


[ad_1]

Picture by Editor
NVIDIA GPUs have change into some of the efficient methods to speed up computationally intensive machine studying duties. Now, because of RAPIDS cuDF, GPUs may also turbocharge your information evaluation work.
RAPIDS cuDF is an open-source, GPU-accelerated dataframe library that implements the acquainted pandas API for processing and analyzing your information. The Python cuDF interface is constructed on libcudf, the CUDA/C++ computational core that accelerates elementary information operations from ingestion and parsing, to joins, aggregations, and extra. For some workloads, you can see that switching from import pandas to import cudf accelerates your workloads and may result in information processing speedups of 10x or extra.
For instance, a easy be a part of operation can go from 761ms to 27ms just by switching to cuDF:
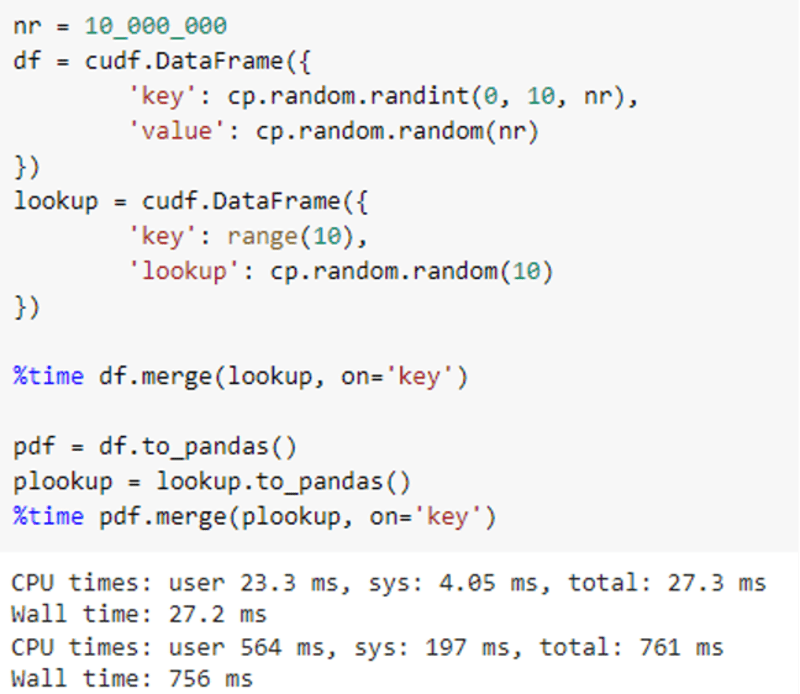
Now it’s simpler than ever to get began with RAPIDS on Colab. With Colab’s default runtime update to Python 3.8 and the brand new RAPIDS pip packages, you’ll be able to check out NVIDIA GPU-accelerated information science proper in your browser. Working RAPIDS on Colab requires simply two fast steps:
- First, choose a Colab runtime that makes use of a GPU accelerator. Navigate to the “Runtime” menu and choose “Change runtime kind,” then select “GPU” from the dropdown and click on “Save.” The NVIDIA GPU that you simply obtain from Colab could fluctuate throughout periods, — together with each newer GPUs and older generations. With the brand new “Pay As You Go” Tier in Colab, you now have the choice to improve your runtime to “Premium GPUs” with Colab Professional, enabling entry to extra highly effective NVIDIA A100 or V100 Tensor Core GPUs. See Google’s blog post for more information on GPU availability.
- Second, set up RAPIDS cuDF in your pocket book. With the brand new RAPIDS pip packages, this step is less complicated than ever. Execute the next command in a code block and you may be set as much as run RAPIDS. Be certain to restart your runtime after the set up completes:
!pip set up cudf-cu11 --extra-index-url=https://pypi.ngc.nvidia.com
!rm -rf /usr/native/lib/python3.8/dist-packages/cupy*
!pip set up cupy-cuda11x
Lastly, test that import cudf completes efficiently in a brand new code block, after which you’re able to go. When you run into any bother, please attain out in the RAPIDS Slack and we’ll assist you to get issues working accurately.
Now that you’ve a working cuDF set up and a GPU, you’ll be able to run our tutorial pocket book, “10 minutes to cuDF.” This pocket book is impressed by the same information from the Pandas group and is a streamlined model of our full pocket book, “10 Minutes to cuDF and Dask-cuDF.”
Working by the pocket book, you can see examples of dataframe creation, information filtering, transformation, joins, aggregations and extra. We’ve additionally included file studying and writing examples for Parquet, ORC and CSV codecs. As you examine extra complicated information processing, we hope that you simply use this as a companion to cuDF’s documentation.
When you find yourself able to dive deeper , RAPIDS additionally contains Dask-cuDF for giant workflows, cuML for scikit-learn-compatible, accelerated machine studying, and cuGraph for graph information analytics. Replace your Colab pocket book with the prolonged set up checklist, as proven within the following code block, and also you’ll be prepared to make use of the entire toolkit.
!pip set up cudf-cu11 dask-cudf-cu11 cuml-cu11 cugraph-cu11 --extra-index-url=https://pypi.ngc.nvidia.com
!rm -rf /usr/native/lib/python3.8/dist-packages/cupy*
!pip set up cupy-cuda11x
Listed here are some extra RAPIDS notebooks you’ll be able to discover to be taught extra about RAPIDS:
Paul Mahler is a senior information scientist and technical product supervisor for machine studying at NVIDIA in Denver, CO. At NVIDIA, Paul’s focus has been on constructing instruments that speed up information science workflows by leveraging the ability of GPU know-how.
Original. Reposted with permission.
[ad_2]
Source link
