

[ad_1]
With the event of computing and information, autonomous brokers are gaining energy. The necessity for people to have some say over the insurance policies discovered by brokers and to verify that they align with their objectives turns into all of the extra obvious in mild of this.
At the moment, customers both 1) create reward capabilities for desired actions or 2) present in depth labeled information. Each methods current difficulties and are unlikely to be applied in follow. Brokers are weak to reward hacking, making it difficult to design reward capabilities that strike a stability between competing objectives. But, a reward perform may be discovered from annotated examples. Nonetheless, huge quantities of labeled information are wanted to seize the subtleties of particular person customers’ tastes and targets, which has confirmed costly. Moreover, reward capabilities have to be redesigned, or the dataset ought to be re-collected for a brand new person inhabitants with completely different objectives.
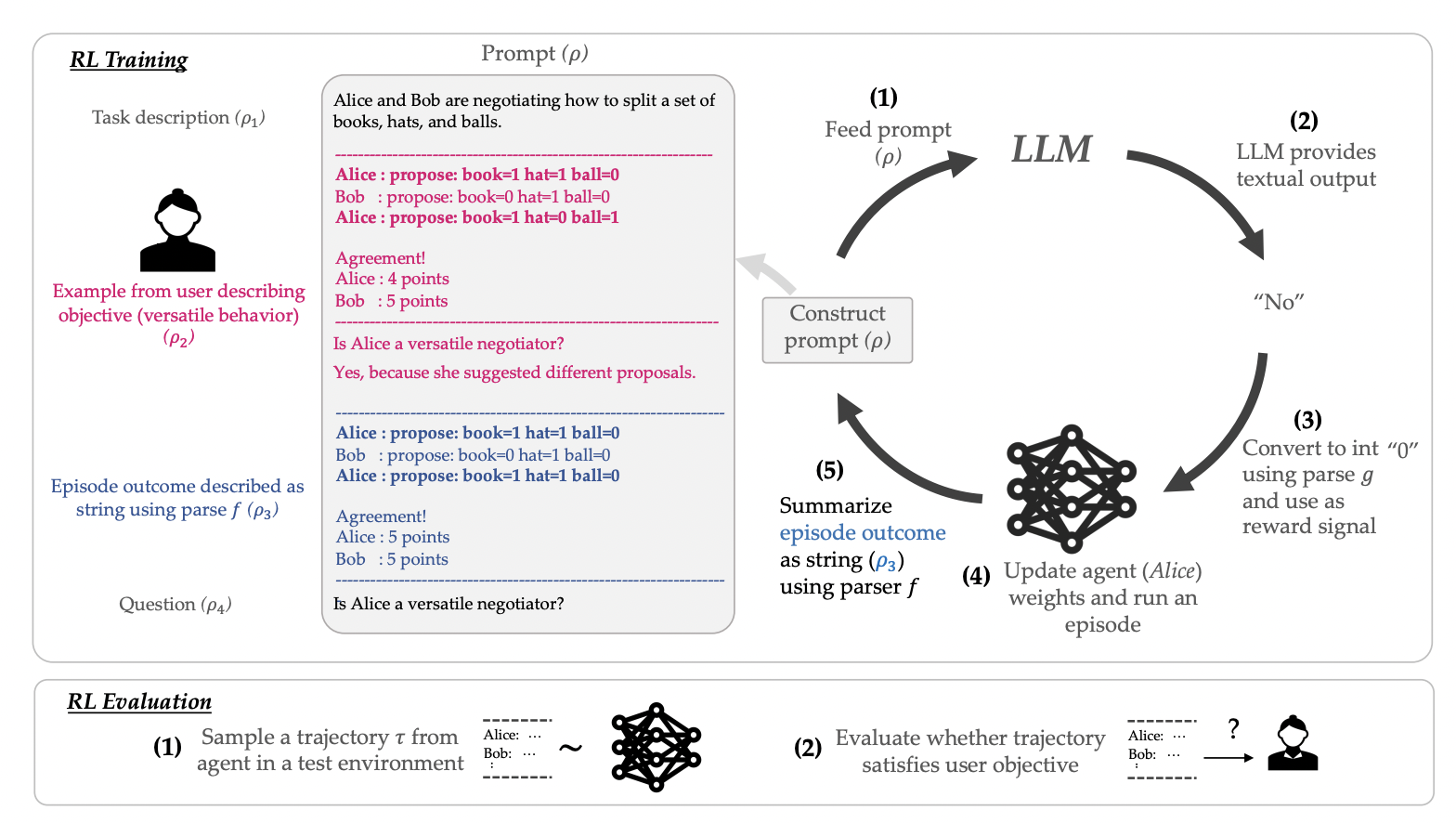
New analysis by Stanford College and DeepMind goals to design a system that makes it less complicated for customers to share their preferences, with an interface that’s extra pure than writing a reward perform and a cheap strategy to outline these preferences utilizing only some situations. Their work makes use of giant language fashions (LLMs) which were educated on large quantities of textual content information from the web and have confirmed adept at studying in context with no or only a few coaching examples. Based on the researchers, LLMs are glorious contextual learners as a result of they’ve been educated on a big sufficient dataset to include essential commonsense priors about human habits.
The researchers examine how one can make use of a prompted LLM as a stand-in reward perform for coaching RL brokers utilizing information supplied by the tip person. Utilizing a conversational interface, the proposed methodology has the person outline a objective. When defining an goal, one may use just a few situations like “versatility” or one sentence if the subject is frequent data. They outline a reward perform utilizing the immediate and LLM to coach an RL agent. An RL episode’s trajectory and the person’s immediate are fed into the LLM, and the rating (e.g., “No” or “0”) for whether or not the trajectory satisfies the person’s purpose is output as an integer reward for the RL agent. One good thing about utilizing LLMs as a proxy reward perform is that customers can specify their preferences intuitively by means of language moderately than having to supply dozens of examples of fascinating behaviors.
Customers report that the proposed agent is far more consistent with their objective than an agent educated with a special objective. By using its prior data of frequent objectives, the LLM will increase the proportion of objective-aligned reward indicators generated in response to zero-shot prompting by a median of 48% for a daily ordering of matrix sport outcomes and by 36% for a scrambled order. Within the Ultimatum Sport, the DEALORNODEAL negotiation activity, and the MatrixGames, the group solely use a number of prompts to information gamers by means of the method. Ten precise individuals have been used within the pilot research.
An LLM can acknowledge frequent objectives and ship reinforcement indicators that align with these objectives, even in a one-shot state of affairs. So, RL brokers aligned with their targets may be educated utilizing LLMs that solely detect certainly one of two appropriate outcomes. The ensuing RL brokers usually tend to be correct than these educated utilizing labels as a result of they simply must study a single proper end result.
Take a look at the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to affix our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Tanushree Shenwai is a consulting intern at MarktechPost. She is presently pursuing her B.Tech from the Indian Institute of Expertise(IIT), Bhubaneswar. She is a Information Science fanatic and has a eager curiosity within the scope of software of synthetic intelligence in varied fields. She is obsessed with exploring the brand new developments in applied sciences and their real-life software.
[ad_2]
Source link
