


[ad_1]
Once I began my first job out of school, I believed I knew a good quantity about machine studying. I had finished two internships at Pinterest and Khan Academy constructing machine studying programs. I spent my final yr at Berkeley doing analysis in deep studying for laptop imaginative and prescient and dealing on Caffe, one of many first common deep studying libraries. After I graduated, I joined a small startup known as Cruise that was constructing self-driving vehicles. Now I’m at Aquarium, the place I get to assist a mess of firms deploying deep studying fashions to resolve vital issues for society.
Through the years, I obtained the possibility to construct out fairly cool deep studying and laptop imaginative and prescient stacks. There are much more folks utilizing deep studying in manufacturing purposes these days in comparison with once I was doing analysis at Berkeley, however many issues that they face are the identical ones I grappled with in 2016 at Cruise. I’ve realized a number of classes about doing deep studying in manufacturing, and I might wish to share a few of these classes with you so that you don’t should be taught them the arduous manner.
A Story

To start out off, let me speak in regards to the first ever ML mannequin deployed onto the automotive at Cruise. As we developed the mannequin, the workflow felt so much like what I used to be used to from my analysis days. We educated open supply fashions on open supply information, built-in them into our manufacturing software program stack, and deployed them onto the automotive. After just a few weeks of labor, we merged the ultimate PR to activate the mannequin to run on the automotive. “Mission achieved!” I believed, after which we moved on to placing out the subsequent fireplace. Little did I do know that the actual work had solely simply begun.
Because the mannequin ran in manufacturing, our QA crew began to note issues with its efficiency. However we had different fashions to arrange and fires to struggle, so we didn’t attempt to instantly handle the problems. 3 months later, once we regarded into them, we found that the coaching and validation scripts had all damaged on account of adjustments within the codebase for the reason that first time we deployed!
After per week of fixing that, we regarded on the failures over the previous few months and realized that a number of the issues we noticed within the mannequin’s manufacturing runs couldn’t be simply solved by modifying the mannequin code, and that we would have liked to go gather and label new information from our autos as an alternative of counting on open supply information. This meant that we would have liked to arrange a labeling course of with all the instruments, operations, and infrastructure that this course of would entail.
One other 3 months later, we had been capable of ship a brand new mannequin that was educated on randomly chosen information that we had collected from our autos after which labeled with our personal instruments. However as we began fixing the straightforward issues, it obtained more durable and more durable to enhance the mannequin, and we needed to turn out to be so much smarter about what adjustments had been prone to yield outcomes. Round 90% of the issues had been solved with cautious information curation of inauspicious or uncommon eventualities as an alternative of deep mannequin structure adjustments or hyperparameter tuning. For instance, we found that the mannequin had poor efficiency on wet days (uncommon in San Francisco) so we labeled extra information from wet days, retrained the mannequin on the brand new information, and the mannequin efficiency improved. Equally, we found that the mannequin had poor efficiency on inexperienced cones (uncommon in comparison with orange cones) so we collected information of inexperienced cones, went by the identical course of, and mannequin efficiency improved. We wanted to arrange a course of the place we may rapidly establish and repair a majority of these issues.
It took only some weeks to hack collectively the primary model of the mannequin. Then one other 6 months to ship a brand new and improved model of the mannequin. And as we labored extra on a number of the items (higher labeling infrastructure, cloud information processing, coaching infrastructure, deployment monitoring) we had been capable of retrain and redeploy fashions about each month to each week. As we arrange extra mannequin pipelines from scratch and labored on bettering them, we started to see some widespread themes. Making use of our learnings to the brand new pipelines, it turned simpler to ship higher fashions quicker and with much less effort.
At all times Be Iterating
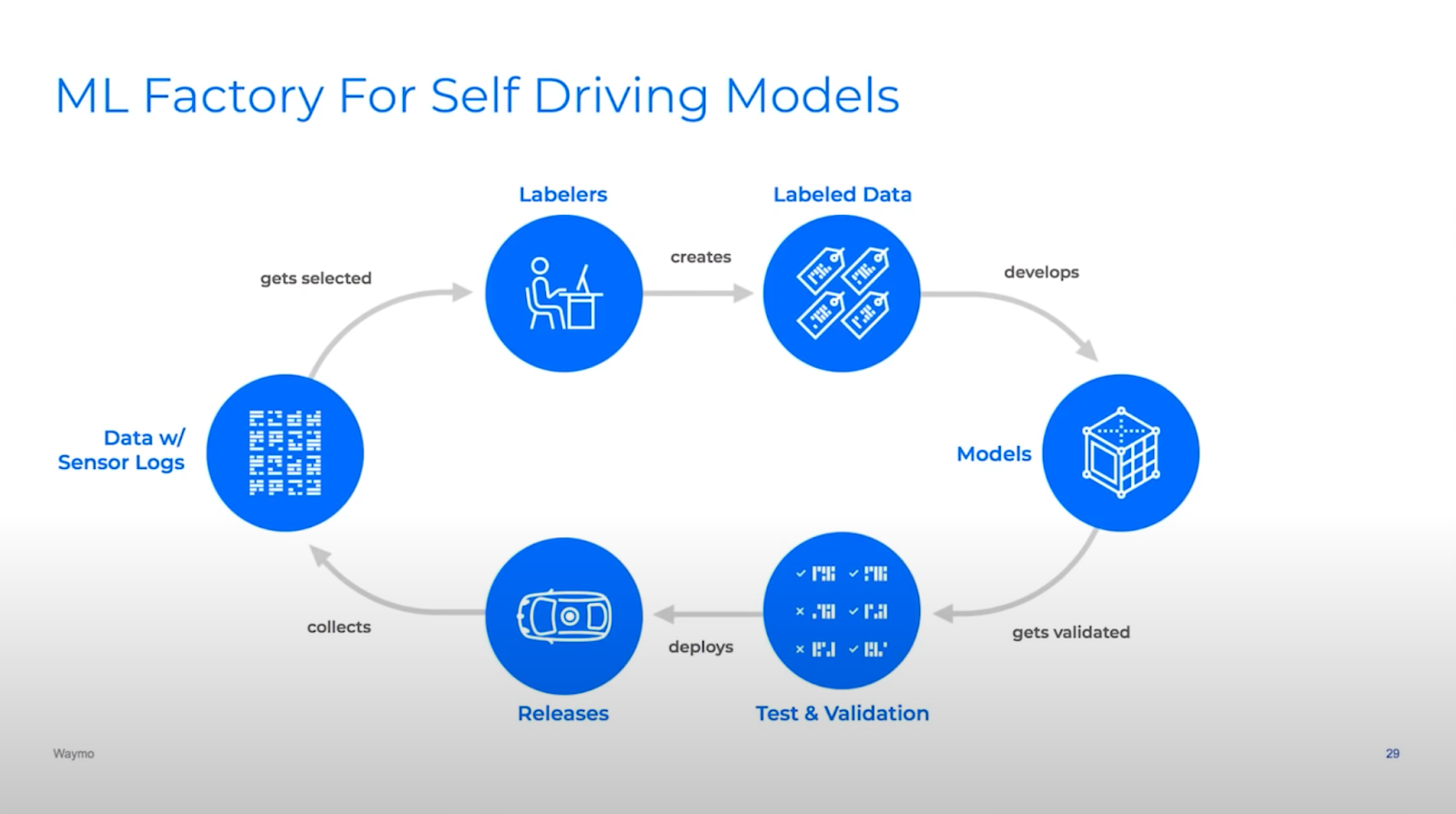

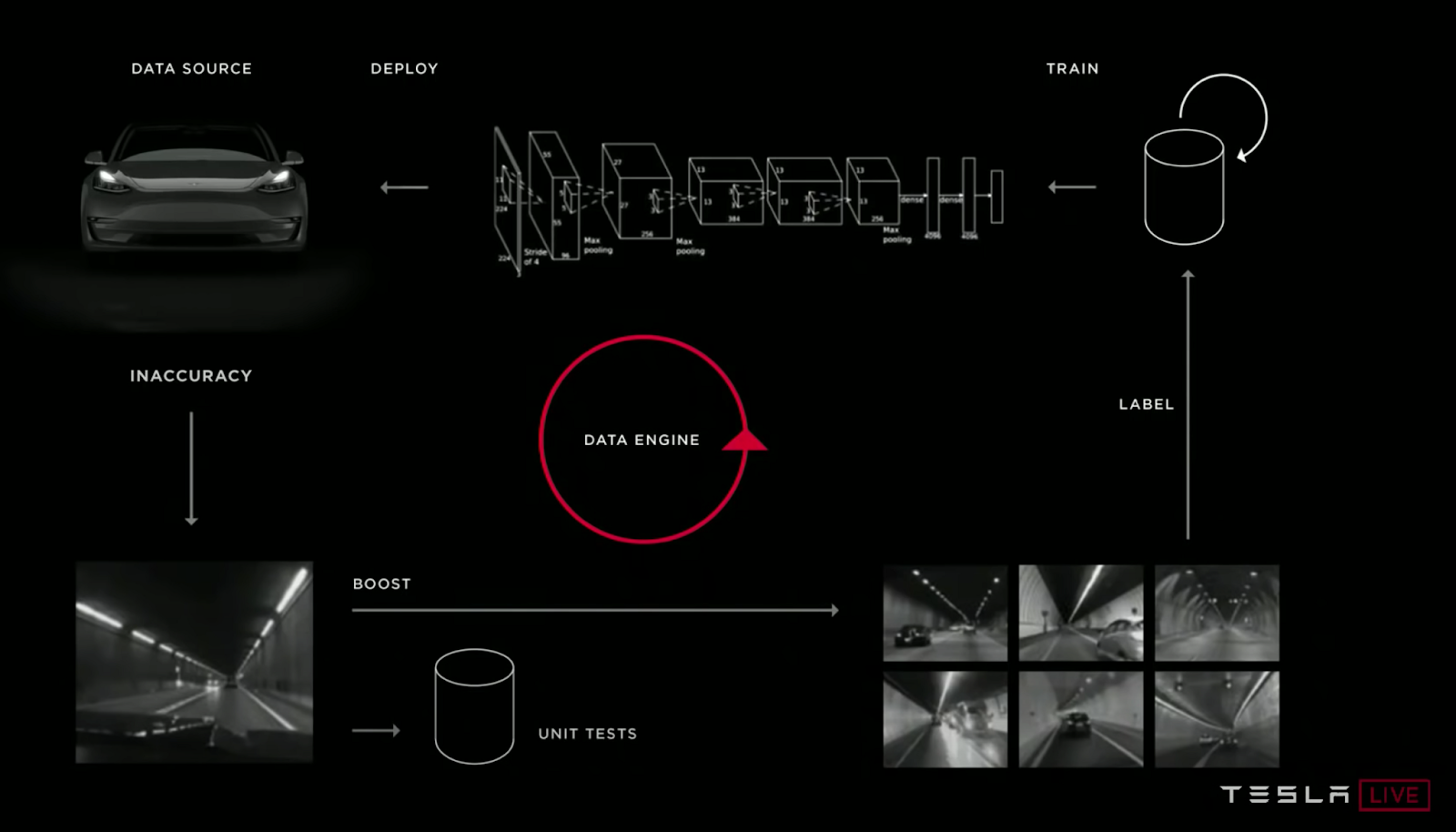
I used to assume that machine studying was in regards to the fashions. Really, machine studying in manufacturing is about pipelines. The most effective predictors of success is the power to successfully iterate in your mannequin pipeline. That does not simply imply iterating rapidly, but additionally iterating intelligently. The second half is essential, in any other case you find yourself with a pipeline that produces unhealthy fashions in a short time.
Most conventional software program is developed in an agile course of that emphasizes fast iterations and supply. It is because the necessities of the product are unknown and have to be found by adaptation, so it is higher to ship an MVP rapidly and iterate than to do exhaustive planning up-front with shaky assumptions.
Simply as the necessities of conventional software program are complicated, the area of knowledge inputs that ML programs should deal with is really huge. Not like regular software program improvement, the standard of an ML mannequin is determined by its implementation in code and on the information that code trains on. This dependency on the information implies that the ML mannequin can “discover” the enter area by dataset development / curation, permitting it to know the necessities of the duty and adapt to it over time with out essentially having to switch the code.
To reap the benefits of this property, machine studying wants an idea of steady studying that emphasizes iteration on the information in addition to the code. Machine studying groups should:
- Uncover issues within the information or mannequin efficiency
- Diagnose why the issues are taking place
- Change the information or the mannequin code to resolve these issues
- Validate that the mannequin is getting higher after retraining
- Deploy the brand new mannequin and repeat
Groups ought to attempt to undergo this cycle at the least each month. If you happen to’re good, possibly each week.
Large firms can run by the mannequin deployment cycle in lower than a day, but it surely’s very troublesome for many groups to construct the infrastructure to do that rapidly and mechanically. Updating fashions any much less regularly than this could result in code rot (the place the mannequin pipeline breaks on account of adjustments to the codebase) or information area shifts (the place the mannequin in manufacturing can not generalize to adjustments within the information over time).
Nonetheless, if finished proper, a crew can get into cadence the place they’re deploying improved fashions to manufacturing on an everyday schedule.
Set Up A Suggestions Loop

A key a part of efficient iteration on a mannequin is to focus effort on fixing essentially the most impactful issues. To enhance a mannequin, you want to have the ability to know what’s fallacious with it and be capable of triage the issues based mostly on precedence for the product / enterprise. There are a number of methods to arrange a suggestions loop, but it surely begins with discovery and triage of errors.
Leverage domain-specific suggestions loops. When obtainable, these will be very highly effective and environment friendly methods of getting mannequin suggestions. For instance, forecasting duties can get labeled information “totally free” by coaching on historic information of what really occurred, permitting them to repeatedly feed in giant quantities of recent information and pretty mechanically adapt to new conditions.
Arrange a workflow the place a human can assessment the outputs of your mannequin and flag when an error happens. That is significantly applicable when it’s straightforward for human assessment to catch errors throughout a number of mannequin inferences. The most typical manner this happens is when prospects discover errors within the mannequin outputs and complain to the ML crew. This isn’t to be underestimated, as this channel allows you to instantly incorporate buyer suggestions into the event cycle! A crew can have people double-check mannequin outputs {that a} buyer may miss: consider an operations particular person watching a robotic type packages on a conveyor belt and clicking a button each time they discover an error occurring.
When the fashions run at too excessive a frequency for people to examine, take into account establishing automated double-checking. That is significantly helpful when it’s straightforward to jot down “sanity checks” in opposition to the mannequin outputs. For instance, flagging each time a lidar object detector and 2D picture object detector disagree on a sure object, or when a frame-to-frame detector disagrees with a temporal monitoring system. When it really works, it offers a number of useful suggestions on the place failure instances happen. When it doesn’t work, it merely exposes errors in your checking system or misses out on conditions the place all of the programs made an error, which is fairly low danger excessive reward.
Probably the most normal (however troublesome) resolution is to investigate mannequin uncertainty in regards to the information it’s working on. A naive instance is to take a look at examples the place the mannequin produced low confidence outputs in manufacturing. This could floor locations the place the mannequin is really unsure, but it surely’s not 100% exact. Generally the mannequin will be confidently fallacious. Generally the mannequin is unsure on account of lack of expertise obtainable to make inference (for instance, noisy enter information {that a} human would battle to make sense of). There are fashions that may clear up these issues, however that is an energetic analysis space [1].
Lastly, one can make the most of suggestions from the mannequin’s suggestions on the coaching set. For instance, analyzing the mannequin’s disagreement with its coaching / validation dataset (i.e. excessive loss examples) surfaces high-confidence failures or labeling errors. Evaluation of neural community embeddings can present a solution to perceive patterns of failure modes within the coaching / validation dataset and discover variations within the distribution of the uncooked information between the coaching and manufacturing datasets.
Automate and Delegate

An enormous a part of iterating quicker is decreasing the quantity of effort wanted to do a single cycle of iteration. Nonetheless, there’s all the time methods to make issues simpler, so one should prioritize what to enhance. I like to consider effort in two methods: clock time and human time.
Clock time refers to time wanted to run sure computational duties like ETL of knowledge, coaching fashions, working inference, calculating metrics, and so forth. Human time refers to time the place a human should actively intervene to run by the pipeline, like manually inspecting outcomes, working instructions, or triggering scripts in the course of the pipeline.
In a manufacturing context, human time is a much more restricted useful resource. Intermittent utilization of human time additionally imposes important switching prices and is inconvenient for the consumer. Usually, it’s way more vital to automate away human time, particularly when the time required comes from a talented ML engineer. For instance, it’s extraordinarily widespread however wasteful to have a number of scripts that have to be manually run in sequence with some handbook shifting of information between steps. Some again of the serviette math: if an ML engineer prices $90 an hour and wastes even 2 hours per week to manually run scripts, that provides as much as $9360 per yr per particular person! Combining a number of scripts with human interrupts right into a single fully-automatic script makes it a lot quicker and simpler to run by a single cycle of the mannequin pipeline, saves some huge cash, and makes your ML engineer a lot much less cranky.
In distinction, clock time typically must be “cheap” (e.g.. will be accomplished in a single day) to be acceptable. The exception is that if ML engineers are working an enormous variety of experiments or if there are excessive value / scaling constraints. It is because clock time is mostly proportional to information scale and mannequin complexity. There’s a big discount in clock time when shifting from native processing to distributed cloud processing. After that, horizontal scaling within the cloud tends to resolve most issues for many groups till attending to mega-scale.
Sadly, it may be unattainable to utterly automate sure duties. Nearly all manufacturing machine studying purposes are supervised studying duties, and most depend on some quantity of human interplay to inform the mannequin what it ought to do. In some domains, human interplay comes totally free (for instance, with social media advice use instances or different purposes with a excessive quantity of direct consumer suggestions). In others, human time is extra restricted or costly, similar to extremely educated radiologists “labeling” CT scans for coaching information.
Both manner, you will need to decrease the period of time (and related prices) wanted from people to enhance the mannequin. Whereas groups which are early on within the course of may depend on an ML engineer to curate the dataset, it’s typically extra economical (or within the radiologist case, mandatory) to have an operations consumer or area professional with out ML information tackle the heavy lifting of knowledge curation. At that time, it turns into vital to arrange an operational course of with good software program tooling to label, high quality examine, enhance, and model management the dataset.
When It Works: ML Engineering At The Fitness center

It will probably take a number of effort and time to construct satisfactory tooling to assist a brand new area or a brand new consumer group, however when finished effectively, the outcomes are effectively value it! At Cruise, one engineer I labored with was significantly intelligent (some would say lazy).
This engineer arrange an iteration cycle the place a mixture of operations suggestions and metadata queries would pattern information to label from locations the place the mannequin had poor efficiency. An offshore operations crew would then label the information and add it to a brand new model of the coaching dataset. The engineer then arrange infrastructure that allowed them to run a single script on their laptop and kick off a sequence of cloud jobs that mechanically retrained and validated a easy mannequin on the newly added information.
Each week, they ran the retrain script. Then they went to the gymnasium whereas the mannequin educated and validated itself. After just a few hours of gymnasium and dinner, they might return to look at the outcomes. Invariably, the brand new and improved information would result in mannequin enhancements. After a fast double-check to verify all the things made sense, they then shipped the brand new mannequin to manufacturing and the automotive’s driving efficiency would enhance. They then spent the remainder of the week engaged on bettering the infrastructure, experimenting with new mannequin architectures, and constructing new mannequin pipelines. Not solely did this engineer get their promotion on the finish of the quarter, they had been in nice form!
The Takeaway
So to recap: in analysis and prototyping levels, the main target is on constructing and delivery a mannequin. However as a system strikes into manufacturing, the secret is in constructing a system that is ready to commonly ship improved fashions with minimal effort. The higher you get at this, the extra fashions you’ll be able to construct!
To that finish, it pays to concentrate on:
- Operating by the mannequin pipeline on an everyday cadence and specializing in delivery fashions which are higher than earlier than. Get a brand new and improved mannequin into manufacturing each week or much less!
- Establishing suggestions loop from the mannequin outputs again to the event course of. Determine what examples the mannequin does poorly on and add extra examples to your coaching dataset.
- Automating duties within the pipeline which are significantly burdensome and constructing a crew construction that enables your crew members to concentrate on their areas of experience. Tesla’s Andrej Karpathy calls the perfect finish state “Operation Vacation.” I say, arrange a workflow the place you’ll be able to ship your ML engineers to the gymnasium and let your ML pipeline do the heavy lifting!
As a disclaimer: in my expertise, the overwhelming majority of issues with mannequin efficiency will be solved with information, however there are particular points that may solely be solved with adjustments to the mannequin code. These adjustments are typically very specific to the mannequin structure at hand – for instance, after engaged on picture object detectors for a variety of years, I’ve spent an excessive amount of time worrying about optimum prior field project for sure side ratios and bettering function map decision on small objects. Nonetheless, as transformers present promise as being the jack-of-all-trades mannequin structure sort for a lot of completely different deep studying duties, I think extra of those methods will turn out to be much less related and the main target of machine studying improvement will shift even additional in the direction of bettering datasets.
Creator Bio
Peter is the cofounder and CEO of Aquarium, an organization that builds instruments to seek out and repair issues in deep studying datasets. Earlier than Aquarium, Peter labored on machine studying for self driving vehicles, schooling, and social media. Be at liberty to succeed in out to Peter via LinkedIn in case you’d like to speak about ML!
Title Picture: “ML Ops Venn Diagram” by Cmbreuel. Licensed underneath the Creative Commons Attribution-Share Alike 4.0 International license.
References:
[1]: Kendall, A. & Gal, Y. (2017). What Uncertainties Do We Want in Bayesian Deep Studying for Laptop Imaginative and prescient? Advances in Neural Data Processing Methods, 5574-5584.
For attribution in tutorial contexts or books, please cite this work as
Peter Gao, “Classes From Deploying Deep Studying To Manufacturing”, The Gradient, 2022.
BibTeX quotation:
@article{gao2022lessons,
creator = {Gao, Peter },
title = {Classes From Deploying Deep Studying To Manufacturing},
journal = {The Gradient},
yr = {2022},
howpublished = {url{https://thegradient.pub/lessons-from-deploying-deep-learning-to-production} },
}
[ad_2]
Source link
