

[ad_1]
In picture recognition, researchers and builders continually search revolutionary approaches to reinforce the accuracy and effectivity of laptop imaginative and prescient programs. Historically, Convolutional Neural Networks (CNNs) have been the go-to fashions for processing picture knowledge, leveraging their skill to extract significant options and classify visible data. Nevertheless, current developments have paved the best way for exploring various architectures, prompting the mixing of Transformer-based fashions into visible knowledge evaluation.
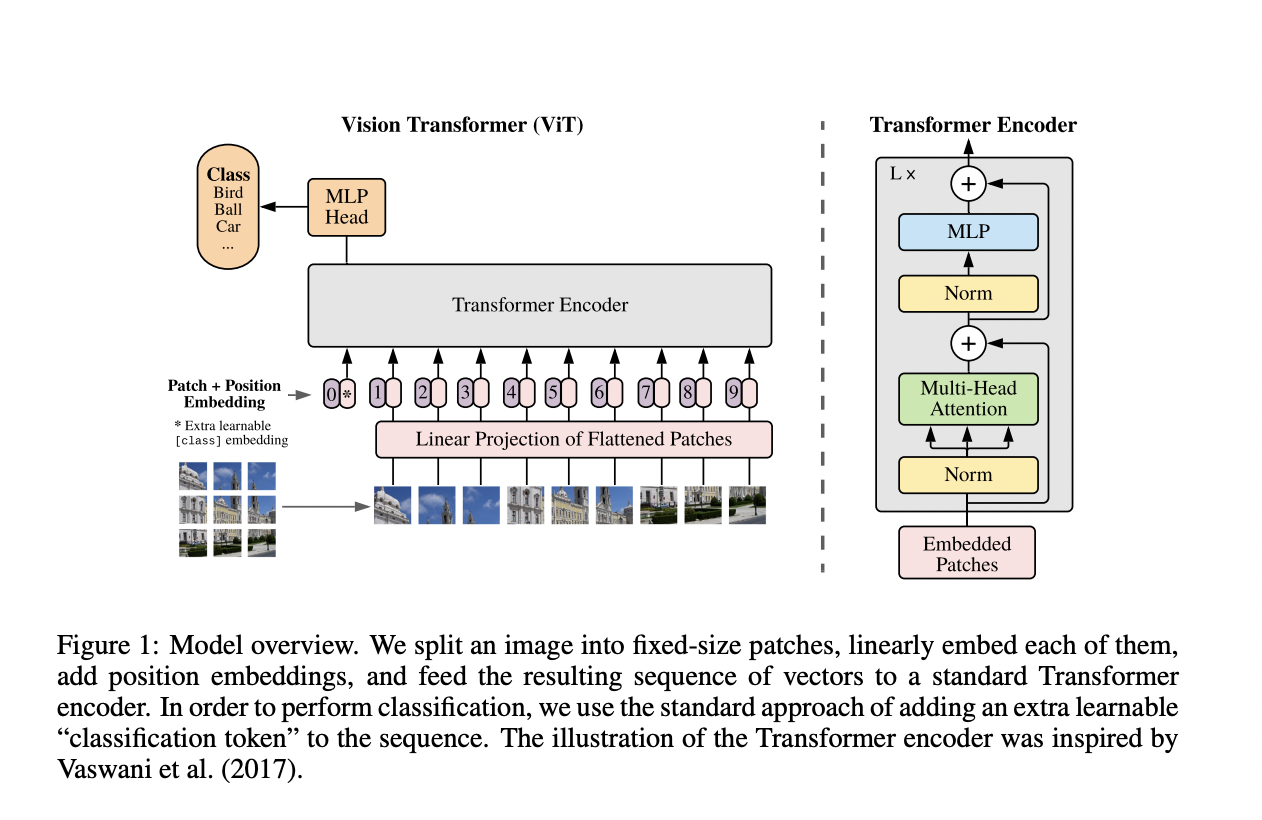
One such groundbreaking improvement is the Imaginative and prescient Transformer (ViT) mannequin, which reimagines the best way pictures are processed by reworking them into sequences of patches and making use of normal Transformer encoders, initially used for pure language processing (NLP) duties, to extract useful insights from visible knowledge. By capitalizing on self-attention mechanisms and leveraging sequence-based processing, ViT provides a novel perspective on picture recognition, aiming to surpass the capabilities of conventional CNNs and open up new prospects for dealing with complicated visible duties extra successfully.

The ViT mannequin reshapes the normal understanding of dealing with picture knowledge by changing 2D pictures into sequences of flattened 2D patches, permitting the appliance of the usual Transformer structure, initially devised for pure language processing duties, to course of visible data. Not like CNNs, which closely depend on image-specific inductive biases baked into every layer, ViT leverages a world self-attention mechanism, with the mannequin using fixed latent vector measurement all through its layers to course of picture sequences successfully. Furthermore, the mannequin’s design integrates learnable 1D place embeddings, enabling the retention of positional data inside the sequence of embedding vectors. By means of a hybrid structure, ViT additionally accommodates the enter sequence formation from characteristic maps of a CNN, additional enhancing its adaptability and flexibility for various picture recognition duties.
The proposed Imaginative and prescient Transformer (ViT), demonstrates promising efficiency in picture recognition duties, rivaling the traditional CNN-based fashions when it comes to accuracy and computational effectivity. By leveraging the ability of self-attention mechanisms and sequence-based processing, ViT successfully captures complicated patterns and spatial relations inside picture knowledge, surpassing the image-specific inductive biases inherent in CNNs. The mannequin’s functionality to deal with arbitrary sequence lengths, coupled with its environment friendly processing of picture patches, allows it to excel in numerous benchmarks, together with standard picture classification datasets like ImageNet, CIFAR-10/100, and Oxford-IIIT Pets.
The experiments carried out by the analysis crew exhibit that ViT, when pre-trained on giant datasets similar to JFT-300M, outperforms the state-of-the-art CNN fashions whereas using considerably fewer computational assets for pre-training. Moreover, the mannequin showcases a superior skill to deal with numerous duties, starting from pure picture classifications to specialised duties requiring geometric understanding, thus solidifying its potential as a sturdy and scalable picture recognition answer.
In conclusion, the Imaginative and prescient Transformer (ViT) mannequin presents a groundbreaking paradigm shift in picture recognition, leveraging the ability of Transformer-based architectures to course of visible knowledge successfully. By reimagining the normal method to picture evaluation and adopting a sequence-based processing framework, ViT demonstrates superior efficiency in numerous picture classification benchmarks, outperforming conventional CNN-based fashions whereas sustaining computational effectivity. With its world self-attention mechanisms and adaptive sequence processing, ViT opens up new horizons for dealing with complicated visible duties, providing a promising path for the way forward for laptop imaginative and prescient programs.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to affix our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.
Madhur Garg is a consulting intern at MarktechPost. He’s presently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Expertise (IIT), Patna. He shares a powerful ardour for Machine Studying and enjoys exploring the newest developments in applied sciences and their sensible functions. With a eager curiosity in synthetic intelligence and its numerous functions, Madhur is decided to contribute to the sector of Information Science and leverage its potential affect in numerous industries.
[ad_2]
Source link
