

[ad_1]
The efficiency accuracy of fashions employed in numerous speech translation duties has tremendously elevated resulting from latest scientific advances. Though these fashions carry out higher than ever, they’re nonetheless removed from excellent. One of many major causes for this shortcoming is background noise. Completely different background noises, resembling site visitors, music, and different individuals talking, make it extra obscure others, even in each day life. Prior research recommend that different human senses, significantly imaginative and prescient, are essential for facilitating communication on this context. As an illustration, if somebody converses with their buddy at a celebration, they may doubtless take note of their lip motion with a view to higher grasp what they’re saying.
As a way to replicate this human conduct in neural networks, researchers previously have developed many Audio-Visible Speech Recognition (AVSR) strategies that translate spoken phrases using each audio and visible inputs. Some examples of such methods embrace Meta AI’s publicly accessible AV-HuBERT and RAVen fashions, which combine visible information to boost efficiency for English speech recognition duties. These deep learning-based strategies have been confirmed to be extremely profitable at enhancing the robustness of speech recognition. Including on to this wave of analysis in speech translation, Meta AI has now unveiled MuAViC (Multilingual Audio-Visible Corpus), the first-ever benchmark that permits the appliance of audio-visual studying for very correct speech translation. MuAViC is a multilingual audio-visual corpus that works properly for duties requiring correct speech recognition and speech-to-text translation duties. The researchers at Meta declare that it’s the first open benchmark for audio-visual speech-to-text translation and the biggest recognized benchmark for multilingual audio-visual speech recognition.
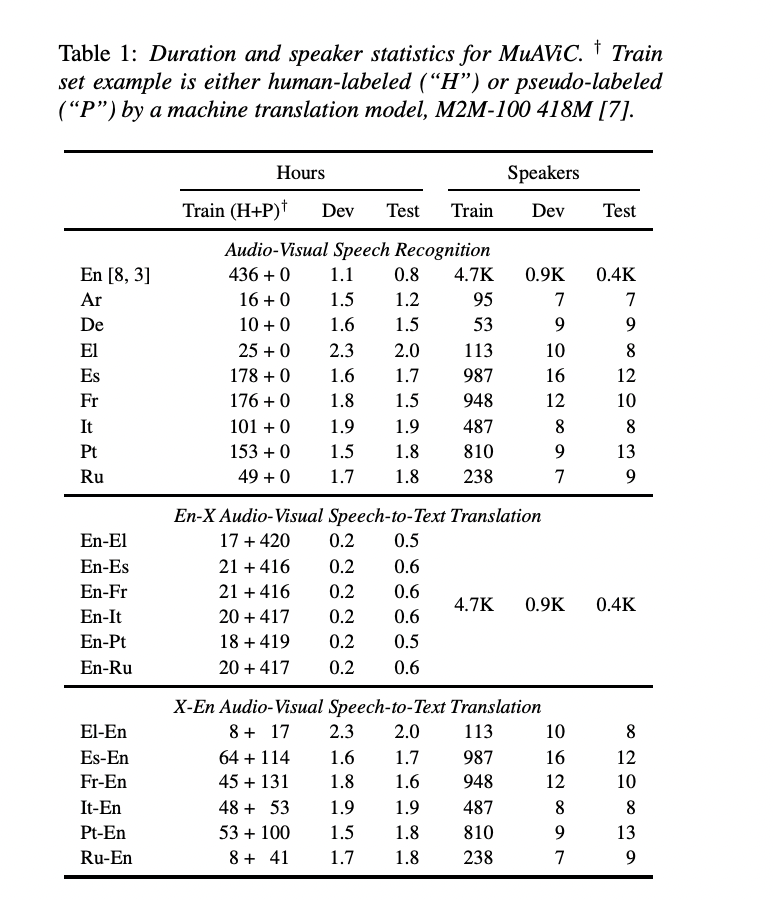
A complete of 1200 hours of transcribed audio-visual speech from greater than 8000 audio system in 9 languages, together with English, Arabic, Spanish, French, and Russian, are included in MuAViC. This corpus, which accommodates textual content translations and establishes baselines for six English-to-X translations and 6 X-to-English translation instructions, is derived from TED and TEDx lectures. Attributable to insufficient coaching information, the concept of extending audio-visual understanding to voice translation was beforehand untapped. That is the place Meta researchers put important effort into accumulating and processing audio-video information.
The researchers utilized audio-visual information from the LRS3 dataset for English TED talks after which used a text-matching algorithm to align it with a corpus of machine translations. The goal sentences for the matching samples have been then paired with their applicable translation labels within the machine translation corpus. To make sure one of the best accuracy, the researchers made positive to make use of the identical textual content matching for samples from each the event set and the check set. For non-English TED talks, the researchers reused solely audio information, transcriptions, and textual content translations collected within the speech translation dataset. They acquired the video tracks from the supply recordings so as to add the visible part after which aligned processed video information with the audio information to provide audio-visual information.
The researchers employed MuAViC to coach Meta’s AV-HuBERT structure to create end-to-end speech recognition and translation fashions in noisy, difficult settings. Meta’s structure can efficiently course of each modalities of an audio-video enter and mix their representations right into a single area that can be utilized for both speech recognition or translation duties. Furthermore, AV-HuBERT can nonetheless deal with the given enter modality, albeit much less successfully, if one of many required enter modalities is absent. Their mannequin’s resistance to noise is what units it aside. The mannequin will rely extra on the visible modality to finish the duty appropriately if the audio modality is distorted resulting from noise or different points. A number of experimental evaluations revealed that MuAViC is exceptionally efficient for constructing noise-robust speech recognition and translation fashions.
Meta hopes their contribution will assist the group construct extra strong speech recognition and translation methods in several languages. The corporate has all the time put important efforts into speech translation analysis as a result of they consider that it has the potential to carry individuals collectively by breaking down communication boundaries. The researchers are extraordinarily enthusiastic about how the analysis group will use MuAViC in growing methods that may contribute to fixing real-world issues.
Try the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t neglect to affix our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Khushboo Gupta is a consulting intern at MarktechPost. She is at present pursuing her B.Tech from the Indian Institute of Expertise(IIT), Goa. She is passionate concerning the fields of Machine Studying, Pure Language Processing and Internet Improvement. She enjoys studying extra concerning the technical area by taking part in a number of challenges.
[ad_2]
Source link
