


[ad_1]
Think about you’re chilling in your little log cabin within the woods on their lonesome. As you begin with the 2nd ebook of the week on a December night, you hear some heavy foot-steps close by. You run to the window to see what it was. By way of the window, you see a big and seemingly furry silhouette fade into the darkish woods simply past the entrance yard. The data you obtained out of your setting screams of a bigfoot encounter, however your rational thoughts tells you that it’s much more seemingly that it’s simply an excessively enthusiastic hiker passing by.
You simply efficiently made the “proper mistake” by assuming that it is in all probability only a hiker, although the data you could have suggests in any other case. Your thoughts discovered a “rational clarification” to the uncooked data because of the years of expertise you could have within the woods.
An experiment by Liu et al. [1] concerned scanning individuals’ brains as they checked out photographs of grey “static”. They noticed that the frontal and occipital areas of the individuals’ brains fired into motion once they thought they noticed a face, and these areas are thought to take care of higher-level pondering – equivalent to planning and reminiscence. This burst of exercise could mirror the affect of expectation and expertise.
As elaborated in It’s Bayes All The Manner Up [2], Corlett, Frith & Fletcher [3] constructed a mannequin of notion which concerned a “handshake” between the “top-down” and the “bottom-up” ends of human notion, which will be outlined in easy phrases as follows:
- Backside-up: Processes and infers direct conclusions from uncooked data coming in from the sense organs. Scary Silhouette + Howls = bigfoot!
- Prime-down: Provides a “layer of reasoning” on high of the uncooked data that’s obtained and makes use of “realized priors” (i.e., expertise from the previous) to make sense out of the information. Scary Silhouette + Howls = an excessively enthusiastic (or drunk) hiker.
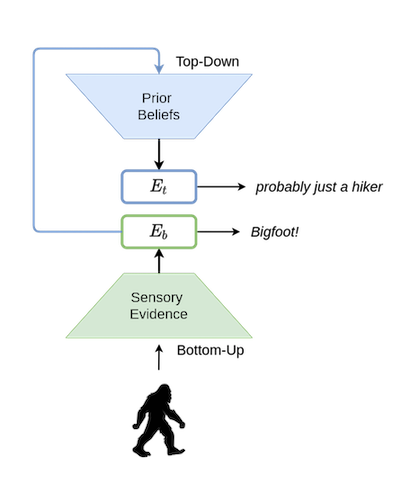
Youngsters are more likely to “fall for” the direct conclusions made by bottom-up notion. It’s because their top-down notion has not had sufficient “expertise/coaching information” to be taught and refine itself. In a manner, we will say that their “world mannequin” is inferior to that of adults.
An attention-grabbing consequence of a robust top-down notion is the power of us people to see issues like animals/faces within the clouds (Pareidolia). This bizarre phenomenon within the mind would possibly look like a bug to us, however it was a life saving characteristic for our ancestors who have been hunters/gatherers. It was safer for them to imagine that they noticed a face, even when there was none. This labored as a way of safety from predators within the wild.
What Are Multimodal Language Fashions?
Massive Language Fashions like that of GPT-3/Luminous/PaLM are, in easy phrases, subsequent token predictors. One can consider them as (massive) neural networks which have been skilled to categorise the subsequent phrase/punctuation in a sentence, which, if performed sufficient occasions, appears to generate textual content that’s coherent with the context.
Multimodal Language Fashions (LMs) are an try to make such language fashions understand the world in a manner that’s one step nearer to that of people. Many of the in style deep-learning fashions as we speak (Like ResNets, GPT-Neo, and so forth) are purely specialised for both imaginative and prescient or language primarily based duties. ResNets are good for extracting data from photographs, and language fashions like GPT-Neo are good at producing textual content. Multimodal LMs are an try to make neural nets understand data within the type of each photographs and textual content by combining imaginative and prescient and language fashions.
So The place Do Multimodal LMs Come In?
Multimodal LMs have the ability to leverage the world information encoded inside its Language Mannequin in different domains like photographs. We people don’t simply learn and write. We see, learn, and write. Multimodal LMs attempt to emulate this by adapting their picture encoders to be appropriate with the “embedding area” of their LMs.
One such instance is MAGMA [4], which is a GPT-style mannequin that may “see”. It may take an arbitrary sequence of textual content and pictures as an enter and generate textual content accordingly.
It may be used to reply questions associated to photographs, determine and describe objects current within the enter photographs, and can be typically surprisingly good at Optical Character Recognition (OCR). It is usually identified to have a superb humorousness [5].
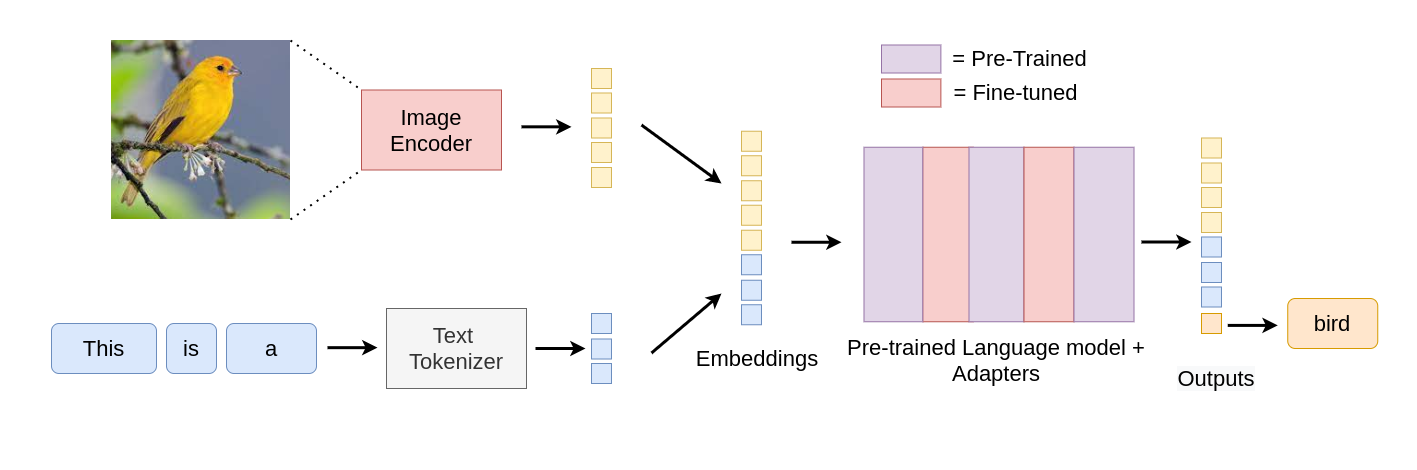
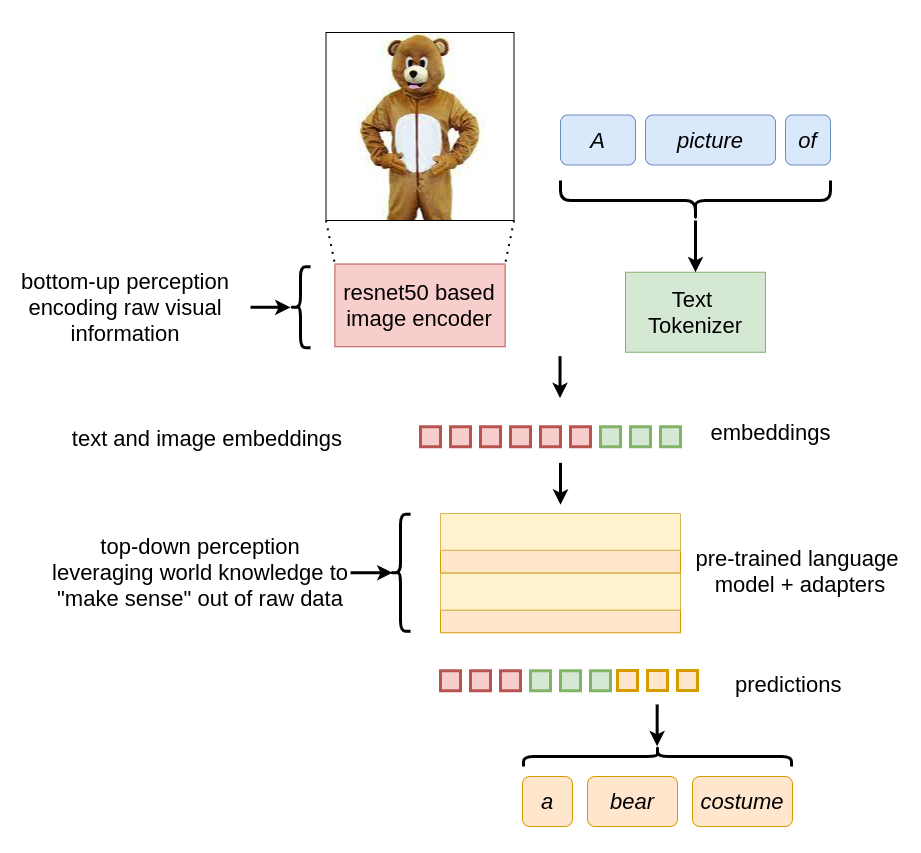
The pre-trained LM on the coronary heart of this structure comprises inside itself the world information that will get leveraged to be able to “make sense out of the inputs”. In additional methods than one, it’s equal to the top-down component of human notion which typically helps it make the appropriate errors, as we’ll see under. With two quotes from It’s Bayes All The Manner Up [2], we will chalk out MAGMA’s structure as follows:
- Backside-up processing is if you construct perceptions right into a mannequin of the world. – Which, on this case, is the picture encoder’s job.
- Prime-down processing is if you let your fashions of the world affect your notion. – That is precisely what the LM is doing.
What Do We Imply by the “Proper Errors”?

Except you’ve seen this picture earlier than, likelihood is excessive that you simply learn it as “I like Paris within the springtime” and never “I like Paris within the the springtime” (discover how there’s a second “the” within the latter). It’s because your top-down notion reads the primary half of the sentence and confidently assumes that the remainder of it’s grammatically right.
Despite the fact that the uncooked information from the picture tells you that there’s a 2nd “the”, you skip over it because of your top-down notion which is wired to sew collectively sentences from phrases with out totally studying them.
Now the query is, does the identical factor happen for MAGMA’s outputs? The reply is sure.
MAGMA is unquestionably not one of the best OCR mannequin on the market. However what it does appear to offer is an intuitive filter on high of a easy job of studying what’s written on a picture. After we erase out both one of many “the” within the picture proven above, the end result nonetheless stays the identical.
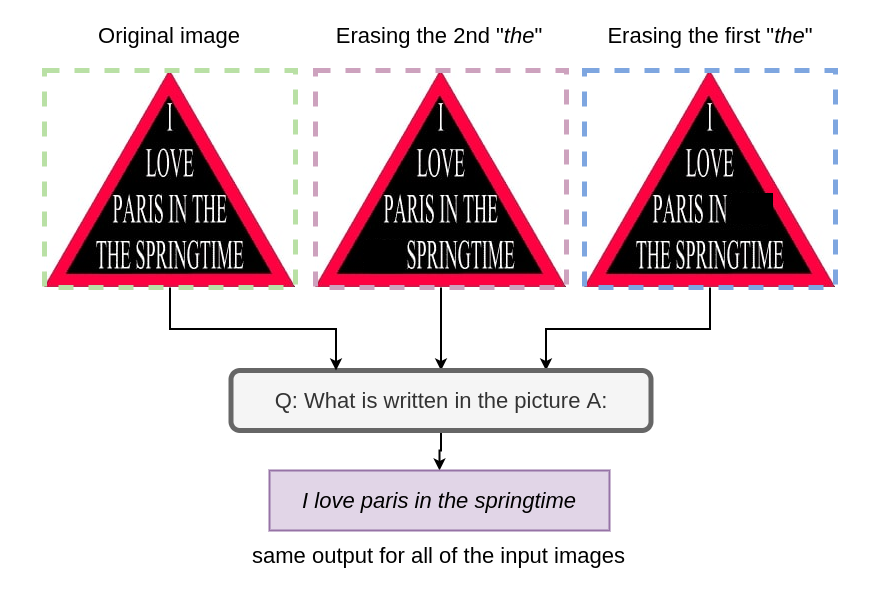
In one other instance, we will see how MAGMA tries to “fill in” the partially erased phrases and comes up with a legitimate output. Despite the fact that it misses one phrase out on the modified picture, it nonetheless finally ends up being shut sufficient.

How Are These Multimodal LMs Any Higher Than the CNNs?
The most typical structure that’s typically used for imaginative and prescient duties are convolutional neural networks (CNNs) [6]. They’re a specialised structure, to be skilled on specialised datasets for very particular duties like classifying photographs.
On the opposite aspect of this spectrum are the Massive Language Fashions. As Gwern [7] places it in his article, they’re principally simply actually massive neural networks with a “easy uniform structure skilled within the dumbest manner attainable” (predicting the subsequent phrase).
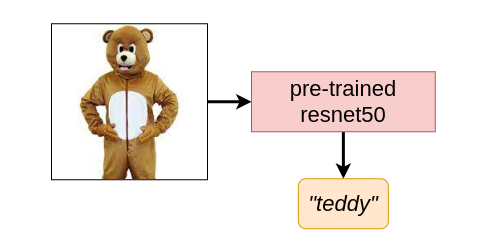
After we feed a picture of a person in a teddy bear costume to a CNN (for instance, a ResNet50), it encodes the data and predicts that it’s a “teddy”. Utterly ignoring the truth that it may simply be a person in a teddy costume. We should always not blame these fashions for this limitation, as they have been simply skilled to find out which class a picture belongs to, given a restricted set of classes (i.e., the ImageNet dataset on this case).
However once we fine-tune the identical CNN to encode photographs in order that they turn out to be appropriate with the “embedding area” of a language mannequin, we will leverage the LM’s world information. This world information inside LMs is loosely equal to a type of “top-down” notion which parses the uncooked visible data despatched from the picture encoder.
How Are Multimodal LMs Totally different From Simply Increasing a Imaginative and prescient Mannequin’s Coaching Knowledge To Embody Photographs of a Teddy Bear Costume?
The issue with explicitly attempting to increase the output area to comprise such issues is that it’s not sensible given the sheer variety of potentialities on the market. LMs, then again, don’t require such preparations as a result of they’ve implicit world information encoded into them (biased or not). The ResNet50 on this case has a really restricted output area.
In a nutshell, the output of one thing like that of a ResNet50 is restricted to solely the labels of the courses it was skilled on, whereas the LM is ready to generate outputs of arbitrary size, thus giving it a a lot bigger output area as massive because the area of the language it was skilled on.
Multimodal LMs are an try to, slightly than increase the output area of a imaginative and prescient mannequin, increase the enter area of an LM by including bottom-up processing to its already current world mannequin.
Closing Phrases
An thrilling analysis path on this area could be to herald extra modalities not solely to the enter, but in addition to the output area. Fashions which might generate each textual content and pictures as one single, seamless output.
Intelligence isn’t all the time about being right, it typically is about making the appropriate errors primarily based on one’s understanding of the world. This precept in itself is a crucial foundation of how people work.
I’m positive a number of AI researchers could be very pleased on the day when AI begins seeing issues within the clouds the way in which we do. It’ll get us one step nearer to the pursuit of creating machines marvel about issues the way in which we do, and ask the questions we by no means may.
Writer Bio
Mayukh is an AI researcher at Aleph-Alpha. His work focuses on reverse engineering Massive Multimodal Language Fashions to make them explainable to people. He’s additionally an Undergrad scholar at Amrita Vishwa Vidyapeetham.
References
[1]: https://www.sciencedirect.com/science/article/abs/pii/S0010945214000288
[2]: https://slatestarcodex.com/2016/09/12/its-bayes-all-the-way-up/
[3]: https://www.nature.com/articles/nrn2536
[4]: https://arxiv.org/abs/2112.05253
[5]: https://twitter.com/Sigmoid_Freud
[ad_2]
Source link
