


[ad_1]

Photograph by Towfiqu barbhuiya on Unsplash
On the intersection of computational linguistics and synthetic intelligence is the place we discover pure language processing. Very broadly, pure language processing (NLP) is a self-discipline which is desirous about how human languages, and, to some extent, the people who communicate them, work together with expertise. NLP is an interdisciplinary subject which has traditionally been the equal area of synthetic intelligence researchers and linguistics alike; maybe clearly, these approaching the self-discipline from the linguistics aspect should rise up to hurry on expertise, whereas these getting into the self-discipline from the expertise realm have to be taught the linguistic ideas.
It’s this second group that this put up goals to serve at an introductory degree, as we take a no-nonsense strategy to defining some key NLP terminology. When you actually will not be a linguistic knowledgeable after studying this, we hope that you’re higher in a position to perceive a number of the NLP-related discourse, and acquire perspective as to methods to proceed with studying extra on the subjects herein.
So right here they’re, 18 choose pure language processing phrases, concisely outlined.
Pure language processing (NLP) considerations itself with the interplay between pure human languages and computing gadgets. NLP is a serious side of computational linguistics, and in addition falls throughout the realms of pc science and synthetic intelligence.
Tokenization is, usually, an early step within the NLP course of, a step which splits longer strings of textual content into smaller items, or tokens. Bigger chunks of textual content might be tokenized into sentences, sentences might be tokenized into phrases, and so on. Additional processing is mostly carried out after a bit of textual content has been appropriately tokenized.
Earlier than additional processing, textual content must be normalized. Normalization usually refers to a sequence of associated duties meant to place all textual content on a degree taking part in area: changing all textual content to the identical case (higher or decrease), eradicating punctuation, increasing contractions, changing numbers to their phrase equivalents, and so forth. Normalization places all phrases on equal footing, and permits processing to proceed uniformly.
Stemming is the method of eliminating affixes (suffixed, prefixes, infixes, circumfixes) from a phrase with a view to acquire a phrase stem.
Lemmatization is said to stemming, differing in that lemmatization is ready to seize canonical types based mostly on a phrase’s lemma.
For instance, stemming the phrase “higher” would fail to return its quotation kind (one other phrase for lemma); nevertheless, lemmatization would consequence within the following:
It ought to be straightforward to see why the implementation of a stemmer can be the easier feat of the 2.
In linguistics and NLP, corpus (actually Latin for physique) refers to a set of texts. Such collections could also be fashioned of a single language of texts, or can span a number of languages — there are quite a few causes for which multilingual corpora (the plural of corpus) could also be helpful. Corpora can also encompass themed texts (historic, Biblical, and so on.). Corpora are usually solely used for statistical linguistic evaluation and speculation testing.
Cease phrases are these phrases that are filtered out earlier than additional processing of textual content, since these phrases contribute little to total that means, on condition that they’re usually the most typical phrases in a language. As an illustration, “the,” “and,” and “a,” whereas all required phrases in a selected passage, do not usually contribute enormously to at least one’s understanding of content material. As a easy instance, the next panagram is simply as legible if the cease phrases are eliminated:
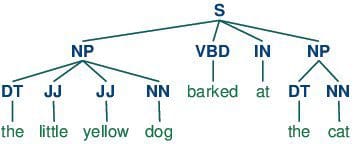
POS tagging consists of assigning a class tag to the tokenized components of a sentence. The most well-liked POS tagging can be figuring out phrases as nouns, verbs, adjectives, and so on.
Statistical Language Modeling is the method of constructing a statistical language mannequin which is supposed to offer an estimate of a pure language. For a sequence of enter phrases, the mannequin would assign a likelihood to your entire sequence, which contributes to the estimated chance of assorted doable sequences. This may be particularly helpful for NLP functions which generate textual content.
Bag of phrases is a selected illustration mannequin used to simplify the contents of a number of textual content. The bag of phrases mannequin omits grammar and phrase order, however is within the variety of occurrences of phrases throughout the textual content. The last word illustration of the textual content choice is that of a bag of phrases (bag referring to the set concept idea of multisets, which differ from easy units).
Precise storage mechanisms for the bag of phrases illustration can fluctuate, however the next is a straightforward instance utilizing a dictionary for intuitiveness. Pattern textual content:
“There, there,” stated James. “There, there.”
The ensuing bag of phrases illustration as a dictionary:
{
'properly': 3,
'stated': 2,
'john': 1,
'there': 4,
'james': 1
}
n-grams is one other illustration mannequin for simplifying textual content choice contents. Versus the orderless illustration of bag of phrases, n-grams modeling is desirous about preserving contiguous sequences of N objects from the textual content choice.
An instance of trigram (3-gram) mannequin of the second sentence of the above instance (“There, there,” stated James. “There, there.”) seems as a listing illustration under:
[
"there there said",
"there said james",
"said james there",
"james there there",
]
Common expressions, typically abbreviated regexp or regexp, are a tried and true technique of concisely describing patterns of textual content. An everyday expression is represented as a particular textual content string itself, and is supposed for growing search patterns on choices of textual content. Common expressions might be regarded as an expanded algorithm past the wildcard characters of ? and *. Although typically cited as irritating to be taught, common expressions are extremely highly effective textual content looking instruments.
Zipf’s Legislation is used to explain the connection between phrase frequencies in doc collections. If a doc assortment’s phrases are ordered by frequency, and y is used to explain the variety of occasions that the xth phrase seems, Zipf’s statement is concisely captured as y = cx-1/2 (merchandise frequency is inversely proportional to merchandise rank). Extra usually, Wikipedia says:
Zipf’s legislation states that given some corpus of pure language utterances, the frequency of any phrase is inversely proportional to its rank within the frequency desk. Thus probably the most frequent phrase will happen roughly twice as typically because the second most frequent phrase, thrice as typically because the third most frequent phrase, and so on.
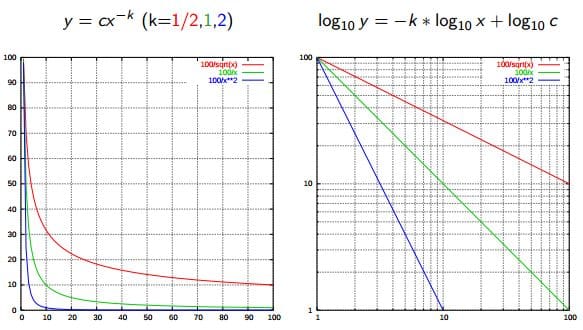
Supply: Wikipedia
There are quite a few similarity measures which might be utilized to NLP. What are we measuring the similarity of? Typically, strings.
- Levenshtein – the variety of characters that have to be deleted, inserted, or substituted with a view to make a pair of strings equal
- Jaccard – the measure of overlap between 2 units; within the case of NLP, usually, paperwork are units of phrases
- Smith Waterman – just like Levenshtein, however with prices assigned to substitution, insertion, and deletion
Additionally known as parsing, syntactic evaluation is the duty of analyzing strings as symbols, and guaranteeing their conformance to a established set of grammatical guidelines. This step should, out of necessity, come earlier than any additional evaluation which makes an attempt to extract perception from textual content — semantic, sentiment, and so on. — treating it as one thing past symbols.
Also referred to as that means era, semantic evaluation is desirous about figuring out the that means of textual content choices (both character or phrase sequences). After an enter number of textual content is learn and parsed (analyzed syntactically), the textual content choice can then be interpreted for that means. Merely put, syntactic evaluation is anxious with what phrases a textual content choice was made up of, whereas semantic evaluation needs to know what the gathering of phrases truly means. The subject of semantic evaluation is each broad and deep, with all kinds of instruments and strategies on the researcher’s disposal.
Sentiment evaluation is the method of evaluating and figuring out the sentiment captured in a number of textual content, with sentiment outlined as feeling or emotion. This sentiment might be merely optimistic (joyful), destructive (unhappy or indignant), or impartial, or might be some extra exact measurement alongside a scale, with impartial within the center, and optimistic and destructive rising in both path.
Data retrieval is the method of accessing and retrieving probably the most acceptable info from textual content based mostly on a selected question, utilizing context-based indexing or metadata. Probably the most well-known examples of knowledge retrieval can be Google Search.
Matthew Mayo (@mattmayo13) is a Information Scientist and the Editor-in-Chief of KDnuggets, the seminal on-line Information Science and Machine Studying useful resource. His pursuits lie in pure language processing, algorithm design and optimization, unsupervised studying, neural networks, and automatic approaches to machine studying. Matthew holds a Grasp’s diploma in pc science and a graduate diploma in information mining. He might be reached at editor1 at kdnuggets[dot]com.
[ad_2]
Source link
