

[ad_1]
The NLP neighborhood has not too long ago found that pretrained language fashions might accomplish varied real-world actions with the assistance of minor changes or direct help. Moreover, efficiency normally turns into higher as the dimensions grows. Fashionable language fashions typically embody a whole lot of billions of parameters, persevering with this pattern. A number of analysis teams revealed pretrained LLMs with greater than 100B parameters. The BigScience challenge most not too long ago made BLOOM out there, a 176 billion parameter mannequin that helps 46 pure and 13 laptop languages. The general public availability of 100B+ parameter fashions makes them extra accessible, but as a result of reminiscence and computational bills, most teachers and practitioners nonetheless discover it difficult to make use of them. For inference, OPT-175B and BLOOM-176B require greater than 350GB of accelerator RAM and much more for finetuning.
Consequently, working these LLMs sometimes requires a number of highly effective GPUs or multi-node clusters. These two options are comparatively cheap, proscribing the potential examine subjects and language mannequin purposes. By “offloading” mannequin parameters to slower however extra inexpensive reminiscence and executing them on the accelerator layer by layer, a number of latest efforts search to democratize LLMs. By loading parameters from RAM simply in time for every ahead move, this system allows executing LLMs with a single low-end accelerator. Though offloading has excessive latency, it will probably course of a number of tokens in parallel. As an example, they’re producing one token with BLOOM-176B requires at the very least 5.5 seconds for the quickest RAM offloading system and 22 seconds for the quickest SSD offloading association.
Moreover, many machines lack enough RAM to unload 175B parameters. LLMs could also be made extra extensively out there by means of public inference APIs, the place one celebration hosts the mannequin and permits others to question it on-line. It is a pretty user-friendly selection as a result of the API proprietor handles many of the engineering effort. Nonetheless, APIs are regularly too inflexible for use in analysis since they can not alter the mannequin’s management construction or have entry to its inside states. Moreover, the price of some analysis initiatives could also be exorbitant, given the present API value. On this examine, they examine a distinct method motivated by widespread crowdsourcing coaching of neural networks from scratch.
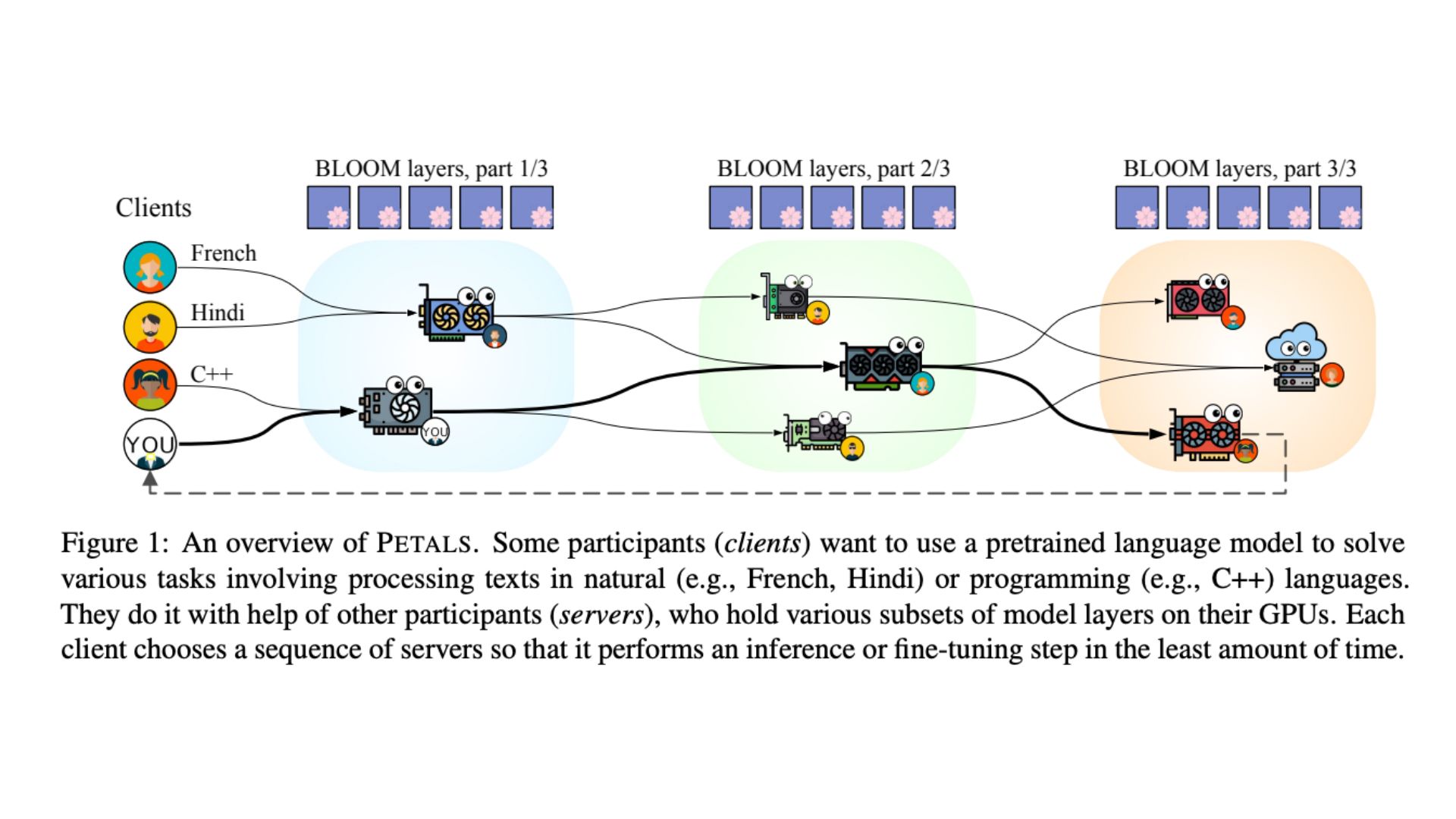
They develop PETALS, a framework that allows on-line collaboration between a number of customers to deduce and optimize sizable language fashions. Every participant controls a shopper, a server, or each. A server responds to shopper queries and retains a portion of the mannequin layers on its native machine. To conduct the inference of the complete mannequin, a shopper can create a sequence of pipeline-parallel successive servers. Along with inference, contributors can alter the mannequin by coaching all layers or utilizing parameter-efficient coaching strategies like adapters or fast tuning. Submodules may be posted on a mannequin hub after coaching so others can make the most of them for inference or further coaching.
In addition they present how a number of enhancements, together with dynamic quantization, prioritizing low-latency connections, and cargo balancing throughout servers, might make present 100B+ fashions function effectively on this setting. Lastly, they cowl safety and privateness issues, rewards for utilizing the system, and the way the mannequin could be improved over time. The code is freely out there on GitHub and have deployed their chat software as effectively.
Try the Paper, Code, and Tool. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to affix our Reddit page and discord channel, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is captivated with constructing options round it. He loves to attach with folks and collaborate on fascinating initiatives.
[ad_2]
Source link
