

[ad_1]
Robots are unimaginable. They’ve already revolutionized the way in which we stay and work, and so they nonetheless have the potential to do it once more. They modified the way in which we stay by doing mundane duties for us, like vacuuming. Furthermore, and extra importantly, they modified the way in which we produce. Robots can carry out complicated duties with velocity, precision, and effectivity that far exceeds what people are able to.
Robots helped us to considerably enhance productiveness and output in industries reminiscent of manufacturing, logistics, and agriculture. As they proceed to advance, we will anticipate them to develop into much more subtle and versatile. We can use them to carry out duties that had been beforehand thought unattainable. For instance, robots outfitted with synthetic intelligence and machine studying algorithms can now study from their surroundings and adapt to new conditions, making them much more helpful in a variety of purposes.
Nonetheless, robots are nonetheless costly and fancy toys. Constructing them is one story, however instructing them to do one thing is usually extraordinarily time-consuming and requires intensive programming expertise. Educating robots tips on how to carry out manipulation duties which might be usually relevant with excessive effectivity has been a persistent problem for a very long time.
One method to instructing robots effectively is to make use of imitation studying. Imitation studying is a technique of instructing robots tips on how to carry out duties by imitating human demonstrations. Robots can observe and mimic human actions after which use that knowledge to enhance their very own talents. Whereas current developments in imitation studying have proven promise, there are nonetheless important obstacles to beat.
Imitation studying is actually helpful to coach robots to carry out easy duties reminiscent of opening a door or selecting up a particular object, as these actions have a single objective, require short-horizon reminiscence, and circumstances normally don’t change through the motion. Nonetheless, the problem arises once we change the duty to a extra complicated one with various preliminary and objective circumstances.
The most important problem right here is the time and labor required to gather long-horizon demonstrations. There are two foremost analysis instructions to scale up imitation studying for extra complicated duties; hierarchical imitation studying and studying from play knowledge. Hierarchical imitation studying breaks down the training course of into high-level planners and low-level visuomotor controllers to extend pattern effectivity and make it simpler for robots to study complicated duties.
Then again, studying from play knowledge is about coaching robots utilizing knowledge collected from human-teleoperated robots interacting with the surroundings with out particular activity targets or steerage. One of these knowledge is normally extra various than task-oriented ones as they cowl a variety of behaviors and conditions. Nonetheless, accumulating such play knowledge might be expensive.
These two approaches resolve totally different issues, however we’d like one thing to mix them each. A approach to make the most of the effectivity of hierarchical imitation and effectiveness of studying from play knowledge. Allow us to meet with MimicPlay.
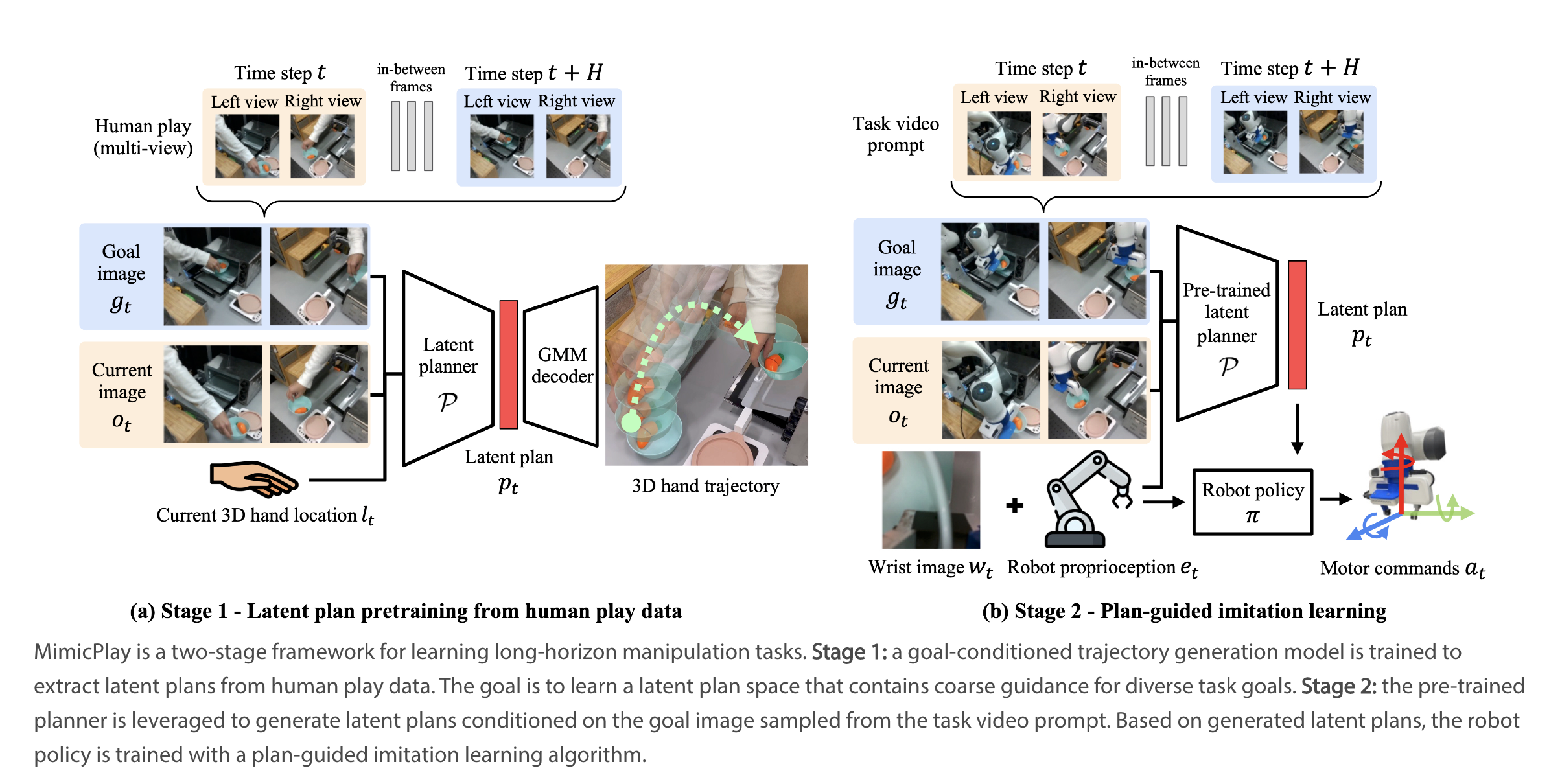
MimicPlay goals to allow robots to study long-horizon manipulation duties utilizing a mixture of human play knowledge and demonstration knowledge. A goal-conditioned latent planner is educated utilizing human play knowledge that predicts future human hand trajectories primarily based on objective pictures. This plan supplies coarse steerage at every time step, making it simpler for the robotic to generate guided motions and carry out complicated duties. As soon as the plan is prepared, the low-level controller incorporates state data to generate ultimate actions.
MimicPlay is evaluated on 14 long-horizon manipulation duties in six totally different environments, and it managed to considerably enhance the efficiency over state-of-the-art imitation studying strategies, particularly in pattern effectivity and generalization talents. This implies MimicPlay was in a position to train the robotic tips on how to carry out complicated duties extra shortly and precisely whereas additionally managing to generalize this data to new environments.
Take a look at the Paper and Project. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to hitch our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
Ekrem Çetinkaya acquired his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin College, Istanbul, Türkiye. He wrote his M.Sc. thesis about picture denoising utilizing deep convolutional networks. He’s presently pursuing a Ph.D. diploma on the College of Klagenfurt, Austria, and dealing as a researcher on the ATHENA mission. His analysis pursuits embrace deep studying, pc imaginative and prescient, and multimedia networking.
[ad_2]
Source link
