

[ad_1]
Discover ways to develop a chatbot that may reply questions primarily based on the data supplied in your organization’s documentation
Not too long ago, I’ve been fascinated by the facility of ChatGPT and its capability to assemble numerous forms of chatbots. I’ve tried and written about a number of approaches to implementing a chatbot that may entry exterior data to enhance its solutions. I joined just a few Discord channels throughout my chatbot coding periods, hoping to get some assist because the libraries are comparatively new, and never a lot documentation is obtainable but. To my amazement, I discovered customized bots that might reply a lot of the questions for the given library.

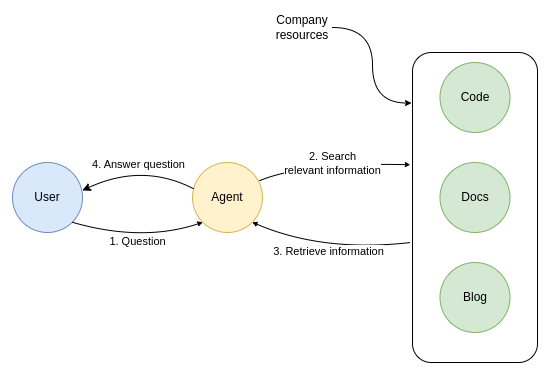
The thought is to offer the chatbot the power to dig by way of numerous sources like firm documentation, code, or different content material to be able to permit it to reply firm assist questions. Since I have already got some expertise with chatbots, I made a decision to check how onerous it’s to implement a customized bot with entry to the corporate’s sources.
On this weblog publish, I’ll stroll you thru how I used OpenAI’s fashions to implement a gross sales & assist agent with within the LangChain library that can be utilized to reply details about functions with a graph database Neo4j. The agent may assist you to debug or produce any Cypher assertion you’re combating. Such an agent may then be deployed to serve customers on Discord or different platforms.

We will probably be utilizing the LangChain library to implement the assist bot. The library is straightforward to make use of and gives a wonderful integration of LLM prompts and Python code, permitting us to develop chatbots in only some minutes. As well as, the library helps a spread of LLMs, textual content embedding fashions, and vector databases, together with utility capabilities that assist us load and embed frequent forms of information we’d come throughout, like textual content, PowerPoint, pictures, HTML, PDF, and extra.
The code for this weblog publish is obtainable on GitHub.
LangChain doc loaders
First, we should preprocess the corporate’s sources and retailer them in a vector database. Fortunately, LangChain will help us load exterior information, calculate textual content embeddings, and retailer the paperwork in a vector database of our alternative.
First, we have now to load the textual content into paperwork. LangChain affords quite a lot of helper functions that can take various formats and types of data and produce a document output. The helper capabilities are known as Doc loaders.
Neo4j has a number of its documentation obtainable in GitHub repositories. Conveniently, LangChain gives a doc loader that takes a repository URL as enter and produces a doc for every file within the repository. Moreover, we will use the filter operate to disregard information throughout the loading course of if wanted.
We are going to start by loading the AsciiDoc information from the Neo4j’s knowledge base repository.
# Data base
kb_loader = GitLoader(
clone_url="https://github.com/neo4j-documentation/knowledge-base",
repo_path="./repos/kb/",
department="grasp",
file_filter=lambda file_path: file_path.endswith(".adoc")
and "articles" in file_path,
)
kb_data = kb_loader.load()
print(len(kb_data)) # 309
Wasn’t that simple as a pie? The GitLoader operate clones the repository and cargo related information as paperwork. On this instance, we specified that the file should finish with .adoc suffix and be part of the articles folder. In complete, 309 articles have been loaded. We additionally should be aware of the scale of the paperwork. For instance, GPT-3.5-turbo has a token restrict of 4000, whereas GPT-4 permits 8000 tokens in a single request. Whereas variety of phrases shouldn’t be precisely similar to the variety of tokens, it’s nonetheless a very good estimator.
Subsequent, we’ll load the documentation of the Graph Data Science repository. Right here, we’ll use a textual content splitter to verify not one of the paperwork exceed 2000 phrases. Once more, I do know that variety of phrases shouldn’t be equal to the variety of tokens, however it’s a good approximation. Defining the edge variety of tokens can considerably have an effect on how the database is discovered and retrieved. I discovered a great article by Pinecone that can help you understand the basics of various chunking strategies.
# Outline textual content chunk technique
splitter = CharacterTextSplitter(
chunk_size=2000,
chunk_overlap=50,
separator=" "
)
# GDS guides
gds_loader = GitLoader(
clone_url="https://github.com/neo4j/graph-data-science",
repo_path="./repos/gds/",
department="grasp",
file_filter=lambda file_path: file_path.endswith(".adoc")
and "pages" in file_path,
)
gds_data = gds_loader.load()
# Break up paperwork into chunks
gds_data_split = splitter.split_documents(gds_data)
print(len(gds_data_split)) #771
We may load different Neo4j repositories that comprise documentation. Nevertheless, the thought is to indicate numerous information loading strategies and never discover all of Neo4j’s repositories containing documentation. Subsequently, we’ll transfer on and take a look at how we will load paperwork from a Pandas Dataframe.
For instance, say that we need to load a YouTube video as a doc supply for our chatbot. Neo4j has its personal YouTube channel and, even I seem in a video or two. Two years in the past I introduced easy methods to implement an data extraction pipeline.
With LangChain, we will use the captions of the video and cargo it as paperwork with solely three strains of code.
yt_loader = YoutubeLoader("1sRgsEKlUr0")
yt_data = yt_loader.load()
yt_data_split = splitter.split_documents(yt_data)
print(len(yt_data_split)) #10
It couldn’t get any simpler than this. Subsequent, we’ll take a look at loading paperwork from a Pandas dataframe. A month in the past, I retrieved data from Neo4j medium publication for a separate weblog publish. Since we need to deliver exterior details about Neo4j to the bot, we will additionally use the content material of the medium articles.
article_url = "https://uncooked.githubusercontent.com/tomasonjo/blog-datasets/most important/medium/neo4j_articles.csv"
medium = pd.read_csv(article_url, sep=";")
medium["source"] = medium["url"]
medium_loader = DataFrameLoader(
medium[["text", "source"]],
page_content_column="textual content")
medium_data = medium_loader.load()
medium_data_split = splitter.split_documents(medium_data)
print(len(medium_data_split)) #4254
Right here, we used Pandas to load a CSV file from GitHub, renamed one column, and used the DataFrameLoaderoperate to load the articles as paperwork. Since medium posts may exceed 4000 tokens, we used the textual content splitter to separate the articles into a number of chunks.
The final supply we’ll use is the Stack Overflow API. Stack Overflow is an internet platform the place customers assist others resolve coding issues. Their API doesn’t require any authorization. Subsequently, we will use the API to retrieve questions with accepted solutions which are tagged with the Neo4j tag.
so_data = []
for i in vary(1, 20):
# Outline the Stack Overflow API endpoint and parameters
api_url = "https://api.stackexchange.com/2.3/questions"
params = {
"order": "desc",
"kind": "creation",
"filter": "!-MBrU_IzpJ5H-AG6Bbzy.X-BYQe(2v-.J",
"tagged": "neo4j",
"website": "stackoverflow",
"pagesize": 100,
"web page": i,
}
# Ship GET request to Stack Overflow API
response = requests.get(api_url, params=params)
information = response.json()
# Retrieve the resolved questions
resolved_questions = [
question
for question in data["items"]
if query["is_answered"] and query.get("accepted_answer_id")
]# Print the resolved questions
for query in resolved_questions:
textual content = (
"Title:",
query["title"] + "n" + "Query:",
BeautifulSoup(query["body"]).get_text()
+ "n"
+ BeautifulSoup(
[x["body"] for x in query["answers"] if x["is_accepted"]][0]
).get_text(),
)
supply = query["link"]
so_data.append(Doc(page_content=str(textual content), metadata={"supply": supply}))
print(len(so_data)) #777
Every permitted reply and the unique query are used to assemble a single doc. Since most Stack overflow questions and solutions don’t exceed 4000 tokens, we skipped the text-splitting step.
Now that we have now loaded the documentation sources as paperwork, we will transfer on to the subsequent step.
Storing paperwork in a vector database
A chatbot finds related data by evaluating the vector embedding of questions with doc embeddings. A textual content embedding is a machine-readable illustration of textual content within the type of a vector or, extra plainly, an inventory of floats. On this instance, we’ll use the ada-002 mannequin supplied by OpenAI to embed paperwork.
The entire concept behind vector databases is the power to retailer vectors and supply quick similarity searches. The vectors are normally in contrast utilizing cosine similarity. LangChain contains integration with a variety of vector databases. To maintain issues easy, we’ll use the Chroma vector database, which can be utilized as an area in-memory. For a extra critical chatbot software, we need to use a persistent database that doesn’t lose information as soon as the script or pocket book is closed.
We are going to create two collections of paperwork. The primary will probably be extra gross sales and advertising and marketing oriented, containing paperwork from Medium and YouTube. The second assortment focuses extra on assist use circumstances and consists of documentation and Stack Overflow paperwork.
# Outline embedding mannequin
OPENAI_API_KEY = "OPENAI_API_KEY"
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)sales_data = medium_data_split + yt_data_split
sales_store = Chroma.from_documents(
sales_data, embeddings, collection_name="gross sales"
)
support_data = kb_data + gds_data_split + so_data
support_store = Chroma.from_documents(
support_data, embeddings, collection_name="assist"
)
This script runs every doc by way of OpenAI’s textual content embedding API and inserts the ensuing embedding together with textual content within the Chroma database. The method of textual content embedding prices 0.80$, which is an affordable worth.
Query answering utilizing exterior context
The very last thing to do is to implement two separate question-answering circulate. The primary will deal with the gross sales & advertising and marketing requests, whereas the opposite will deal with assist. The LangChain library makes use of LLMs for reasoning and offering solutions to the consumer. Subsequently, we begin by defining the LLM. Right here, we will probably be utilizing the GPT-3.5-turbo mannequin from OpenAI.
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0,
openai_api_key=OPENAI_API_KEY,
max_tokens=512,
)
Implementing a question-answering circulate is about as simple because it will get with LangChain. We solely want to offer the LLM for use together with the retriever that’s used to fetch related paperwork. Moreover, we have now the choice to customise the LLM immediate used to reply questions.
sales_template = """As a Neo4j advertising and marketing bot, your objective is to offer correct
and useful details about Neo4j, a robust graph database used for
constructing numerous functions. It's best to reply consumer inquiries primarily based on the
context supplied and keep away from making up solutions. If you do not know the reply,
merely state that you do not know. Keep in mind to offer related data
about Neo4j's options, advantages, and use circumstances to help the consumer in
understanding its worth for software improvement.{context}
Query: {query}"""
SALES_PROMPT = PromptTemplate(
template=sales_template, input_variables=["context", "question"]
)
sales_qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=sales_store.as_retriever(),
chain_type_kwargs={"immediate": SALES_PROMPT},
)
A very powerful a part of the gross sales immediate is to ban the LLM from basing its responses with out counting on official firm sources. Keep in mind, LLMs can act very assertively whereas offering invalid data. Nevertheless, we want to keep away from that situation and keep away from entering into issues the place the bot promised or offered non-existing options. We are able to check the gross sales query answering circulate by asking the next query:

The response to the query appears related and correct. Keep in mind, the data to assemble this response got here from Medium articles.
Subsequent, we’ll implement the assist question-answering circulate. Right here, we’ll permit the LLM mannequin to make use of its information of Cypher and Neo4j to assist resolve the consumer’s downside if the context doesn’t present sufficient data.
support_template = """
As a Neo4j Buyer Assist bot, you're right here to help with any points
a consumer could be going through with their graph database implementation and Cypher statements.
Please present as a lot element as doable about the issue, easy methods to resolve it, and steps a consumer ought to take to repair it.
If the supplied context does not present sufficient data, you're allowed to make use of your information and expertise to give you the absolute best help.{context}
Query: {query}"""
SUPPORT_PROMPT = PromptTemplate(
template=support_template, input_variables=["context", "question"]
)
support_qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=support_store.as_retriever(),
chain_type_kwargs={"immediate": SUPPORT_PROMPT},
)
And once more, we will check the assist question-answering skills. I took a random query from Neo4j’s discord server.

The response is kind of to the purpose. Keep in mind, we retrieved the Graph Knowledge Science documentation and are utilizing it as context to type the chatbot questions.
Agent implementation
We now have two separate directions and shops for gross sales and assist responses. If we needed to put a human within the loop to differentiate between the 2, the entire level of the chatbot could be misplaced. Fortunately, we will use a LangChain agent to resolve which instrument to make use of primarily based on the consumer enter. First, we have to outline the obtainable instruments of an agent together with directions on when and easy methods to use them.
instruments = [
Tool(
name="sales",
func=sales_qa.run,
description="""useful for when a user is interested in various Neo4j information,
use-cases, or applications. A user is not asking for any debugging, but is only
interested in general advice for integrating and using Neo4j.
Input should be a fully formed question.""",
),
Tool(
name="support",
func=support_qa.run,
description="""useful for when when a user asks to optimize or debug a Cypher statement or needs
specific instructions how to accomplish a specified task.
Input should be a fully formed question.""",
),
]
The outline of a instrument is utilized by an agent to establish when and easy methods to use a instrument. For instance, the assist instrument ought to be used to optimize or debug a Cypher assertion and the enter to the instrument ought to be a completely shaped query.
The very last thing we have to do is to initialize the agent.
agent = initialize_agent(
instruments,
llm,
agent="zero-shot-react-description",
verbose=True
)
Now we will go forward and check the agent on a few questions.


Keep in mind, the principle distinction between the 2 QAs beside the context sources is that we permit the assist QA to type solutions that may’t be discovered within the supplied context. Alternatively, we prohibit the gross sales QA from doing that to keep away from any overpromising statements.
Abstract
Within the period of LLMs, you possibly can develop a chatbot that makes use of firm’s sources to reply questions in a single day because of LangChain library because it affords numerous doc loaders in addition to integration with well-liked LLM fashions. Subsequently, the one factor you might want to do is to gather firm’s sources, import them right into a vector database, and you’re good to go. Simply notice that the implementation shouldn’t be deterministic, which suggests you will get barely completely different outcomes on similar prompts. GPT-4 mannequin is significantly better for extra correct and constant responses.
Let me know when you’ve got any concepts or suggestions relating to the chatbot implementation. As all the time, the code is obtainable on GitHub.
[ad_2]
Source link
