

[ad_1]
With the latest developments within the subject of Machine Studying (ML), Reinforcement Studying (RL), which is one in every of its branches, has grow to be considerably in style. In RL, an agent picks up expertise to work together with its environment by appearing in a manner that maximizes the sum of its rewards.
The incorporation of world fashions into RL has emerged as a potent paradigm lately. Brokers could observe, simulate, and plan inside the discovered dynamics with the assistance of the world fashions, which encapsulate the dynamics of the encircling surroundings. Mannequin-Primarily based Reinforcement Studying (MBRL) has been made simpler by this integration, during which an agent learns a world mannequin from earlier experiences as a way to forecast the outcomes of its actions and make sensible judgments.
One of many main points within the subject of MBRL is managing long-term dependencies. These dependencies describe situations during which an agent should recollect distant observations as a way to make judgments or conditions during which there are vital temporal gaps between the agent’s actions and the outcomes. The shortcoming of present MBRL brokers to carry out nicely in duties requiring temporal coherence is a results of their frequent struggles with these settings.
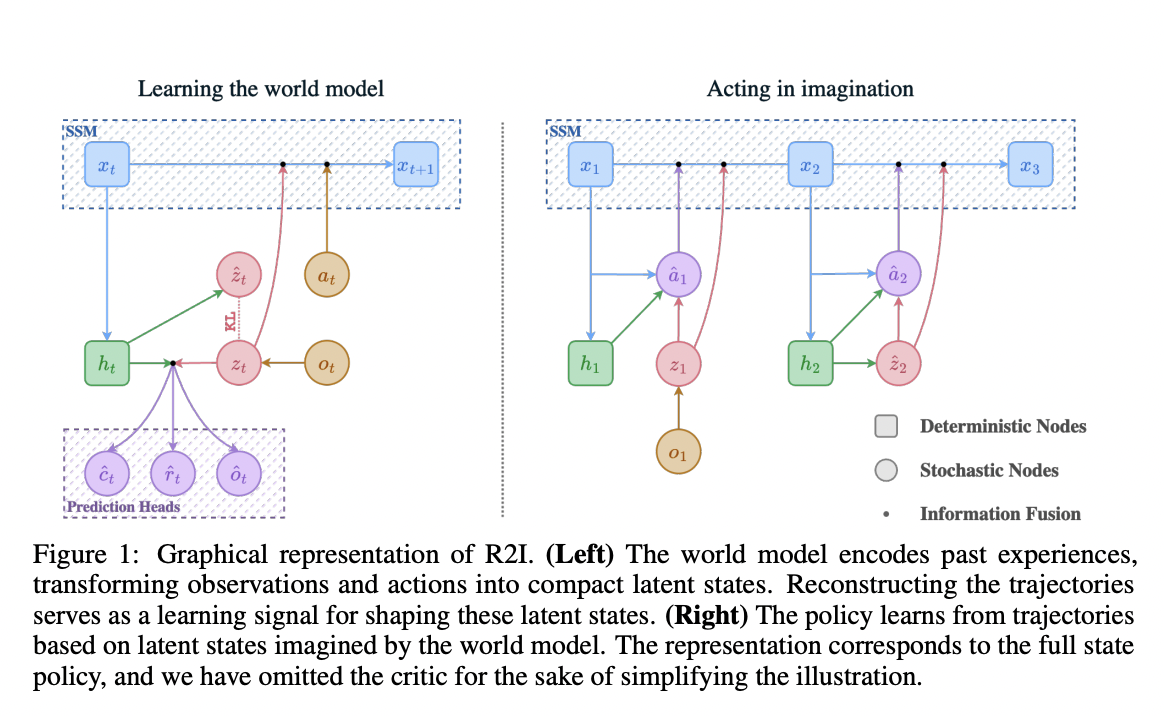
To handle these points, a crew of researchers has steered a singular ‘Recall to Think about’ (R2I) methodology to sort out this downside and improve the brokers’ capability to handle long-term dependency. R2I incorporates a set of state house fashions (SSMs) into the MBRL agent world fashions. The aim of this integration is to enhance the brokers’ capability for long-term reminiscence in addition to their capability for credit score project.
The crew has confirmed the effectiveness of R2I by an in depth analysis of a variety of illustrative jobs. First, R2I has set a brand new benchmark for efficiency on demanding RL duties like reminiscence and credit score project present in POPGym and BSuite environments. R2I has additionally demonstrated superhuman efficiency within the Reminiscence Maze process, a difficult reminiscence area, demonstrating its capability to handle difficult memory-related duties.
R2I has not solely carried out comparably in customary reinforcement studying duties like these within the Atari and DeepMind Management (DMC) environments, but it surely additionally excelled in memory-intensive duties. This means that this method is each generalizable to completely different RL situations and efficient in particular reminiscence domains.
The crew has illustrated the effectiveness of R2I by displaying that it converges extra shortly by way of wall time when in comparison with DreamerV3, probably the most superior MBRL method. As a result of its speedy convergence, R2I is a viable answer for real-world functions the place time effectivity is essential, and it might probably accomplish fascinating outputs extra effectively.
The crew has summarized their major contributions as follows:
- DreamerV3 is the inspiration for R2I, an improved MBRL agent with improved reminiscence. A modified model of S4 has been utilized by R2I to handle temporal dependencies. It preserves the generality of DreamerV3 and provides as much as 9 instances sooner calculation whereas utilizing mounted world mannequin hyperparameters throughout domains.
- POPGym, BSuite, Reminiscence Maze, and different memory-intensive domains have proven that R2I performs higher than its opponents. R2I performs higher than people, particularly in a Reminiscence Maze, which is a tough 3D surroundings that checks long-term reminiscence.
- R2I’s efficiency has been evaluated in RL benchmarks equivalent to DMC and Atari. The outcomes highlighted R2I’s adaptability by displaying that its improved reminiscence capabilities don’t degrade its efficiency in a wide range of management duties.
- As a way to consider the results of the design selections made for R2I, the crew carried out ablation checks. This offered perception into the effectivity of the system’s structure and particular person elements.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our 39k+ ML SubReddit
Tanya Malhotra is a ultimate yr undergrad from the College of Petroleum & Power Research, Dehradun, pursuing BTech in Pc Science Engineering with a specialization in Synthetic Intelligence and Machine Studying.
She is a Information Science fanatic with good analytical and significant pondering, together with an ardent curiosity in buying new expertise, main teams, and managing work in an organized method.
[ad_2]
Source link
