


[ad_1]
The State Area Mannequin taking up Transformers

Proper now, AI is consuming the world.
And by AI, I imply Transformers. Virtually all the massive breakthroughs in AI over the previous couple of years are because of Transformers.
Mamba, nonetheless, is certainly one of another class of fashions known as State Area Fashions (SSMs). Importantly, for the primary time, Mamba guarantees related efficiency (and crucially related scaling laws) because the Transformer while being possible at lengthy sequence lengths (say 1 million tokens). To realize this lengthy context, the Mamba authors take away the “quadratic bottleneck” within the Consideration Mechanism. Mamba additionally runs quick – like “as much as 5x sooner than Transformer quick”1.
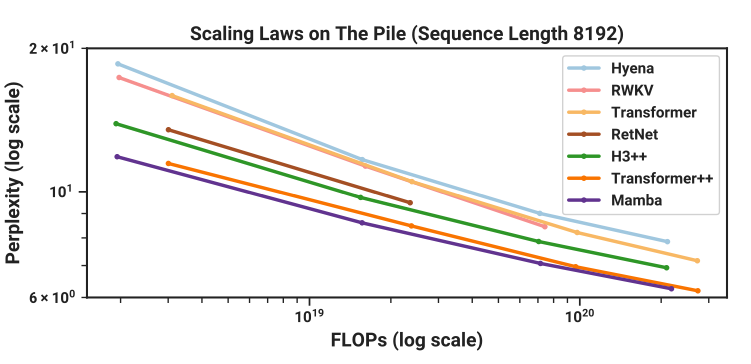
Gu and Dao, the Mamba authors write:
Mamba enjoys quick inference and linear scaling in sequence size, and its efficiency improves on actual knowledge as much as million-length sequences. As a basic sequence mannequin spine, Mamba achieves state-of-the-art efficiency throughout a number of modalities resembling language, audio, and genomics. On language modelling, our Mamba-3B mannequin outperforms Transformers of the identical dimension and matches Transformers twice its dimension, each in pretraining and downstream analysis.
Right here we’ll talk about:
- The benefits (and downsides) of Mamba (🐍) vs Transformers (🤖),
- Analogies and intuitions for desirous about Mamba, and
- What Mamba means for Interpretability, AI Security and Purposes.
Issues with Transformers – Possibly Consideration Isn’t All You Want
We’re very a lot within the Transformer-era of historical past. ML was once about detecting cats and canine. Now, with Transformers, we’re generating human-like poetry, coding better than the median competitive programmer, and solving the protein folding problem.
However Transformers have one core downside. In a transformer, each token can look again at each earlier token when making predictions. For this lookback, we cache detailed details about every token within the so-called KV cache.
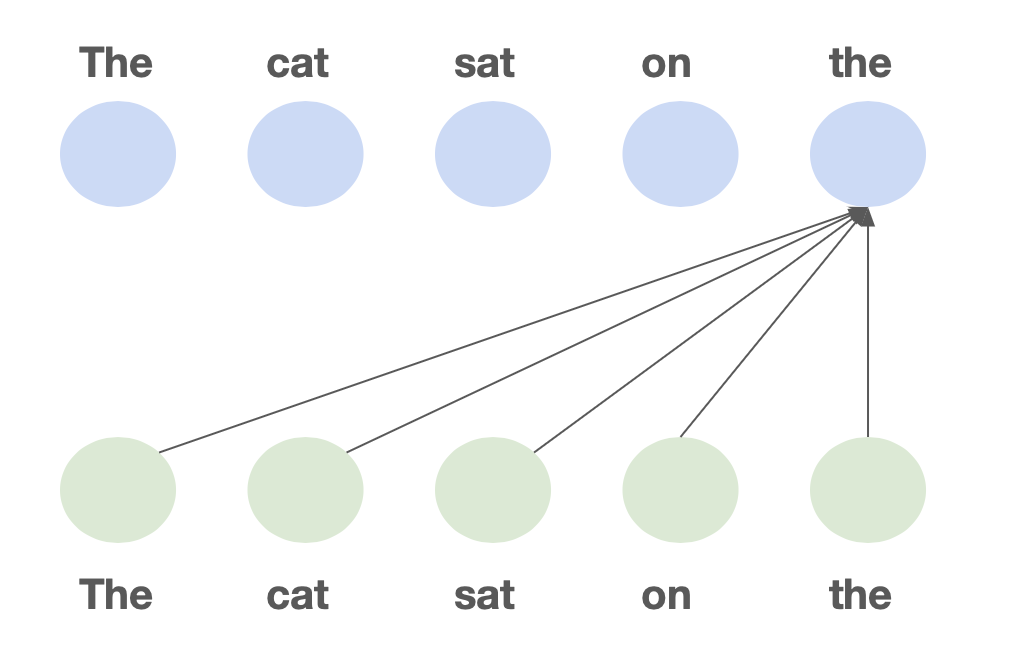
This pairwise communication means a ahead cross is O(n²) time complexity in coaching (the dreaded quadratic bottleneck), and every new token generated autoregressively takes O(n) time. In different phrases, because the context dimension will increase, the mannequin will get slower.
So as to add insult to damage, storing this key-value (KV) cache requires O(n) area. Consequently, the dreaded CUDA out-of-memory (OOM) error turns into a big risk because the reminiscence footprint expands. If area have been the one concern, we’d take into account including extra GPUs; nonetheless, with latency rising quadratically, merely including extra compute may not be a viable answer.
On the margin, we will mitigate the quadratic bottleneck with strategies like Sliding Window Attention or intelligent CUDA optimisations like FlashAttention. However finally, for tremendous lengthy context home windows (like a chatbot which remembers each dialog you’ve shared), we want a unique strategy.
Basis Mannequin Backbones
Basically, all good ML structure backbones have elements for 2 vital operations:
- Communication between tokens
- Computation inside a token
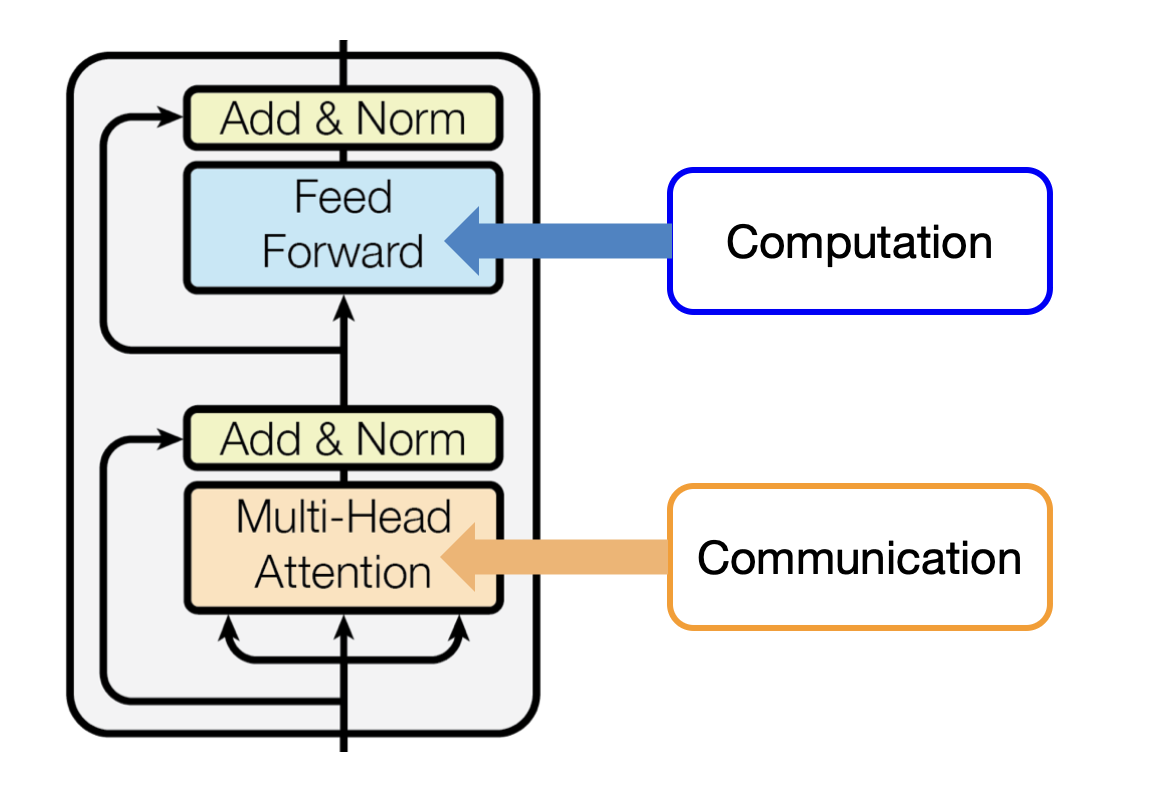
In transformers, that is Consideration (communication) and MLPs (computation). We enhance transformers by optimising these two operations2.
We want to substitute the Consideration element3 with another mechanism for facilitating inter-token communication. Particularly, Mamba employs a Management Idea-inspired State Area Mannequin, or SSM, for Communication functions whereas retaining Multilayer Perceptron (MLP)-style projections for Computation.

Like a Transformer made up of stacked transformer blocks, Mamba is made up of stacked Mamba blocks as above.
We want to perceive and encourage the selection of the SSM for sequence transformations.
Motivating Mamba – A Throwback to Temple Run
Think about we’re constructing a Temple Run agent4. It chooses if the runner ought to transfer left or proper at any time.

To efficiently choose the right route, we want details about our environment. Let’s name the gathering of related data the state. Right here the state doubtless contains your present place and velocity, the place of the closest impediment, climate situations, and so on.
Declare 1: if you already know the present state of the world and the way the world is evolving, then you should use this to find out the route to maneuver.
Notice that you just don’t want to take a look at the entire display screen on a regular basis. You possibly can work out what’s going to occur to many of the display screen by noting that as you run, the obstacles transfer down the display screen. You solely want to take a look at the highest of the display screen to grasp the brand new data after which simulate the remainder.
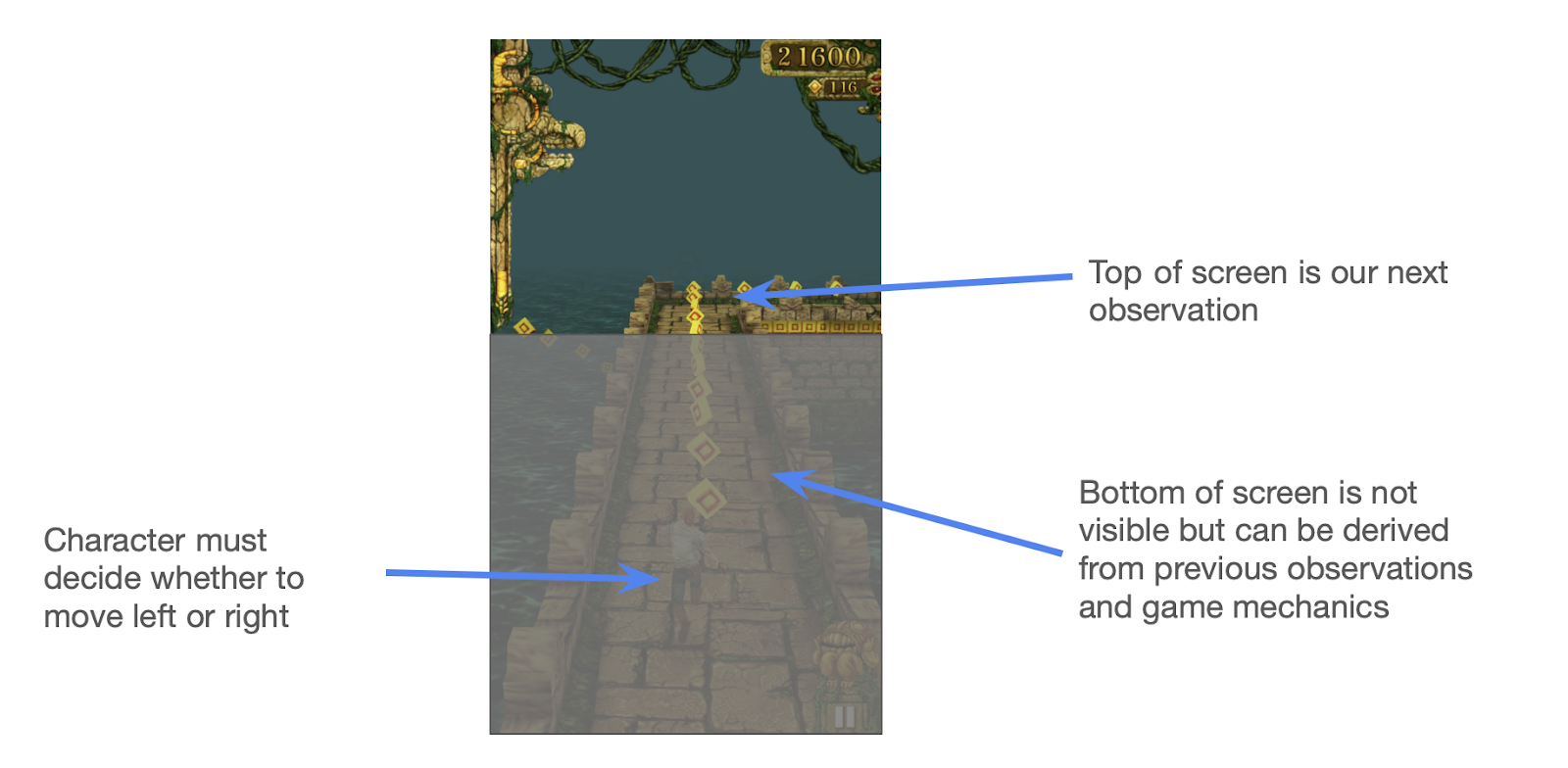
This lends itself to a pure formulation. Let h be the hidden state, related data in regards to the world. Additionally let x be the enter, the remark that you just get every time. h’ then represents the spinoff of the hidden state, i.e. how the state is evolving. We’re making an attempt to foretell y, the optimum subsequent transfer (proper or left).
Now, Declare 1 states that from the hidden state h, h’, and the brand new remark x, you possibly can work out y.
Extra concretely, h, the state, could be represented as a differential equation (Eq 1a):
$h’(t) = mathbf{A}h(t) + mathbf{B}x(t)$
Realizing h permits you to decide your subsequent transfer y (Eq 1b):
$y(t) = mathbf{C}h(t) + mathbf{D}x(t)$
The system’s evolution is set by its present state and newly acquired observations. A small new remark is sufficient, as nearly all of the state could be inferred by making use of identified state dynamics to its earlier state. That’s, many of the display screen isn’t new, it’s only a continuation of the earlier state’s pure downward trajectory. A full understanding of the state would allow optimum number of the next motion, denoted as y.
You possibly can study so much in regards to the system dynamics by observing the highest of the display screen. As an example, elevated velocity of this higher part suggests an acceleration of the remainder of the display screen as effectively, so we will infer that the sport is dashing up5. On this manner, even when we begin off realizing nothing in regards to the recreation and solely have restricted observations, it turns into attainable to realize a holistic understanding of the display screen dynamics pretty quickly.
What’s the State?
Right here, state refers back to the variables that, when mixed with the enter variables, totally decide the long run system behaviour. In principle, as soon as we’ve got the state, there’s nothing else we have to know in regards to the previous to foretell the long run. With this selection of state, the system is transformed to a Markov Determination Course of. Ideally, the state is a reasonably small quantity of data which captures the important properties of the system. That’s, the state is a compression of the previous6.
Discretisation – How To Deal With Dwelling in a Quantised World
Okay, nice! So, given some state and enter remark, we’ve got an autoregressive-style system to find out the subsequent motion. Wonderful!
In follow although, there’s somewhat snag right here. We’re modelling time as steady. However in actual life, we get new inputs and take new actions at discrete time steps7.

We want to convert this continuous-time differential equation right into a discrete-time distinction equation. This conversion course of is called discretisation. Discretisation is a well-studied downside within the literature. Mamba makes use of the Zero-Order Hold (ZOH) discretisation8. To provide an thought of what’s occurring morally, take into account a naive first-order approximation9.
From Equation 1a, we’ve got
$h’(t) = mathbf{A}h(t) + mathbf{B}x(t)$
And for small ∆,
$h’(t) approx frac{h(t+Delta) – h(t)}{Delta}$
by the definition of the spinoff.
We let:
$h_t = h(t)$
and
$h_{t+1} = h(t + Delta)$
and substitute into Equation 1a giving:
$h_{t+1} – h_t approx Delta (mathbf{A}h_t + mathbf{B}x_t)$
$Rightarrow h_{t+1} approx (I + Delta mathbf{A})h_t + (Delta
mathbf{B})x_t$
Therefore, after renaming the coefficients and relabelling indices, we’ve got the discrete representations:
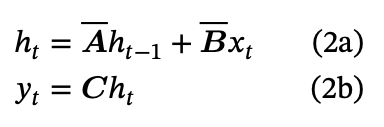
In case you’ve ever checked out an RNN earlier than10 and this feels acquainted – belief your instincts:
We have now some enter x, which is mixed with the earlier hidden state by some rework to present the brand new hidden state. Then we use the hidden state to calculate the output at every time step.
Understanding the SSM Matrices
Now, we will interpret the A, B, C, D matrices extra intuitively:
- A is the transition state matrix. It reveals the way you transition the present state into the subsequent state. It asks “How ought to I neglect the much less related components of the state over time?”
- B is mapping the brand new enter into the state, asking “What a part of my new enter ought to I bear in mind?”11
- C is mapping the state to the output of the SSM. It asks, “How can I exploit the state to make a great subsequent prediction?”12
- D is how the brand new enter passes by way of to the output. It’s a type of modified skip connection that asks “How can I exploit the brand new enter in my prediction?”
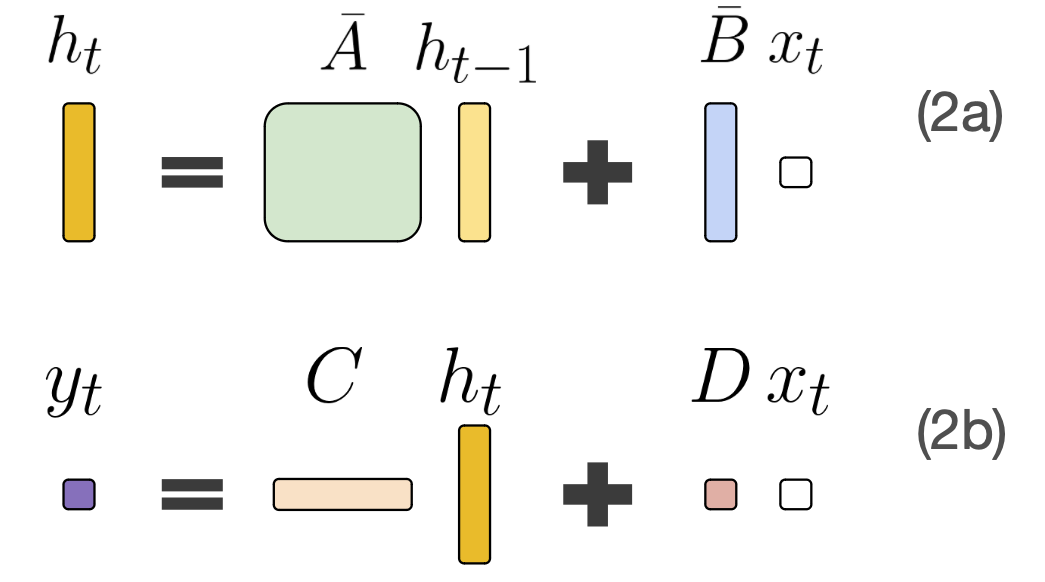
Moreover, ∆ has a pleasant interpretation – it’s the step dimension, or what we’d name the linger time or the dwell time. For big ∆, you focus extra on that token; for small ∆, you skip previous the token instantly and don’t embody it a lot within the subsequent state.
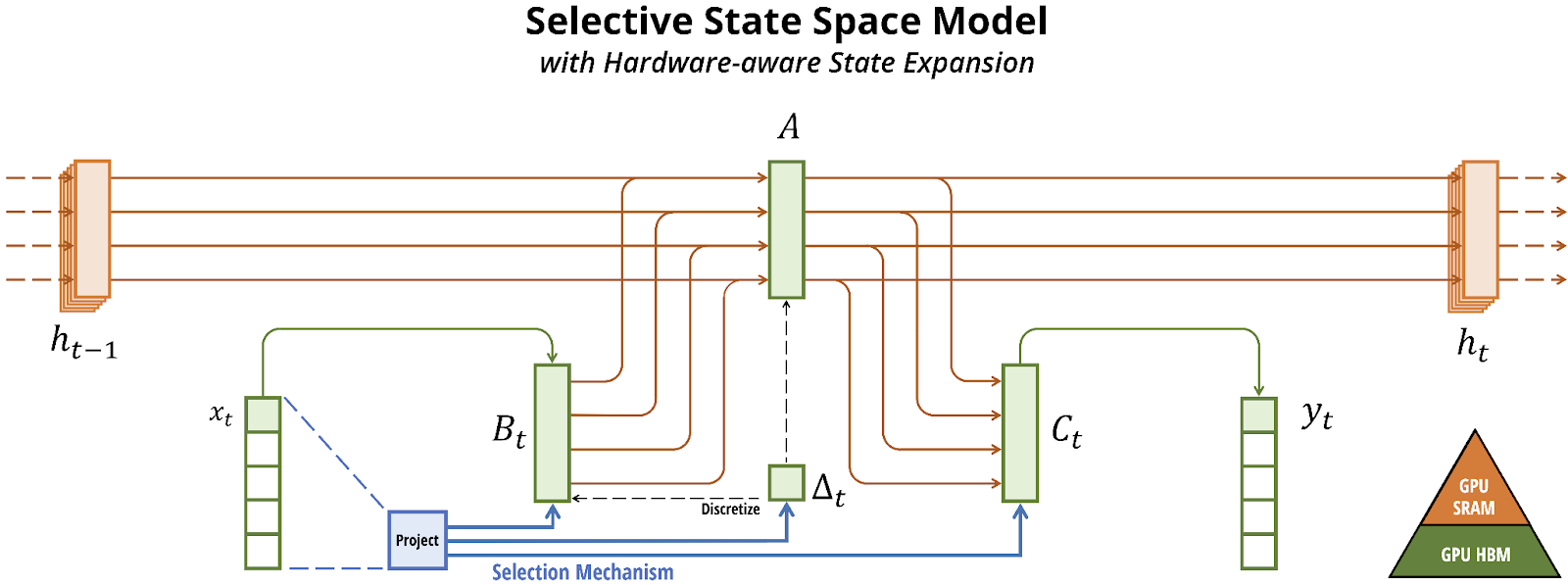
And that’s it! That’s the SSM, our ~drop-in alternative for Consideration (Communication) within the Mamba block. The Computation within the Mamba structure comes from common linear projections, non-linearities, and native convolutions.
Okay nice, that’s the speculation – however does this work? Properly…
Effectiveness vs Effectivity: Consideration is Focus, Selectivity is Prioritisation
At WWDC ‘97, Steve Jobs famously famous that “focusing is about saying no”. Focus is ruthless prioritisation. It’s frequent to consider Consideration positively as selecting what to discover. Within the Steve Jobs sense, we’d as an alternative body Consideration negatively as selecting what to discard.
There’s a basic instinct pump in Machine Studying referred to as the Cocktail Social gathering Downside13. Think about a celebration with dozens of simultaneous loud conversations:
Query:
How can we recognise what one particular person is saying when others are speaking on the identical time?14
Reply:
The mind solves this downside by focusing your “consideration” on a selected stimulus and therefore drowning out all different sounds as a lot as attainable.

Transformers use Dot-Product Consideration to give attention to probably the most related tokens. An enormous cause Consideration is so nice is that you’ve got the potential to look again at every little thing that ever occurred in its context. That is like photographic reminiscence when achieved proper.15
Transformers (🤖) are extraordinarily efficient. However they aren’t very environment friendly. They retailer every little thing from the previous in order that they will look again at tokens with theoretically good recall.
Conventional RNNs (🔁) are the other – they neglect so much, solely recalling a small quantity of their hidden state and discarding the remainder. They’re very environment friendly – their state is small. But they’re much less efficient as discarded data can’t be recovered.
We’d like one thing nearer to the Pareto frontier of the effectiveness/effectivity tradeoff. One thing that’s simpler than conventional RNNs and extra environment friendly than transformers.
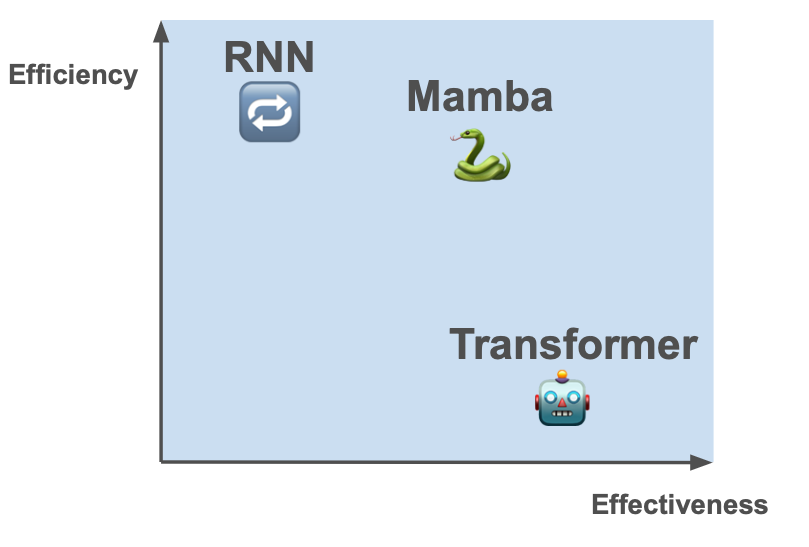
The Mamba Structure appears to supply an answer which pushes out the Pareto frontier of effectiveness/effectivity.
SSMs are as environment friendly as RNNs, however we’d marvel how efficient they’re. In spite of everything, it looks like they might have a tough time discarding solely pointless data and holding every little thing related. If every token is being processed the identical manner, making use of the identical A and B matrices as if in a manufacturing unit meeting line for tokens, there isn’t a context-dependence. We wish the forgetting and remembering matrices (A and B respectively) to differ and dynamically adapt to inputs.
The Choice Mechanism
Selectivity permits every token to be reworked into the state in a manner that’s distinctive to its personal wants. Selectivity is what takes us from vanilla SSM fashions (making use of the identical A (forgetting) and B (remembering) matrices to each enter) to Mamba, the Selective State Area Mannequin.
In common SSMs, A, B, C and D are realized matrices – that’s
$mathbf{A} = mathbf{A}_{theta}$ and so on. (the place θ represents the realized parameters)
With the Choice Mechanism in Mamba, A, B, C and D are additionally features of x. That’s $mathbf{A} = mathbf{A}_{theta(x)}$ and so on; the matrices are context dependent relatively than static.

Making A and B features of x permits us to get one of the best of each worlds:
- We’re selective about what we embody within the state, which improves effectiveness vs conventional SSMs.
- But, because the state dimension is bounded, we enhance on effectivity relative to the Transformer. We have now O(1), not O(n) area and O(n) not O(n²) time necessities.
The Mamba paper authors write:
The effectivity vs. effectiveness tradeoff of sequence fashions is characterised by how effectively they compress their state: environment friendly fashions should have a small state, whereas efficient fashions should have a state that incorporates all vital data from the context. In flip, we suggest {that a} basic precept for constructing sequence fashions is selectivity: or the context-aware potential to give attention to or filter out inputs right into a sequential state. Particularly, a variety mechanism controls how data propagates or interacts alongside the sequence dimension.
People (largely) don’t have photographic reminiscence for every little thing they expertise inside a lifetime – and even inside a day! There’s simply manner an excessive amount of data to retain all of it. Subconsciously, we choose what to recollect by selecting to neglect, throwing away most data as we encounter it. Transformers (🤖) determine what to give attention to at recall time. People (🧑) additionally determine what to throw away at memory-making time. People filter out data early and sometimes.
If we had infinite capability for memorisation, it’s clear the transformer strategy is healthier than the human strategy – it actually is simpler. However it’s much less environment friendly – transformers should retailer a lot details about the previous that may not be related. Transformers (🤖) solely determine what’s related at recall time. The innovation of Mamba (🐍) is permitting the mannequin higher methods of forgetting earlier – it’s focusing by selecting what to discard utilizing Selectivity, throwing away much less related data at memory-making time16.
The Issues of Selectivity
Making use of the Choice Mechanism does have its gotchas although. Non-selective SSMs (i.e. A,B not depending on x) are quick to compute in coaching. It is because the element of
Yt which will depend on xi could be expressed as a linear map, i.e. a single matrix that may be precomputed!
For instance (ignoring the D element, the skip connection):
$$y_2 = mathbf{C}mathbf{B}x_2 + mathbf{C}mathbf{A}mathbf{B}x_1 +
mathbf{C}mathbf{A}mathbf{A}mathbf{B}x_0$$
If we’re paying consideration, we’d spot one thing even higher right here – this expression could be written as a convolution. Therefore we will apply the Quick Fourier Remodel and the Convolution Theorem to compute this very effectively on {hardware} as in Equation 3 under.
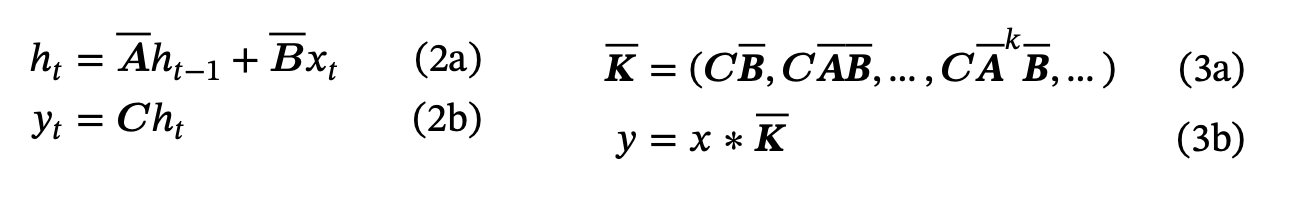
We are able to calculate Equation 2, the SSM equations, effectively within the Convolutional Type, Equation 3.
Sadly, with the Choice Mechanism, we lose the convolutional kind. A lot consideration is given to creating Mamba environment friendly on fashionable GPU {hardware} utilizing related {hardware} optimisation methods to Tri Dao’s Flash Consideration17. With the {hardware} optimisations, Mamba is ready to run sooner than comparably sized Transformers.
Machine Studying for Political Economists – How Massive Ought to The State Be?
The Mamba authors write, “the effectivity vs. effectiveness tradeoff of sequence fashions is characterised by how effectively they compress their state”. In different phrases, like in political financial system18, the elemental downside is methods to handle the state.
🔁 Conventional RNNs are anarchic
They’ve a small, minimal state. The dimensions of the state is bounded. The compression of state is poor.
🤖 Transformers are communist
They’ve a maximally giant state. The “state” is only a cache of your complete historical past with no compression. Each context token is handled equally till recall time.
🐍Mamba has a compressed state
…however it’s selective about what goes in. Mamba says we will get away with a small state if the state is effectively targeted and efficient19.
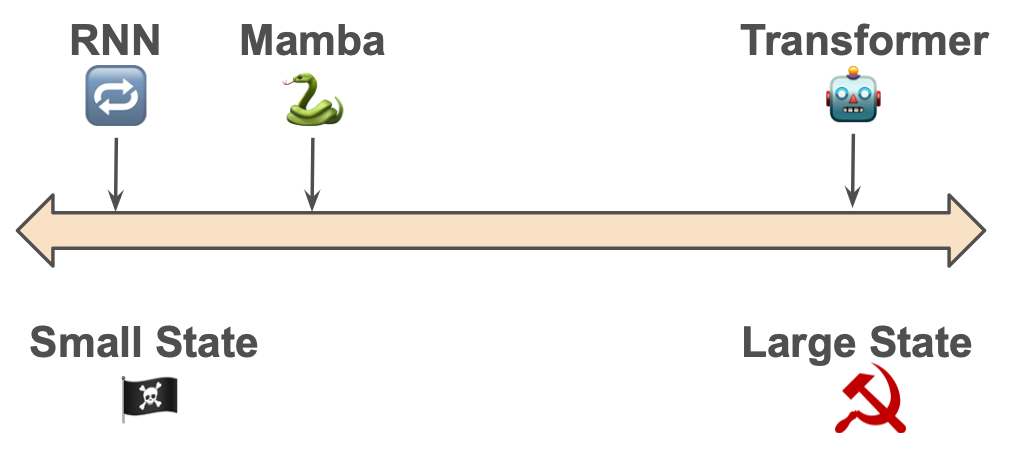
The upshot is that state illustration is vital. A smaller state is extra environment friendly; a bigger state is simpler. The hot button is to selectively and dynamically compress knowledge into the state. Mamba’s Choice Mechanism permits for context-dependent reasoning, focusing and ignoring. For each efficiency and interpretability, understanding the state appears to be very helpful.
Info Stream in Transformer vs Mamba
How do Transformers know something? At initialization, a transformer isn’t very good. It learns in two methods:
- Coaching knowledge (Pretraining, SFT, RLHF and so on)
- In context-data
Coaching Knowledge
Fashions study from their coaching knowledge. This can be a type of lossy compression of enter knowledge into the weights. We are able to consider the impact of pretraining knowledge on the transformer kinda just like the impact of your ancestor’s experiences in your genetics – you possibly can’t recall their experiences, you simply have imprecise instincts about them20.
In Context-Knowledge
Transformers use their context as short-term reminiscence, which they will recall with ~good constancy. So we get In-Context Learning, e.g. utilizing induction heads to resolve the Indirect Object Identification process, or computing Linear Regression.
Retrieval
Notice that Transformers don’t filter their context in any respect till recall time. So if we’ve got a bunch of data we predict would possibly be helpful to the Transformer, we filter it exterior the Transformer (utilizing Info Retrieval methods) after which stuff the outcomes into the immediate. This course of is called Retrieval Augmented Technology (RAG). RAG determines related data for the context window of a transformer. A human with the web is kinda like a RAG system – you continue to should know what to look however no matter you retrieve is as salient as short-term reminiscence to you.
Info Stream for Mamba
Coaching Knowledge acts equally for Mamba. Nonetheless, the strains are barely blurred for in-context knowledge and retrieval. In-context knowledge for Mamba is compressed/filtered just like retrieval knowledge for transformers. This in-context knowledge can be accessible for look-up like for transformers (though with considerably decrease constancy).

Transformer context is to Mamba states what short-term is to long-term reminiscence. Mamba doesn’t simply have “RAM”, it has a tough drive21 22.
Swapping States as a New Prompting Paradigm
At the moment, we regularly use RAG to present a transformer contextual data.
With Mamba-like fashions, you could possibly as an alternative think about having a library of states created by operating the mannequin over specialised knowledge. States may very well be shared kinda like LoRAs for picture fashions.
For instance, I may do inference on 20 physics textbooks and, say, 100 physics questions and solutions. Then I’ve a state which I can provide to you. Now you don’t want so as to add any few-shot examples; you simply merely ask your query. The in-context studying is within the state.
In different phrases, you possibly can drag and drop downloaded states into your mannequin, like literal plug-in cartridges. And observe that “coaching” a state doesn’t require any backprop. It’s extra like a extremely specialised one-pass fixed-size compression algorithm. That is limitless in-context studying utilized at inference time for zero-compute or latency23.
The construction of an efficient LLM name goes from…
- System Immediate
- Preamble
- Few shot-examples
- Query
…for Transformers, to easily…
- Inputted state (with downside context, preliminary directions, textbooks, and few-shot examples)
- Quick query
…for Mamba.
That is cheaper and sooner than few-shot prompting (because the state is infinitely reusable with out inference value). It’s additionally MUCH cheaper than finetuning and doesn’t require any gradient updates. We may think about retrieving states along with context.
Mamba & Mechanistic Interpretability
Transformer interpretability usually entails:
- understanding token relationships by way of consideration,
- understanding circuits, and
- utilizing Dictionary Learning for unfolding MLPs.
Many of the ablations that we want to do for Mamba are nonetheless legitimate, however understanding token communication (1) is now extra nuanced. All data strikes between tokens by way of hidden states as an alternative of the Consideration Mechanism which might “teleport” data from one sequence place to a different.
For understanding in-context studying (ICL) duties with Mamba, we are going to look to intervene on the SSM state. A basic process in-context studying process is Indirect Object Identification wherein a mannequin has to complete a paragraph like:
Then, Shelby and Emma had quite a lot of enjoyable on the college. [Shelby/Emma] gave an apple to [BLANK]
The mannequin is predicted to fill within the clean with the title that’s not repeated within the paragraph. Within the chart under we will see that data is handed from the [Shelby/Emma] place to the ultimate place by way of the hidden state (see the 2 blue strains within the prime chart).
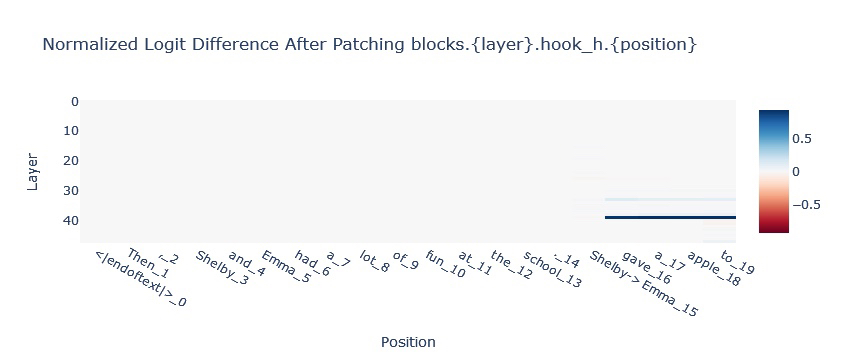
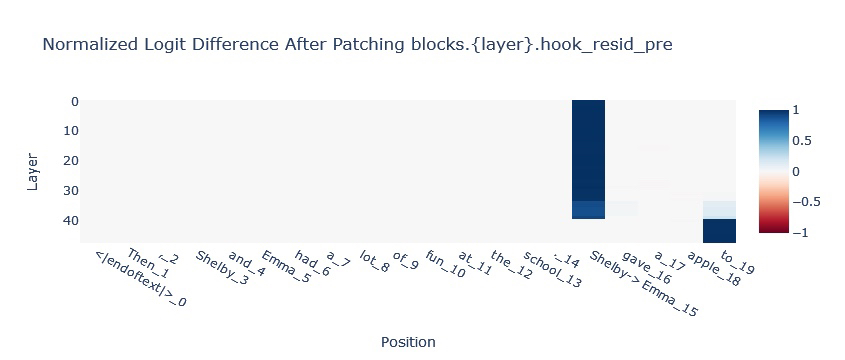
Because it’s hypothesised that a lot of In-Context Studying in Transformers is downstream of extra primitive sequence place operations (like Induction Heads), Mamba with the ability to full this process suggests a extra basic In-Context Studying potential.
What’s Subsequent for Mamba & SSMs?
Mamba-like fashions are more likely to excel in eventualities requiring extraordinarily lengthy context and long-term reminiscence. Examples embody:
- Processing DNA
- Producing (or reasoning over) video
- Writing novels
An illustrative instance is brokers with long-term objectives.
Suppose you could have an agent interacting with the world. Ultimately, its experiences turn out to be an excessive amount of for the context window of a transformer. The agent then has to compress or summarise its experiences into some extra compact illustration.
However how do you determine what data is probably the most helpful as a abstract? If the duty is language, LLMs are literally pretty good at summaries – okay, yeah, you’ll lose some data, however crucial stuff could be retained.
Nonetheless, for different disciplines, it may not be clear methods to summarise. For instance, what’s one of the simplest ways to summarise a 2 hour film?24. Might the mannequin itself study to do that naturally relatively than a hacky workaround like making an attempt to explain the aesthetics of the film in textual content?
That is what Mamba permits. Precise long-term reminiscence. An actual state the place the mannequin learns to maintain what’s vital. Prediction is compression – studying what’s helpful to foretell what’s coming subsequent inevitably results in constructing a helpful compression of the earlier tokens.
The implications for Assistants are clear:
Your chatbot co-evolves with you. It remembers.

The movie HER is wanting higher and higher as time goes on 😳
Brokers & AI Security
One cause for optimistic updates in existential danger from AGI is Language Fashions. Beforehand, Deep-RL brokers skilled by way of self-play seemed set to be the primary AGIs. Language fashions are inherently a lot safer since they aren’t skilled with long-term objectives25.
The potential for long-term sequence reasoning right here brings again the significance of agent-based AI security. Few agent worries are related to Transformers with an 8k context window. Many are related to methods with spectacular long-term reminiscences and attainable instrumental objectives.
The Greatest Collab Since Taco Bell & KFC: 🤖 x 🐍
The Mamba authors present that there’s worth in combining Mamba’s lengthy context with the Transformer’s excessive constancy over quick sequences. For instance, if you happen to’re making lengthy movies, you doubtless can’t match a complete film right into a Transformer’s context for consideration26. You would think about having Consideration have a look at the newest frames for short-term fluidity and an SSM for long-term narrative consistency27.
This isn’t the tip for Transformers. Their excessive effectiveness is precisely what’s wanted for a lot of duties. However now Transformers aren’t the one choice. Different architectures are genuinely possible.
So we’re not within the post-Transformer period. However for the primary time, we’re residing within the post-only-Transformers period28. And this blows the probabilities broad open for sequence modelling with excessive context lengths and native long-term reminiscence.
Two ML researchers, Sasha Rush (HuggingFace, Annotated Transformer, Cornell Professor) and Jonathan Frankle (Lottery Ticket Speculation, MosaicML, Harvard Professor), presently have a wager here.
At the moment Transformers are far and away within the lead. With 3 years left, there’s now a analysis route with a preventing likelihood.
All that continues to be to ask is: Is Consideration All We Want?
1. see Determine 8 within the Mamba paper.
2. And scaling up with huge compute.
3. Extra particularly the scaled dot-product Consideration popularised by Transformers
4. For individuals who don’t see Temple Run because the cultural cornerstone it’s 🤣 Temple Run was an iPhone recreation from 2011 just like Subway Surfer
5. Right here we assume the surroundings is sufficiently clean.
6. One fairly vital constraint for this to be environment friendly is that we don’t enable the person parts of the state vector to work together with one another immediately. We’ll use a mixture of the state dimensions to find out the output however we don’t e.g. enable the rate of the runner and the route of the closest impediment (or no matter else was in our state) to immediately work together. This helps with environment friendly computation and we obtain this virtually by constraining A to be a diagonal matrix.
7. Concretely take into account the case of Language Fashions – every token is a discrete step
8. ZOH additionally has good properties for the initialisations – we wish A_bar to be near the id in order that the state could be largely maintained from timestep to timestep if desired. ZOH provides A_bar as an exponential so any diagonal aspect initialisations near zero give values near 1
9. This is called the Euler discretisation within the literature
10. It’s wild to notice that some readers may not have, we’re to date into the age of Consideration that RNNs have been forgotten!
11. B is just like the Question (Q) matrix for Transformers.
12. C is just like the Output (O) matrix for Transformers.
13. Non-alcoholic choices additionally accessible!
14. Particularly as all voices roughly occupy the identical area on the audio frequency spectrum Intuitively this appears actually exhausting!
15. Notice that photographic reminiscence doesn’t essentially suggest good inferences from that reminiscence!
16. To be clear, you probably have a brief sequence, then a transformer ought to theoretically be a greater strategy. In case you can retailer the entire context, then why not!? When you’ve got sufficient reminiscence for a high-resolution picture, why compress it right into a JPEG? However Mamba-style architectures are more likely to vastly outperform with long-range sequences.
17. Extra particulars can be found for engineers enthusiastic about CUDA programming – Tri’s speak, Mamba paper part 3.3.2, and the official CUDA code are good sources for understanding the {Hardware}-Conscious Scan
18. or in Object Oriented Programming
19. Implications to precise Political Economic system are left to the reader however possibly Gu and Dao by accident solved politics!?
20. This isn’t an ideal analogy as human evolution follows a genetic algorithm relatively than SGD.
21. Albeit a reasonably bizarre exhausting drive at that – it morphs over time relatively than being a set illustration.
22. As a backronym, I’ve began calling the hidden_state the state area dimension (or selective state dimension) which shortens to SSD, a pleasant reminder for what this object represents – the long-term reminiscence of the system.
23. I’m desirous about this equally to the connection between harmlessness finetuning and activation steering. State swapping, like activation steering, is an inference time intervention giving comparable outcomes to its practice time analogue.
24. This can be a very non-trivial downside! How do human brains signify a film internally? It’s not a collection of probably the most salient frames, neither is it a textual content abstract of the colors, neither is it a purely vibes-based abstract if you happen to can memorise some strains of the movie.
25. They’re additionally safer since they inherently perceive (although don’t essentially embody) human values. It’s not all clear that methods to train an RL agent human morality.
26. Notice that usually a picture (i.e. a single body) counts as >196 tokens, and flicks are usually 24 fps so that you’ll fill a 32k context window in 7 seconds 🤯
27. One other risk that I’m enthusiastic about is making use of optimisation stress to the state itself in addition to the output to have fashions that respect specific use instances.
28. That is barely hyperbolic, the TS-Mixer for time collection, Gradient Boosting Timber for tabular knowledge and Graph Neural Networks for climate prediction exist and are presently used, however these aren’t on the core of AI
Writer Bio
Kola Ayonrinde is a Analysis Scientist and Machine Studying Engineer with a aptitude for writing. He integrates know-how and creativity, specializing in making use of machine studying in revolutionary methods and exploring the societal impacts of tech developments.
Acknowledgements
This submit was initially posted on Kola’s personal blog.
Because of Gonçalo for studying an early draft, Jaden for the nnsight library used for the Interpretability evaluation and Tessa for Mamba patching visualisations.Additionally see: Mamba paper, Mamba Python code, Annotated S4, Nathan Labenz podcast
Quotation
For attribution in educational contexts or books, please cite this work as
Kola Ayonrinde, "Mamba Defined," The Gradient, 2024@article{Ayonrinde2024mamba,
writer = {Kola Ayonrinde},
title = {Mamba Defined},
journal = {The Gradient},
12 months = {2024},
howpublished = {url{https://thegradient.pub/mamba-explained},
}[ad_2]
Source link
