

[ad_1]
Mannequin specialization includes adapting a pre-trained machine-learning mannequin to a particular activity or area. In Language Fashions (LMs), mannequin specialization is essential in bettering their efficiency in numerous duties like summarization, question-answering, translation, and language technology. The 2 essential processes to specialize a language mannequin to particular duties are instruction fine-tuning (adapting a pre-trained mannequin to a brand new activity or set of duties) and mannequin distillation (transferring data from a pre-trained, “trainer” mannequin to a smaller, specialised, “pupil” mannequin). Prompting is a key idea within the subject of LM specialization, because it supplies a strategy to information the mannequin in the direction of particular behaviors, permits for extra environment friendly use of restricted coaching knowledge, and is essential for reaching state-of-the-art efficiency. Compressing prompts is a method being studied with the hope of resulting in substantial financial savings in computing, reminiscence, and storage and no substantial lower within the general efficiency or high quality of the output.
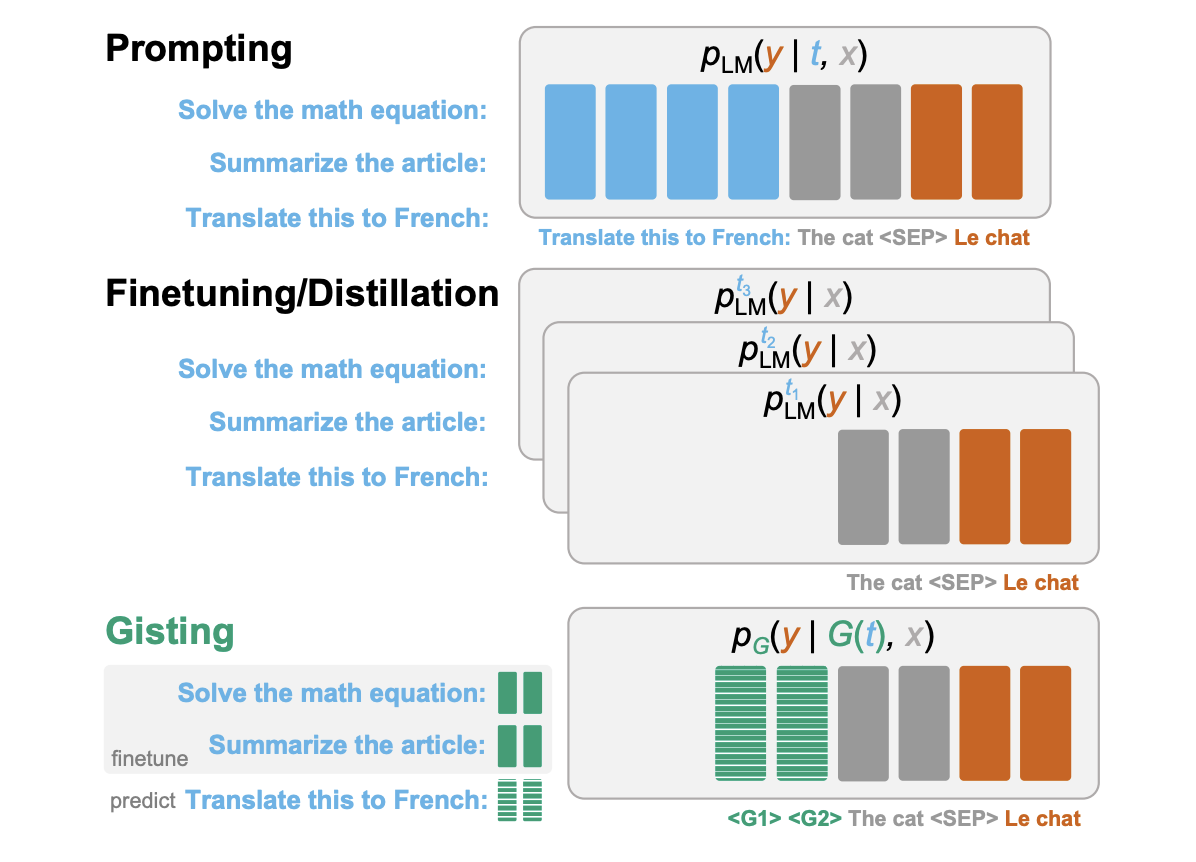
This paper, offered by researchers from Stanford College, proposes a novel approach for immediate compression known as gisting, which trains an LM to compress prompts into smaller units of “gist” tokens. With the intention to scale back the price of the immediate, strategies like fine-tuning or distillation can be utilized to coach a mannequin that may behave like the unique one with out the immediate, however in that case, the mannequin must be re-trained for each new immediate, which is way from ideally suited. The concept behind gisting, nonetheless, is to make use of a meta-learning method to foretell gist tokens from a immediate which might not require re-training the mannequin for every activity and would allow generalization to unseen directions with out further coaching. This may include a discount in computational price and would allow a immediate to be compressed, cached, and reused for compute effectivity. It could additionally permit customers to suit extra content material into the restricted context window.
The authors experimented with a easy means of reaching such a mannequin – they used the LM itself (leveraging its pre-existing data) to foretell the gist tokens in the course of the instruction fine-tuning whereas modifying the Transformer consideration masks. Given a (activity, enter) pair, they add gist tokens between the duty and the enter and set the eye masks within the following means: the enter tokens after the gist tokens can not attend to any of the immediate tokens earlier than the gist tokens (however they’ll attend to the gist tokens). Given the enter and the output can not attend to the immediate, this forces the mannequin to compress the data from the immediate into the gist tokens in between.
To coach the gist fashions, they wanted a dataset with a big number of duties, in order that they created a dataset that they known as Alpaca+, which mixed the information from two present instruction tuning datasets (Standford Alpaca and Self-Instruct) which totaled greater than 130k examples. They then held out 3 validation splits to have the ability to validate the mannequin after coaching which had Seen, Unseen, and hand-crafted Human prompts. This fashion, they have been capable of take a look at the generalization to unseen directions, with the Human break up posing a good stronger generalization problem. In addition they used a number of LM architectures (particularly LLaMA-7Bm, a decoder-only GPT-style mannequin, and FLAN-T5-XXL) and skilled gist fashions with a various variety of gist tokens (1, 2, 5, or 10). Nonetheless, the outcomes confirmed that fashions have been usually insensitive to the variety of gist tokens, in some instances even exhibiting {that a} bigger variety of tokens was truly detrimental to efficiency. They, subsequently, used a single gist mannequin for the remainder of the experiments.
To evaluate the standard of the immediate compression, they calibrated efficiency towards a constructive management, which was successfully a regular instruction finetuning, which offered an higher certain on efficiency, and a unfavorable management the place the mannequin wouldn’t have entry to the instruction in any respect, leading to random gist tokens, which offered a decrease certain on efficiency. To check the outputs of their fashions to the constructive management and measure a win charge towards it, they requested ChatGPT to decide on which response was higher, explaining its reasoning. In addition they used a easy lexical overlap statistic known as ROUGE-L (a metric that measures similarities between generated textual content and human-written directions in open-ended instruction fine-tuning). A 50% win charge signifies that the mannequin is of comparable high quality to a mannequin that does no immediate compression.
The outcomes confirmed that on Seen directions, the gist fashions carried out very carefully to the constructive management fashions with 48.6% (LLaMA) and 50.8% (FLAN-T5) win charges. Extra importantly, they have been capable of present that the gist fashions had aggressive generalizations to unseen prompts, with 49.7% (LLaMA) and 46.2% (FLAN-T5) win charges. Solely on probably the most difficult Human break up they noticed slight drops in win charges (however nonetheless aggressive) with 45.8% (LLaMA) and 42.5% (FLAN-T5). The marginally worse efficiency of the FLAN-T5 and the actual failure instances introduced extra hypotheses to be examined in future papers.
The researchers additionally investigated the potential effectivity positive aspects that may be achieved via gisting, which was the first motivation for the examine. The outcomes have been extremely encouraging, with gist caching resulting in a 40% discount in FLOPs and 4-7% decrease wall clock time in comparison with unoptimized fashions. Whereas these enhancements have been discovered to be smaller for decoder-only language fashions, the researchers additionally demonstrated that gist fashions enabled a 26x compression of unseen prompts, offering appreciable further house within the enter context window.
General, these findings illustrate the numerous potential of gisting for enhancing each the effectiveness and effectivity of specialised language fashions. The authors additionally counsel a number of promising instructions for follow-up work on gisting. For instance, they stipulate that the most important compute and effectivity positive aspects from gisting will come from compressing longer prompts and that “gist pretraining” might enhance compression efficiency by first studying to compress arbitrary spans of pure language earlier than studying immediate compression.
Try the Paper and Github. Don’t neglect to affix our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra. You probably have any questions relating to the above article or if we missed something, be happy to electronic mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Nathalie Crevoisier holds a Bachelor’s and Grasp’s diploma in Physics from Imperial School London. She spent a 12 months finding out Utilized Information Science, Machine Studying, and Web Analytics on the Ecole Polytechnique Federale de Lausanne (EPFL) as a part of her diploma. Throughout her research, she developed a eager curiosity in AI, which led her to affix Meta (previously Fb) as a Information Scientist after graduating. Throughout her four-year tenure on the firm, Nathalie labored on numerous groups, together with Adverts, Integrity, and Office, making use of cutting-edge knowledge science and ML instruments to resolve advanced issues affecting billions of customers. Looking for extra independence and time to remain up-to-date with the newest AI discoveries, she just lately determined to transition to a contract profession.
[ad_2]
Source link
