

[ad_1]
The largest development within the subject of Synthetic Intelligence is the introduction of Massive Language Fashions (LLMs). These Pure Language Processing (NLP) based mostly fashions deal with giant and complex datasets, which causes them to face a singular problem within the finance trade. The fields of economic textual content summarisation, inventory value prediction, monetary report manufacturing, information sentiment evaluation, and monetary occasion extraction have all seen developments in conventional monetary NLP fashions.
As the quantity and complexity of economic information preserve rising, LLMs encounter a lot of challenges, together with the dearth of human-labeled information, the lack of awareness explicit to finance, the issue of multitasking, the constraints of numerical computing, and the incapacity to deal with real-time info. LLMs like GPT-4 are famend for his or her robust dialogue talents, command comprehension, and capability for following instructions.
Nonetheless, in industries just like the Chinese language monetary market, LLMs lack an in-depth understanding of the monetary trade, which makes the event of open-source Chinese language monetary LLMs which might be appropriate for a spread of person sorts and situational settings essential. To deal with the difficulty, a staff of researchers has launched DISC-FinLLM, a complete strategy for creating Chinese language monetary LLMs.
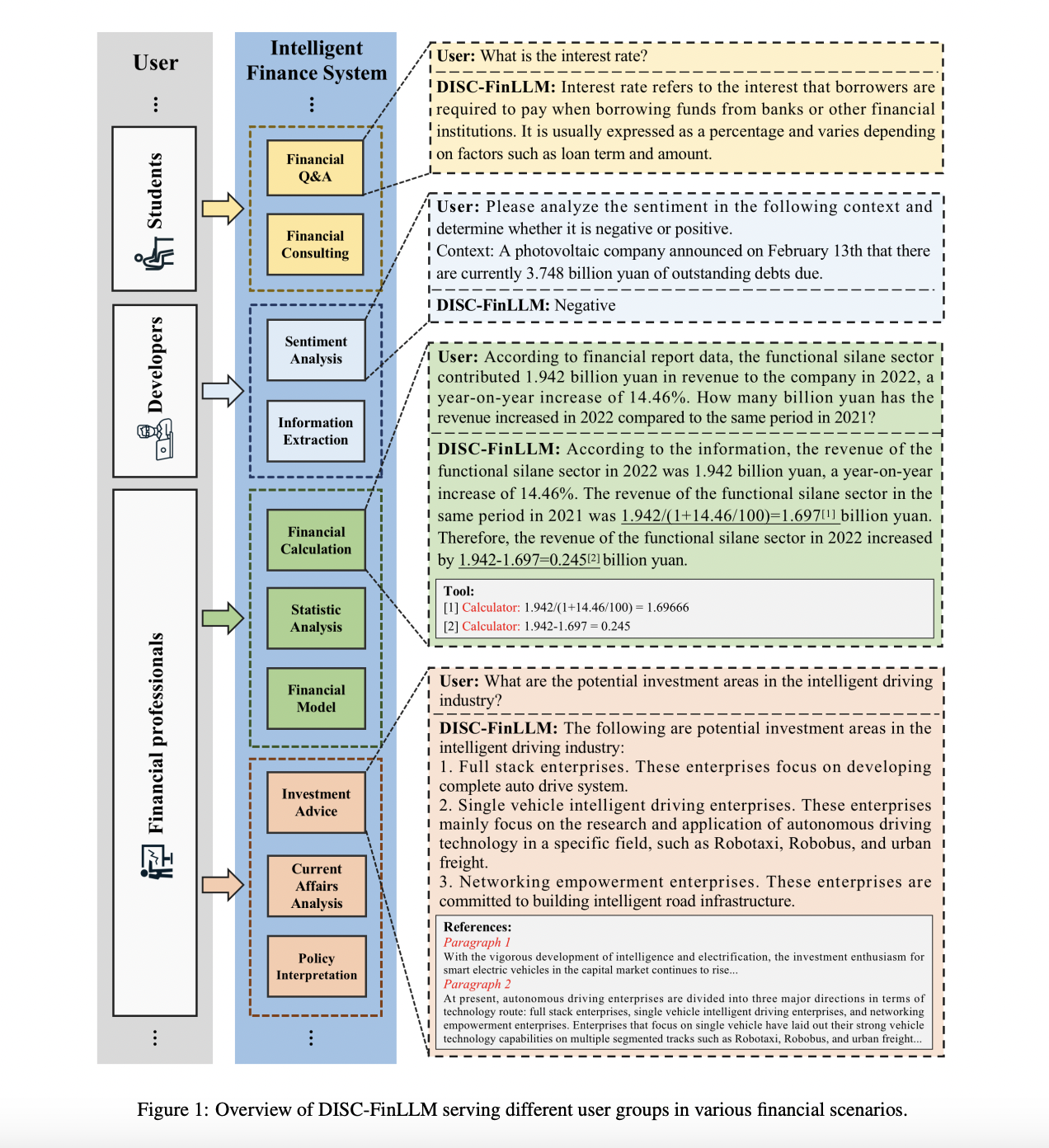
The primary goal of this technique is to supply the LLMs with the ability by which they achieve the flexibility to generate and comprehend monetary textual content, have multi-turn conversations about monetary points, and help monetary modeling and knowledge-enhanced techniques by means of plugin performance. The staff has additionally developed a supervised instruction dataset often known as DISC-FIN-SFT. This dataset’s main classes are as follows.
- Monetary Consulting Directions: These directions have been developed from on-line monetary boards and monetary Q&A datasets. They goal to reply inquiries and provide steering on monetary issues.
- Monetary Process Directions: These directions are supposed to assist with a wide range of monetary chores. They’re drawn from each self-constructed and accessible NLP datasets.
- Directions on Monetary Computing: The options to monetary statistical, computational, and modeling points are the primary topic of those directions.
- Retrieval- enhanced Directions: These directions make data retrieval simpler. They’ve been constructed from monetary texts and embody created questions, retrieved references, and generated solutions.
The staff has shared that the DISC-FIN-SFT instruction dataset is the idea for the development of DISC-FinLLM, which has been constructed utilizing a A number of Consultants Tremendous-tuning Framework (MEFF). 4 distinct Low-rank adaptation (LoRA) modules have been educated utilizing 4 totally different dataset segments. Monetary multi-round dialogues, monetary NLP jobs, monetary computations, and retrieval query responses are only a few of the monetary situations that these modules are made to accommodate. This allows the system to supply varied providers to related person teams, like college students, builders, and monetary professionals. On this explicit model, the inspiration of DISC-FinLLM is Baichuan-13B, a common area LLM for the Chinese language language.
The researchers have performed a number of evaluation benchmarks for evaluating DISC-FinLLM’s. The experimental outcomes have proven that DISC-FinLLM performs higher than the bottom basis mannequin in all downstream duties. A better look reveals the advantages of the MEFF structure, which makes it attainable for the mannequin to carry out nicely in a spread of economic situations and jobs.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to hitch our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.
Tanya Malhotra is a last 12 months undergrad from the College of Petroleum & Vitality Research, Dehradun, pursuing BTech in Laptop Science Engineering with a specialization in Synthetic Intelligence and Machine Studying.
She is a Information Science fanatic with good analytical and demanding considering, together with an ardent curiosity in buying new expertise, main teams, and managing work in an organized method.
[ad_2]
Source link
