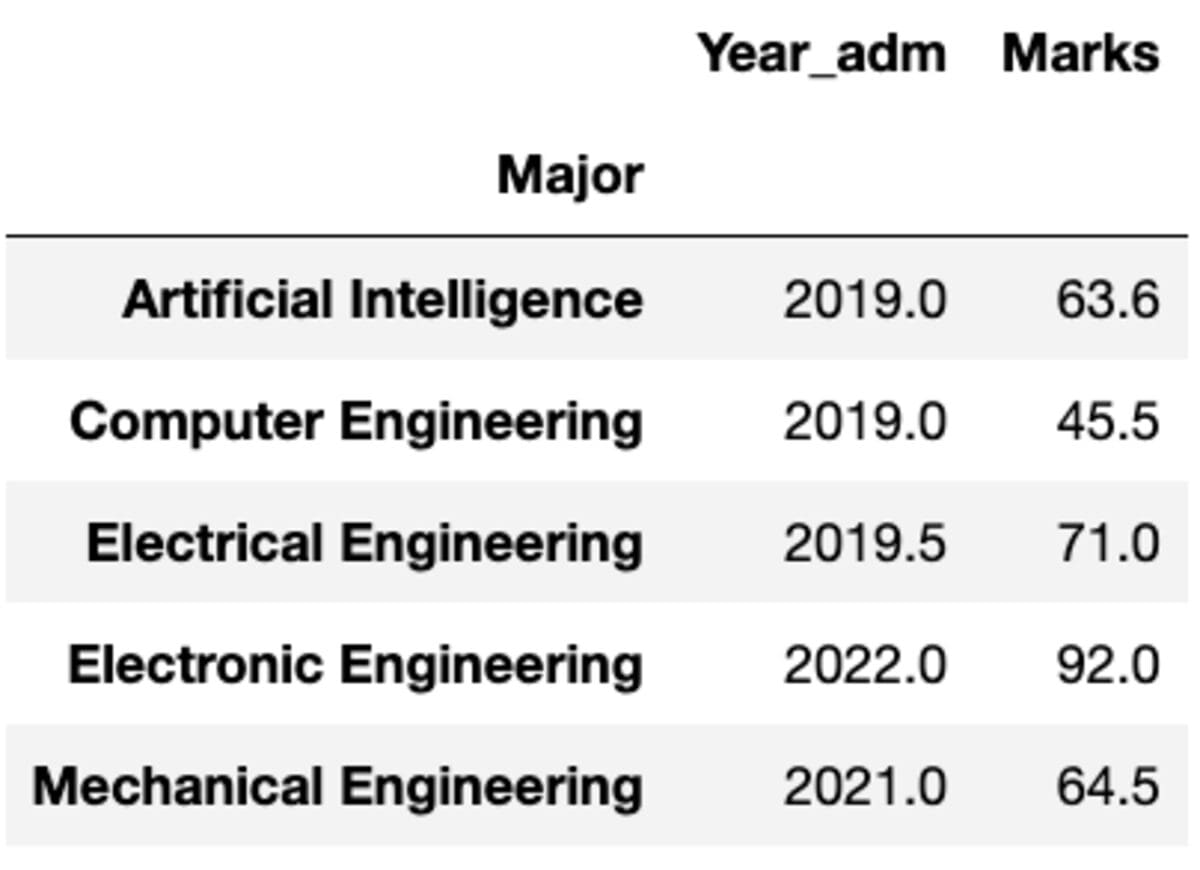
However what if you might want to apply a unique operate to a unique column. Don’t fear. You can too try this by passing {column: operate} pair.
teams.mixture({'Year_adm': 'median', 'Marks': 'imply'})
Transforms
You could very nicely have to carry out customized transformations to a specific column which will be simply achieved utilizing groupby(). Let’s outline a regular scalar much like the one accessible in sklearn’s preprocessing module. You possibly can remodel all of the columns by calling the remodel methodology and passing the customized operate.
def standard_scalar(x):
return (x - x.imply())/x.std()
teams.remodel(standard_scalar)
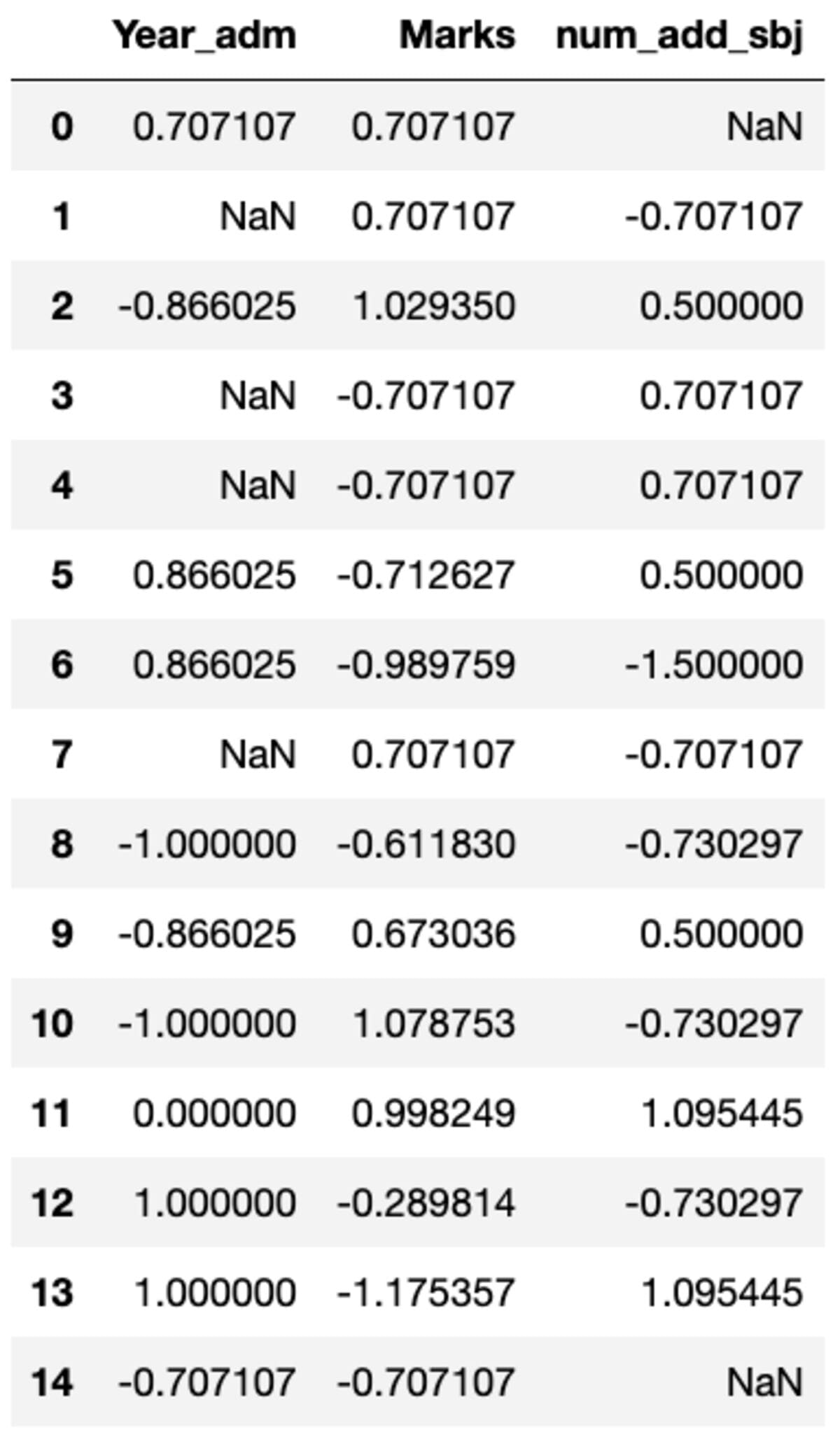
Word that “NaN” represents teams with zero customary deviation.
Filter
You could need to examine which “Main” is underperforming i.e. the one the place common pupil “Marks” are lower than 60. It requires you to use a filter methodology to teams with a operate inside it. The beneath code makes use of a lambda function to attain the filtered outcomes.
teams.filter(lambda x: x['Marks'].imply() < 60)

First
It provides you its first occasion sorted by index.
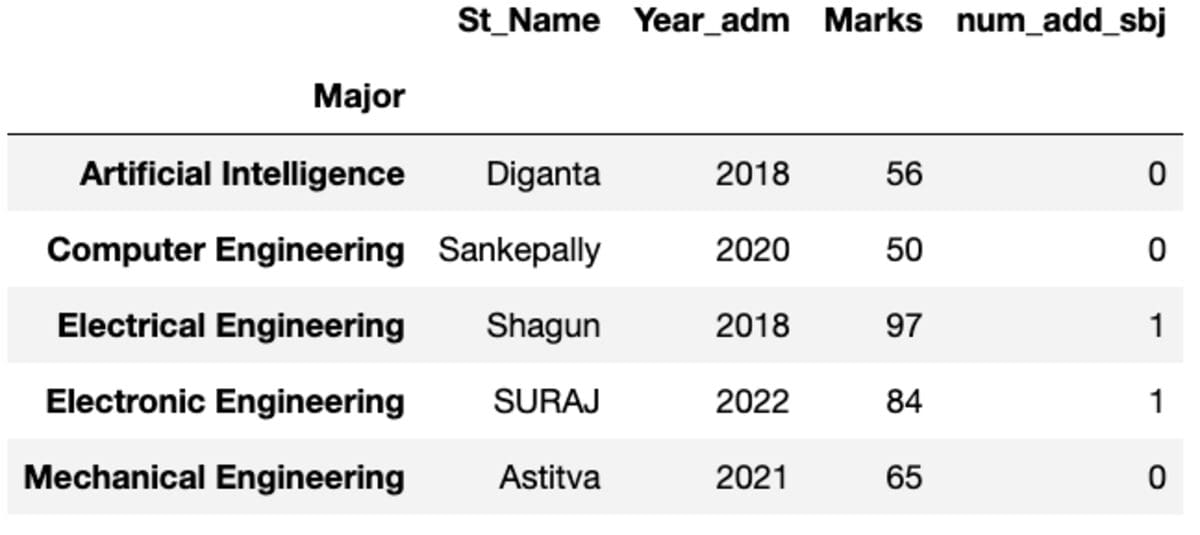
Describe
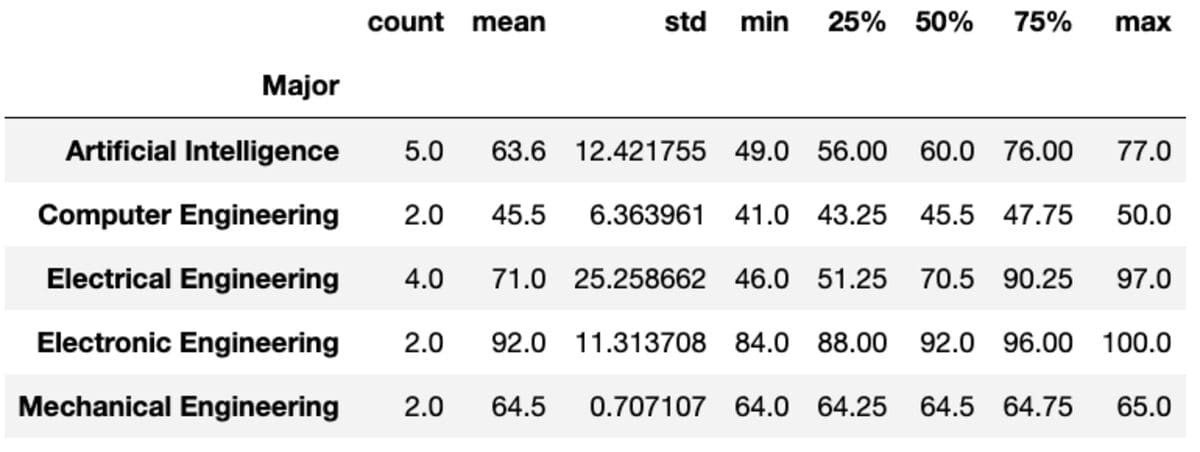
The “describe” methodology returns primary statistics like rely, imply, std, min, max, and many others. for the given columns.
teams['Marks'].describe()
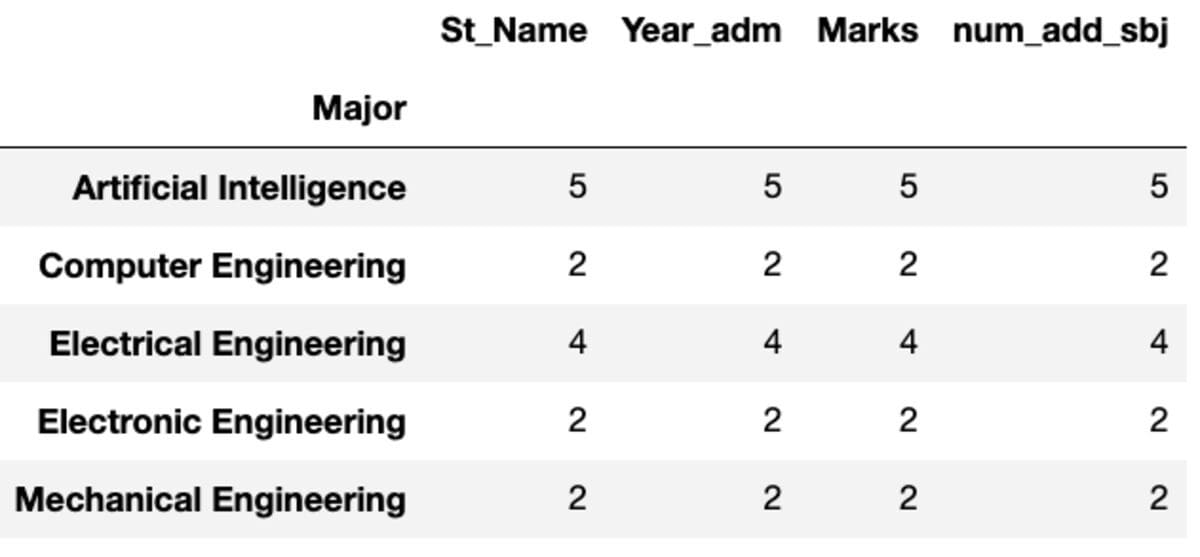
Dimension
Dimension, because the title suggests, returns the dimensions of every group when it comes to the variety of information.
Main
Synthetic Intelligence 5
Pc Engineering 2
Electrical Engineering 4
Digital Engineering 2
Mechanical Engineering 2
dtype: int64
Rely and Nunique
“Rely” returns all values whereas “Nunique” returns solely the distinctive values in that group.
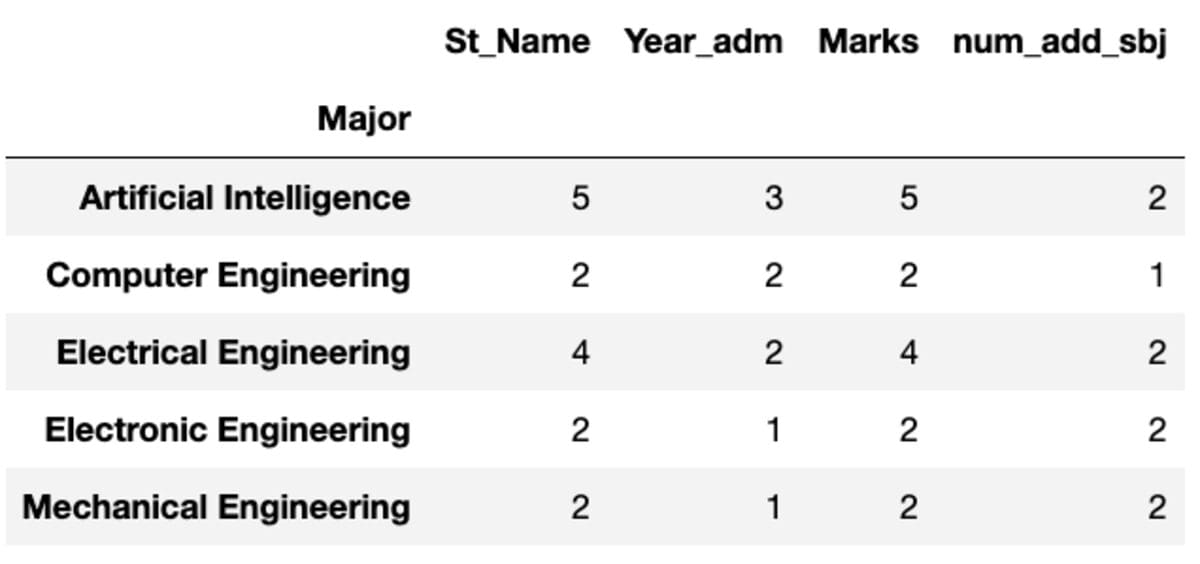
Rename
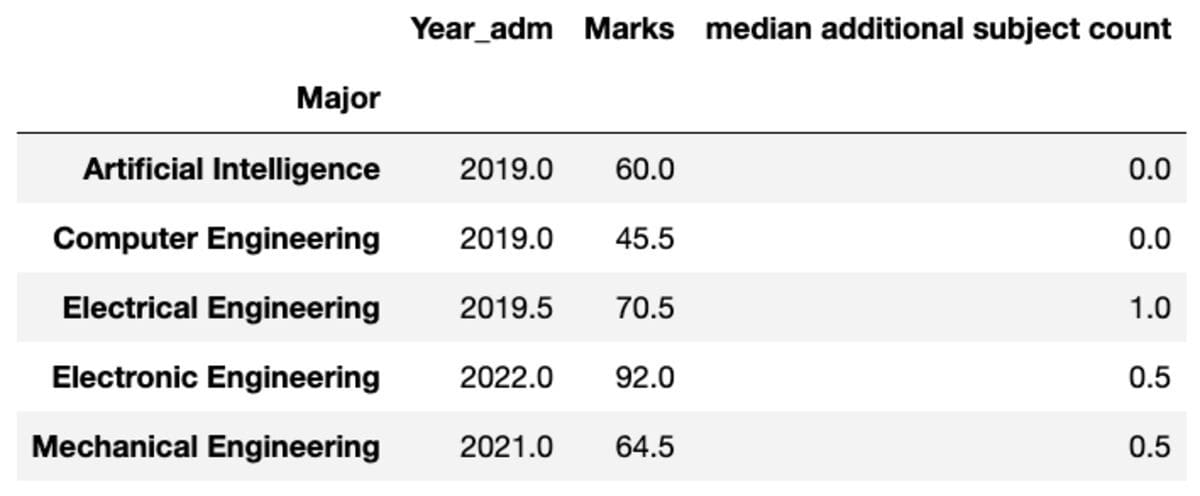
You can too rename the aggregated columns’ title as per your desire.
teams.mixture("median").rename(
columns={
"yr_adm": "median 12 months of admission",
"num_add_sbj": "median further topic rely",
}
)
- Be clear on the aim of the groupby: Are you attempting to group the information by one column to get the imply of one other column? Or are you attempting to group the information by a number of columns to get the rely of the rows in every group?
- Perceive the indexing of the information body: The groupby operate makes use of the index to group the information. If you wish to group the information by a column, guarantee that the column is ready because the index or you should use .set_index()
- Use the suitable mixture operate: It may be used with numerous aggregation capabilities like imply(), sum(), rely(), min(), max()
- Use the as_index parameter: When set to False, this parameter tells pandas to make use of the grouped columns as common columns as a substitute of index.
You can too use groupby() along side different pandas capabilities like pivot_table(), crosstab(), and minimize() to extract extra insights out of your knowledge.
A groupby operate is a strong device for knowledge evaluation and manipulation because it permits you to group rows of information primarily based on a number of columns after which carry out mixture calculations on the teams. The tutorial demonstrated numerous methods to make use of the groupby operate with the assistance of code examples. Hope it gives you with an understanding of the totally different choices that include it and in addition how they assist in the information evaluation.
Vidhi Chugh is an AI strategist and a digital transformation chief working on the intersection of product, sciences, and engineering to construct scalable machine studying methods. She is an award-winning innovation chief, an creator, and a global speaker. She is on a mission to democratize machine studying and break the jargon for everybody to be part of this transformation.
[ad_2]
Source link
