

[ad_1]
Comparability of reported inference efficiency speedups for The Optimum BERT Surgeon (oBERT) with different strategies on the SQuAD dataset. oBERT efficiency was measured utilizing the DeepSparse Engine on a c5.12xlarge AWS occasion.
The trendy world is made up of fixed communication occurring by means of textual content. Assume messaging apps, social networks, documentation and collaboration instruments, or books. This communication generates monumental quantities of actionable information for firms that want to use it to enhance their customers’ experiences. For instance, the video on the backside of this weblog exhibits how a person can monitor the overall sentiment of cryptocurrency throughout Twitter utilizing an NLP neural community – BERT. By many novel contributions, BERT considerably improved the state-of-the-art for NLP duties corresponding to textual content classification, token classification, and query answering. It did this in a really “over-parameterized” means, although. Its 500MB mannequin measurement and sluggish inference prohibit many environment friendly deployment situations, particularly on the edge. And cloud deployments turn into pretty costly, pretty shortly.
BERT’s inefficient nature has not gone unnoticed. Many researchers have pursued methods to scale back its value and measurement. A number of the most energetic analysis is in mannequin compression strategies corresponding to smaller architectures (structured pruning), distillation, quantization, and unstructured pruning. Just a few of the extra impactful papers embody:
- DistilBERT used knowledge distillation to switch data from a BERT base mannequin to a 6-layer model.
- TinyBERT carried out a extra difficult distillation setup to higher switch the data from the baseline mannequin right into a 4-layer model.
- The Lottery Ticket Hypothesis utilized magnitude pruning throughout pre-training of a BERT mannequin to create a sparse structure that generalized effectively throughout fine-tuning duties.
- Movement Pruning utilized a mixture of the magnitude and gradient info to take away redundant parameters whereas fine-tuning with distillation.
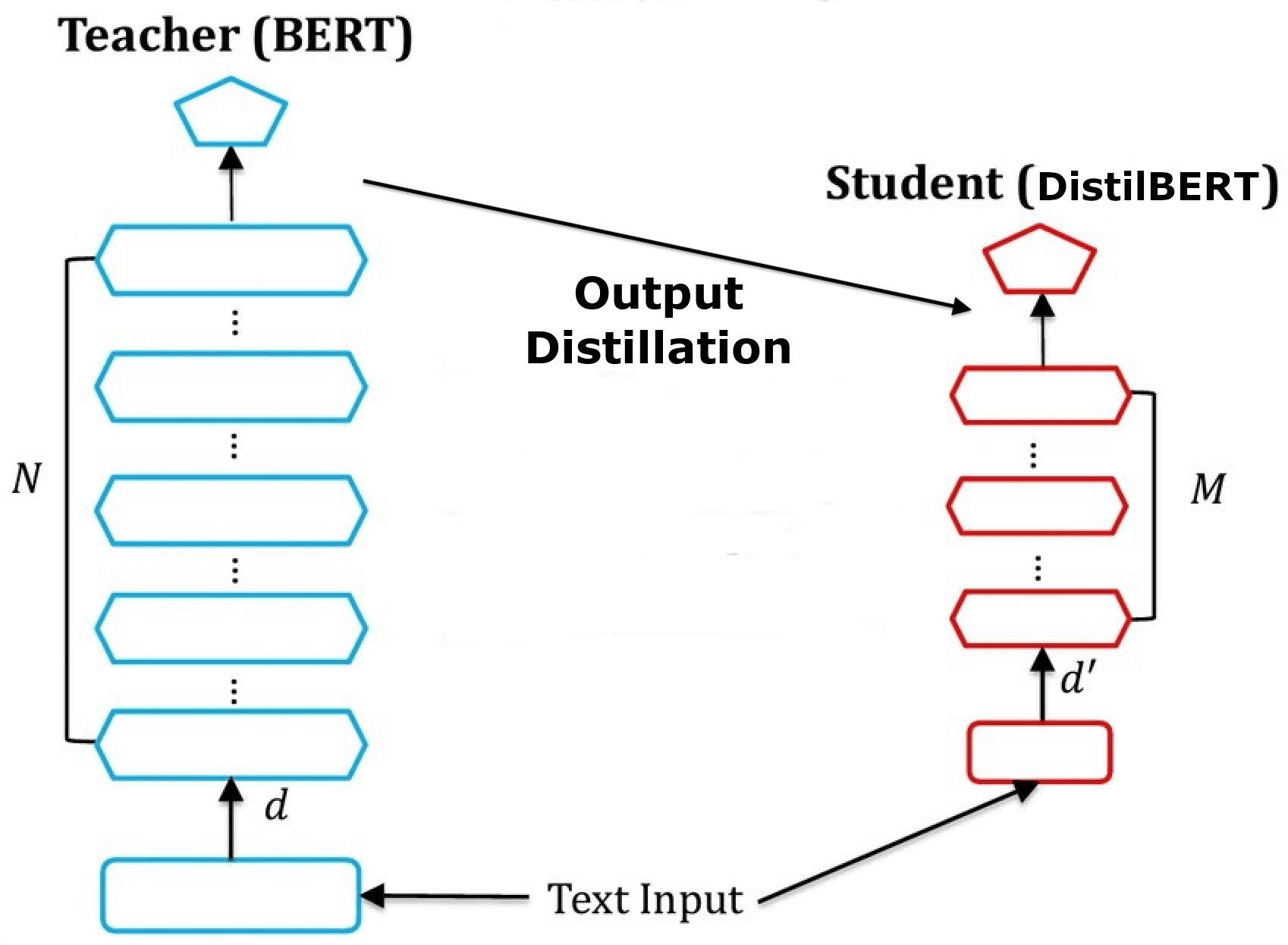
DistilBERT coaching illustration

TinyBERT coaching illustration
We present that BERT is extremely over-parameterized in our latest paper, The Optimal BERT Surgeon. Ninety % of the community will be eliminated with minimal impact on the mannequin and its accuracy!
Actually, 90%? Sure! Our analysis crew at Neural Magic in collaboration with IST Austria improved the prior greatest 70% sparsity to 90% by implementing a second-order pruning algorithm, Optimum BERT Surgeon. The algorithm makes use of a Taylor enlargement to approximate the impact of every weight on the loss operate – all of this implies we all know precisely which weights are redundant within the community and are protected to take away. When combining this system with distillation whereas coaching, we’re in a position to get to 90% sparsity whereas recovering to 99% of the baseline accuracy!
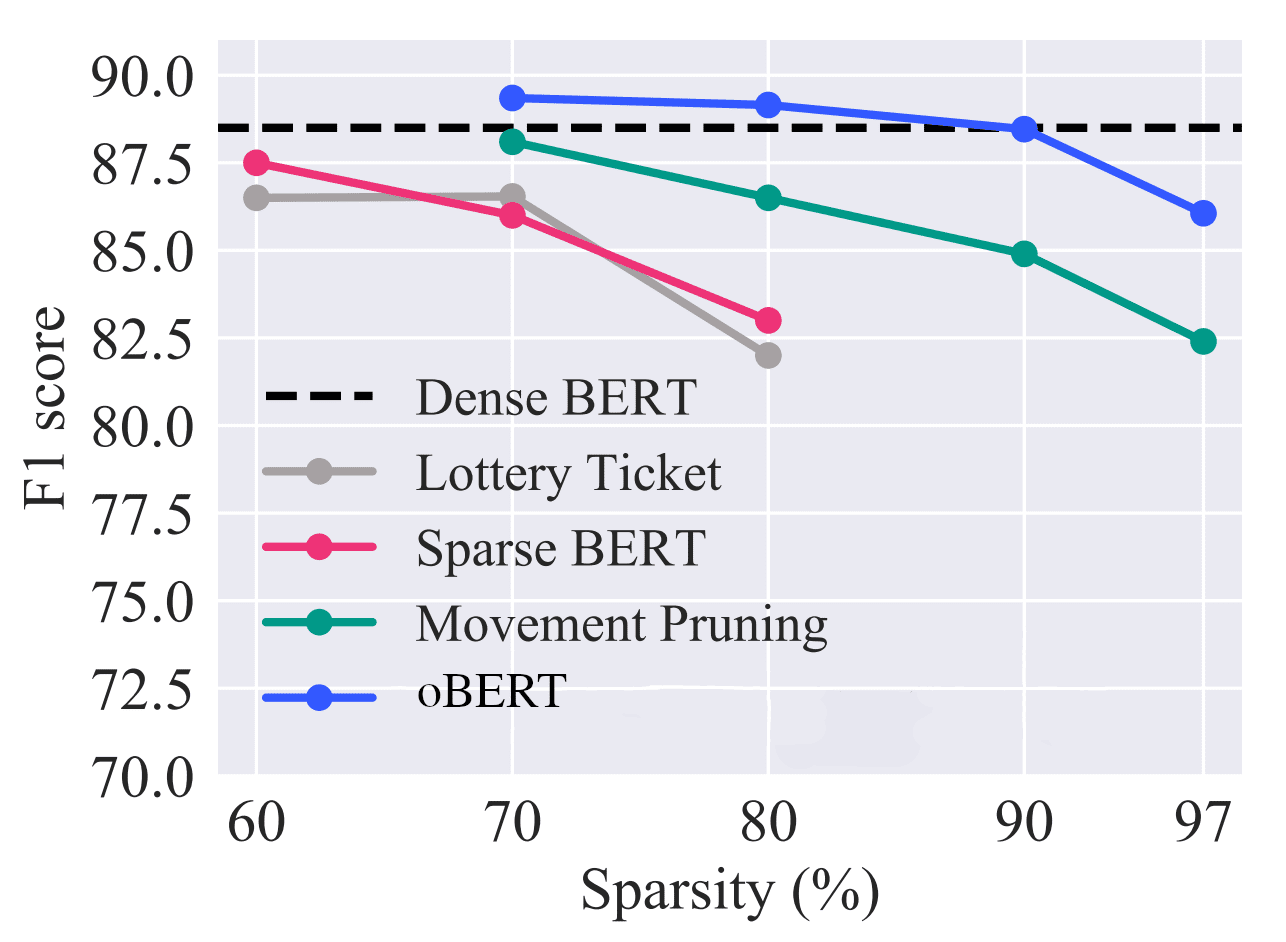
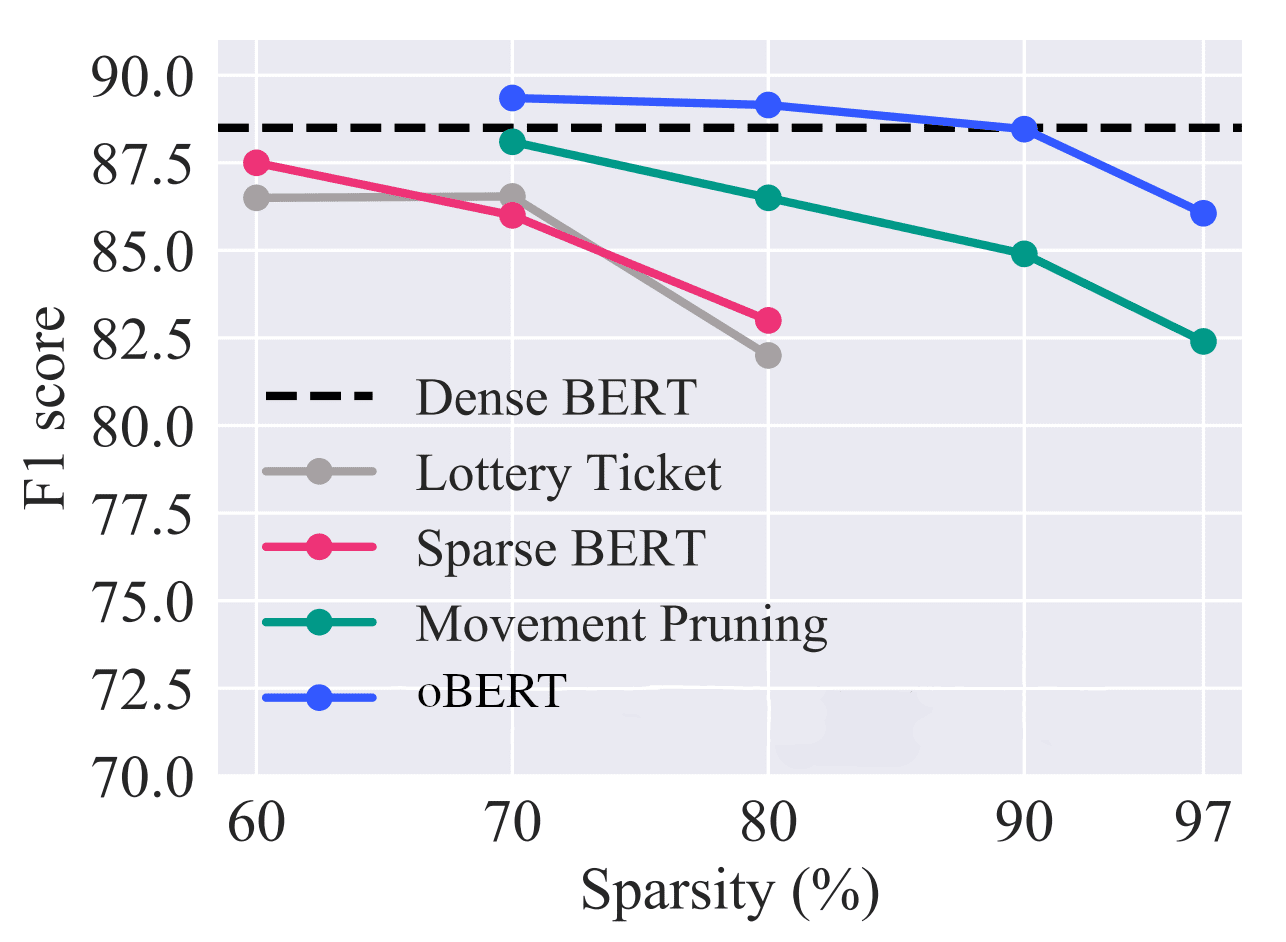
Efficiency overview relative to present state-of-the-art unstructured pruning strategies on the 12-layer BERT-base-uncased mannequin and the question-answering SQuAD v1.1 dataset.
However, are structured pruned variations of BERT over-parameterized as effectively? In making an attempt to reply this query, we eliminated as much as 3/4 of the layers to create our 6-layer and 3-layer sparse variations. We first retrained these compressed fashions with distillation after which utilized Optimum BERT Surgeon pruning. In doing this, we discovered that 80% of the weights from these already-compressed fashions might be additional eliminated with out affecting the accuracy. For instance, our 3-layer mannequin removes 81 million of the 110 million parameters in BERT whereas recovering 95% of the accuracy, creating our Optimum BERT Surgeon fashions (oBERT).
Given the excessive degree of sparsity, we launched with oBERT fashions, we measured the inference efficiency utilizing the DeepSparse Engine – a freely-available, sparsity-aware inference engine that’s engineered to extend the efficiency of sparse neural networks on commodity CPUs, like those in your laptop computer. The chart beneath exhibits the ensuing speedups for a pruned 12-layer that outperforms DistilBERT and a pruned 3-layer that outperforms TinyBERT. With the mix of DeepSparse Engine and oBERT, extremely correct NLP CPU deployments at the moment are measured in just a few milliseconds (few = single digits).
After making use of the structured pruning and Optimum BERT Surgeon pruning strategies, we embody quantization-aware coaching to benefit from the DeepSparse Engine’s sparse quantization help for X86 CPUs. Combining quantization and our sparse fashions with 4-block pruning for DeepSparse VNNI support leads to a quantized, 80% sparse 12-layer mannequin that achieves the 99% restoration goal. The mixture of all these strategies is what we termed “compound sparsification.”
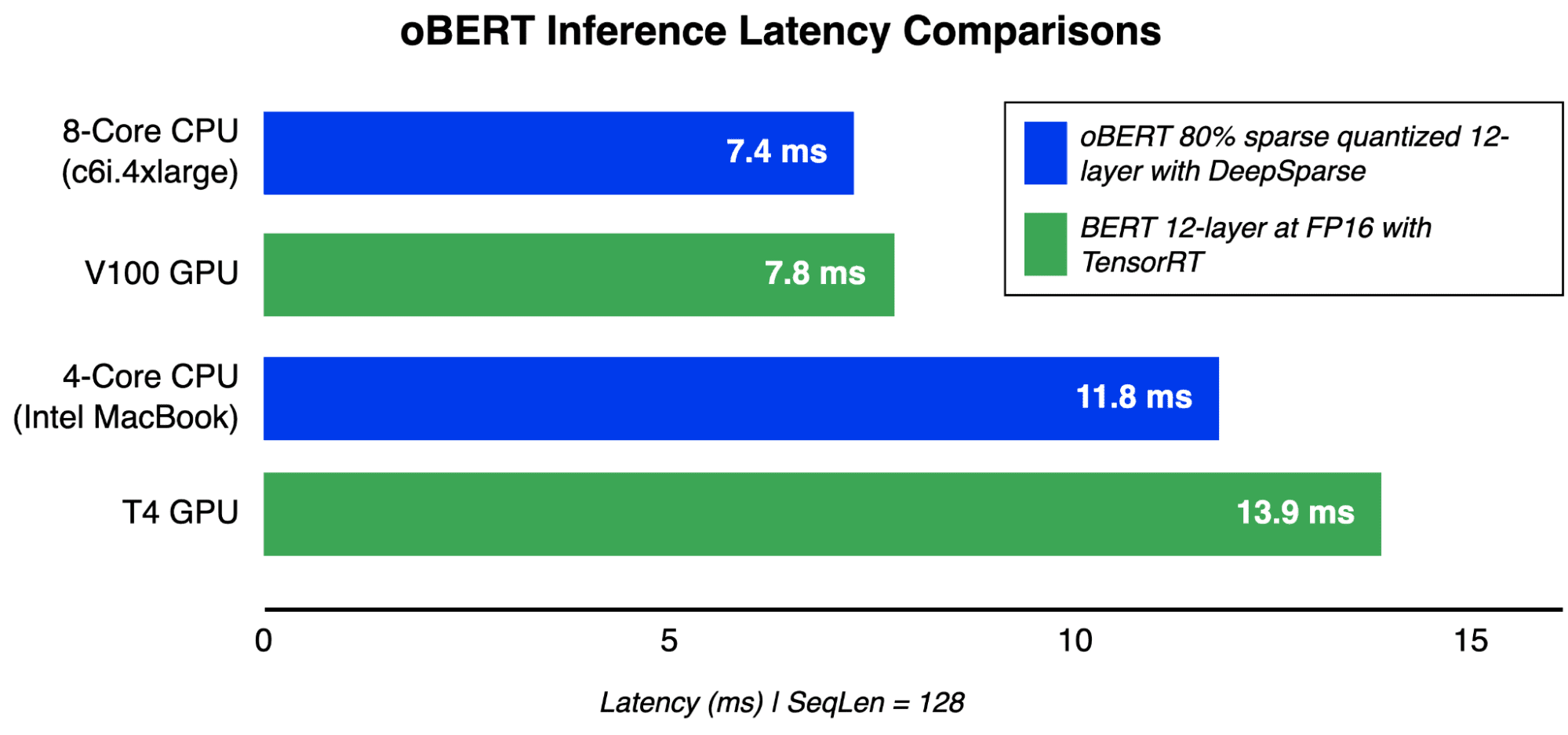
Latency inference comparisons at batch measurement 1, sequence size 128 for oBERT on CPUs and GPUs.
The result’s GPU-level efficiency for BERT fashions on available CPUs. With the sparse quantized oBERT 12-layer mannequin, a 4-core Intel MacBook is now extra performant than a T4 GPU and an 8-core server outperforms a V100 for latency-sensitive purposes. Even additional speedups are realized when utilizing the three and 6-layer fashions for barely much less accuracy.
“A 4-core Intel MacBook is now extra performant than a T4 GPU and an 8-core server outperforms a V100 for latency-sensitive purposes.”
Twitter pure language processing video evaluating the efficiency enhancements from oBERT to an unoptimized, baseline mannequin.
In spirit with the analysis group and enabling continued contributions, the supply code for creating oBERT fashions is open sourced by means of SparseML and the fashions are freely out there on the SparseZoo. Moreover, the DeepSparse Twitter crypto instance is open sourced in the DeepSparse repo. Strive it out to performantly monitor crypto developments, or another developments, in your {hardware}! Lastly, we’ve pushed up easy use-case walkthroughs to focus on the bottom flows wanted to use this analysis to your information.
Mark Kurtz (@markurtz_) is Director of Machine Studying at Neural Magic, and an skilled software program and machine studying chief. Mark is proficient throughout the total stack for engineering and machine studying, and is enthusiastic about mannequin optimizations and environment friendly inference.
[ad_2]
Source link
