


[ad_1]

Purchase a deep understanding of the interior workings of t-SNE by way of implementation from scratch in python
I have discovered that top-of-the-line methods to actually understanding any statistical algorithm or methodology is to manually implement it your self. On the flip aspect, coding these algorithms can generally be time consuming and an actual ache, and when any person else has already finished it, why would I need to spend my time doing it — appears inefficient, no? Each are honest factors, and I’m not right here to make an argument for one over the opposite.
This text is designed for readers who’re excited by understanding t-SNE by way of translation of the arithmetic within the original paper — by Laurens van der Maaten & Geoffrey Hinton — into python code implementation.[1] I discover these type of workout routines to be fairly illuminating into the interior workings of statistical algorithms/fashions and actually take a look at your underlying understanding and assumptions relating to these algorithms/fashions. You might be nearly assured to stroll away with a greater understanding you then had earlier than. On the very minimal, profitable implementation is at all times very satisfying!
This text will probably be accessible to people with any degree of publicity of t-SNE. Nonetheless, be aware just a few issues this publish undoubtedly is not:
- A strictly conceptual introduction and exploration of t-SNE, as there are many different nice sources on the market that do that; nonetheless, I will probably be doing my finest to attach the mathematical equations to their intuitive/conceptual counterparts at every stage of implementation.
- A complete dialogue into the functions & execs/cons of t-SNE, in addition to direct comparisons of t-SNE to different dimensionality discount methods. I’ll, nevertheless, briefly contact on these subjects all through this text, however will under no circumstances cowl this in-depth.
With out additional ado, let’s begin with a temporary introduction into t-SNE.
A Temporary Introduction to t-SNE
t-distributed stochastic neighbor embedding (t-SNE) is a dimensionality discount software that’s primarily utilized in datasets with a big dimensional characteristic house and permits one to visualise the information down, or undertaking it, right into a decrease dimensional house (normally 2-D). It’s particularly helpful for visualizing non-linearly separable information whereby linear strategies resembling Principal Component Analysis (PCA) would fail. Generalizing linear frameworks of dimensionality discount (resembling PCA) into non-linear approaches (resembling t-SNE) is also referred to as Manifold Learning. These strategies may be extraordinarily helpful for visualizing and understanding the underlying construction of a excessive dimensional, non-linear information set, and may be nice for disentangling and grouping collectively observations which are related within the high-dimensional house. For extra info on t-SNE and different manifold studying methods, the scikit-learn documentation is a superb useful resource. Moreover, to examine some cool areas t-SNE has seen functions, the Wikipedia page highlights a few of these areas with references to the work.
Let’s begin with breaking down the identify t-distributed stochastic neighbor embedding into its elements. t-SNE is an extension on stochastic neighbor embedding (SNE) introduced 6 years earlier on this paper by Geoffrey Hinton & Sam Roweis. So let’s begin there. The stochastic a part of the identify comes from the truth that the target perform shouldn’t be convex and thus completely different outcomes can come up from completely different initializations. The neighbor embedding highlights the character of the algorithm — optimally mapping the factors within the authentic high-dimensional house into the corresponding low-dimensional house whereas finest preserving the “neighborhood” construction of the factors. SNE is comprised of the next (simplified) steps:
- Receive the Similarity Matrix between Factors within the Unique Area: Compute the conditional chances for every datapoint j relative to every datapoint i. These conditional chances are calculated within the authentic high-dimensional house utilizing a Gaussian centered at i and tackle the next interpretation: the chance that i would decide j as its neighbor within the authentic house. This creates a matrix that represents similarities between the factors.
- Initialization: Select random beginning factors within the lower-dimensional house (say, 2-D) for every datapoint within the authentic house and compute new conditional chances equally as above on this new house.
- Mapping: Iteratively enhance upon the factors within the lower-dimensional house till the Kullback-Leibler divergences between all of the conditional chances is minimized. Primarily we’re minimizing the variations within the chances between the similarity matrices of the 2 areas in order to make sure the similarities are finest preserved within the mapping of the unique high-dimensional dataset to the low-dimensional dataset.
t-SNE improves upon SNE in two main methods:
- It minimizes the Kullback-Leibler divergences between the joint chances reasonably than the conditional chances. The authors seek advice from this as “symmetric SNE” b/c their method ensures that the joint chances p_ij = p_ji. This leads to a a lot better behaved value perform that’s simpler to optimize.
- It computes the similarities between factors utilizing a Student-t distribution w/ one diploma of freedom (additionally a Cauchy Distribution) reasonably than a Gaussian within the low-dimensional house (step 2 above). Right here we are able to see the place the “t” in t-SNE is coming from. This enchancment helps to alleviate the “crowding downside” highlighted by the authors and to additional enhance the optimization downside. This “crowding downside” may be envisioned as such: Think about we now have a 10-D house, the quantity of house out there in 2-D is not going to be ample to precisely seize these reasonably dissimilar factors in comparison with the quantity of house for close by factors relative to the quantity of house out there in a 10-D house. Extra merely, simply envision taking a 3-D house and projecting it right down to 2-D, the 3-D house can have rather more general house to mannequin the similarities relative to the projection down into 2-D. The Pupil-t distribution helps alleviate this downside by having heavier tails than the conventional distribution. See the original paper for a way more in-depth therapy of this downside.
If this didn’t all monitor instantly, that’s okay! I hope once we implement this in code, the items will all fall in to position. The principle takeaway is that this: t-SNE fashions similarities between datapoints within the high-dimensional house utilizing joint chances of “datapoints selecting others as its neighbor”, after which tries to search out one of the best mapping of those factors down into the low-dimensional house, whereas finest preserving the unique high-dimensional similarities.
Implementation from Scratch
Let’s now transfer on to understanding t-SNE by way of implementing the unique model of the algorithm as introduced within the paper by Laurens van der Maaten & Geoffrey Hinton. We are going to first begin with implementing algorithm 1 under step-by-step, which is able to cowl 95% of the primary algorithm. There are two extra enhancements the authors be aware: 1) Early Exaggeration & 2) Adaptive Studying Charges. We are going to solely talk about including within the early exaggeration as that’s most conducive in aiding the interpretation of the particular algorithms interior workings, because the adaptive studying charge is concentrated on enhancing the charges of convergence.

1. Inputs & Outputs
Following the unique paper, we will probably be utilizing the publicly out there MNIST dataset from OpenML with photos of handwritten digits from 0–9.[2] We can even randomly pattern 1000 photos from the dataset & cut back the dimensionality of the dataset utilizing Principal Part Evaluation (PCA) and maintain 30 elements. These are each to enhance computational time of the algorithm, because the code right here shouldn’t be optimized for pace, however reasonably for interpretability & studying.
from sklearn.datasets import fetch_openml
from sklearn.decomposition import PCA
import pandas as pd# Fetch MNIST information
mnist = fetch_openml('mnist_784', model=1, as_frame=False)
mnist.goal = mnist.goal.astype(np.uint8)
X_total = pd.DataFrame(mnist["data"])
y_total = pd.DataFrame(mnist["target"])
X_reduced = X_total.pattern(n=1000)
y_reduced = y_total.loc[X_total.index]
# PCA to maintain 30 elements
X = PCA(n_components=30).fit_transform(X_reduced)
This will probably be our X dataset with every row being a picture and every column being a characteristic, or principal part on this case (i.e. linear combos of the unique pixels):

We additionally might want to specify the fee perform parameters — perplexity — and the optimization parameters — iterations, studying charge, & momentum. We are going to maintain off on these for now and deal with them as they seem at every stage.
When it comes to output, recall that we search a the low-dimensional mapping of the unique dataset X. We will probably be mapping the unique house right into a 2 dimensional house all through this instance. Thus, our new output would be the 1000 photos now represented in a 2 dimensional house reasonably than the unique 30 dimensional house:

2. Compute Affinities/Similarities of X within the Unique Area
Now that we now have our inputs, step one is to compute the pairwise similarities within the authentic excessive dimensional house. That’s, for every picture i we compute the chance that i would decide picture j as its neighbor within the authentic house for every j. These chances are calculated by way of a standard distribution centered round every level after which are normalized to sum as much as 1. Mathematically, we now have:

Be aware that, in our case with n = 1000, these computations will end in a 1000 x 1000 matrix of similarity scores. Be aware we set p = 0 at any time when i = j b/c we’re modeling pairwise similarities. Nonetheless, chances are you’ll discover that we now have not talked about how σ is set. This worth is set for every commentary i by way of a grid search primarily based on the user-specified desired perplexity of the distributions. We are going to discuss this instantly under, however let’s first take a look at how we might code eq. (1) above:
def get_original_pairwise_affinities(X:np.array([]),
perplexity=10):'''
Perform to acquire affinities matrix.
'''
n = len(X)
print("Computing Pairwise Affinities....")
p_ij = np.zeros(form=(n,n))
for i in vary(0,n):
# Equation 1 numerator
diff = X[i]-X
σ_i = grid_search(diff, i, perplexity) # Grid Seek for σ_i
norm = np.linalg.norm(diff, axis=1)
p_ij[i,:] = np.exp(-norm**2/(2*σ_i**2))
# Set p = 0 when j = i
np.fill_diagonal(p_ij, 0)
# Equation 1
p_ij[i,:] = p_ij[i,:]/np.sum(p_ij[i,:])
# Set 0 values to minimal numpy worth (ε approx. = 0)
ε = np.nextafter(0,1)
p_ij = np.most(p_ij,ε)
print("Accomplished Pairwise Affinities Matrix. n")
return p_ij
Now earlier than we take a look at the outcomes of this code, let’s talk about how we decide the values of σ by way of the grid_search() perform. Given a specified worth of perplexity (which on this context may be loosely thought of because the variety of nearest neighbors for every level), we do a grid search over a spread of values of σ such that the next equation is as near equality as doable for every i:

the place H(P) is the Shannon entropy of P.

In our case, we’ll set perplexity = 10 and set the search house to be outlined by [0.01 * standard deviation of the norms for the difference between images i and j, 5 * standard deviation of the norms for the difference between images i and j] divided into 200 equal steps. Figuring out this, we are able to outline our grid_search() perform as follows:
def grid_search(diff_i, i, perplexity):'''
Helper perform to acquire σ's primarily based on user-specified perplexity.
'''
outcome = np.inf # Set first outcome to be infinity
norm = np.linalg.norm(diff_i, axis=1)
std_norm = np.std(norm) # Use commonplace deviation of norms to outline search house
for σ_search in np.linspace(0.01*std_norm,5*std_norm,200):
# Equation 1 Numerator
p = np.exp(-norm**2/(2*σ_search**2))
# Set p = 0 when i = j
p[i] = 0
# Equation 1 (ε -> 0)
ε = np.nextafter(0,1)
p_new = np.most(p/np.sum(p),ε)
# Shannon Entropy
H = -np.sum(p_new*np.log2(p_new))
# Get log(perplexity equation) as near equality
if np.abs(np.log(perplexity) - H * np.log(2)) < np.abs(outcome):
outcome = np.log(perplexity) - H * np.log(2)
σ = σ_search
return σ
Given these features, we are able to compute the affinity matrix by way of p_ij = get_original_pairwise_affinities(X) the place we receive the next matrix:

Be aware, the diagonal parts are set to ε ≈ 0 by development (at any time when i = j). Recall {that a} key extension of the t-SNE algorithm is to compute the joint chances reasonably than the conditional chances. That is computed merely as comply with:

Thus, we are able to outline a brand new perform:
def get_symmetric_p_ij(p_ij:np.array([])):'''
Perform to acquire symmetric affinities matrix utilized in t-SNE.
'''
print("Computing Symmetric p_ij matrix....")
n = len(p_ij)
p_ij_symmetric = np.zeros(form=(n,n))
for i in vary(0,n):
for j in vary(0,n):
p_ij_symmetric[i,j] = (p_ij[i,j] + p_ij[j,i]) / (2*n)
# Set 0 values to minimal numpy worth (ε approx. = 0)
ε = np.nextafter(0,1)
p_ij_symmetric = np.most(p_ij_symmetric,ε)
print("Accomplished Symmetric p_ij Matrix. n")
return p_ij_symmetric
Feeding in p_ij from above, we now have p_ij_symmetric = get_symmetric_p_ij(p_ij) the place we receive the next symmetric affinities matrix:

Now we now have accomplished the primary foremost step in t-SNE! We computed the symmetric affinity matrix within the authentic high-dimensional house. Earlier than we dive proper into the optimization stage, we’ll talk about the primary elements of the optimization downside within the subsequent two steps after which mix them into our for loop.
3. Pattern Preliminary Resolution & Compute Low Dimensional Affinity Matrix
Now we need to pattern a random preliminary resolution within the decrease dimensional house as follows:
def initialization(X: np.array([]),
n_dimensions = 2):return np.random.regular(loc=0,scale=1e-4,measurement=(len(X),n_dimensions))
the place calling y0 = initialization(X) we receive a random beginning resolution:

Now, we need to compute the affinity matrix on this decrease dimensional house. Nonetheless, recall that we do that using a student-t distribution w/ 1 diploma of freedom:

Once more, we set q = 0 at any time when i = j. Be aware this equation differs from eq. (1) in that the denominator is over all i and thus symmetric by development. Placing this into code, we receive:
def get_low_dimensional_affinities(Y:np.array([])):
'''
Receive low-dimensional affinities.
'''n = len(Y)
q_ij = np.zeros(form=(n,n))
for i in vary(0,n):
# Equation 4 Numerator
diff = Y[i]-Y
norm = np.linalg.norm(diff, axis=1)
q_ij[i,:] = (1+norm**2)**(-1)
# Set p = 0 when j = i
np.fill_diagonal(q_ij, 0)
# Equation 4
q_ij = q_ij/q_ij.sum()
# Set 0 values to minimal numpy worth (ε approx. = 0)
ε = np.nextafter(0,1)
q_ij = np.most(q_ij,ε)
return q_ij
Right here we’re searching for a 1000 x 1000 affinity matrix however now within the decrease dimensional house. Calling q_ij = get_low_dimensional_affinities(y0) we receive:

4. Compute Gradient of the Value Perform
Recall, our value perform is the Kullback-Leibler divergence between joint chance distributions within the excessive dimensional house and low dimensional house:

Intuitively, we need to decrease the distinction within the affinity matrices p_ij and q_ij thereby finest preserving the “neighborhood” construction of the unique house. The optimization downside is solved utilizing gradient descent, however first let’s take a look at computing the gradient for the fee perform above. The authors derive (see appendix A of the paper) the gradient of the fee perform as follows:

In python, we now have:
def get_gradient(p_ij: np.array([]),
q_ij: np.array([]),
Y: np.array([])):
'''
Receive gradient of value perform at present level Y.
'''n = len(p_ij)
# Compute gradient
gradient = np.zeros(form=(n, Y.form[1]))
for i in vary(0,n):
# Equation 5
diff = Y[i]-Y
A = np.array([(p_ij[i,:] - q_ij[i,:])])
B = np.array([(1+np.linalg.norm(diff,axis=1))**(-1)])
C = diff
gradient[i] = 4 * np.sum((A * B).T * C, axis=0)
return gradient
Feeding within the related arguments, we receive the gradient at y0 by way of gradient = get_gradient(p_ij_symmetric,q_ij,y0) with the corresponding output:

Now, we now have all of the items with the intention to remedy the optimization downside!
5. Iterate & Optimize the Low-Dimensional Mapping
To be able to replace our low-dimensional mapping, we use gradient descent with momentum as outlined by the authors:

the place η is our learning rate and α(t) is our momentum time period as a perform of time. The training charge controls the step measurement at every iteration and the momentum time period permits the optimization algorithm to realize inertia within the easy route of the search house, whereas not being slowed down by the noisy components of the gradient. We are going to set η=200 for our instance and can repair α(t)=0.5 if t < 250 and α(t)=0.8 in any other case. We now have all of the elements crucial above to compute to the replace rule, thus we are able to now run our optimization over a set variety of iterations T (we’ll set T=1000).
Earlier than we arrange for iteration scheme, let’s first introduce the enhancement the authors seek advice from as “early exaggeration”. This time period is a continuing that scales the unique matrix of affinities p_ij. What this does is it locations extra emphasis on modeling the very related factors (excessive values in p_ij from the unique house) within the new house early on and thus forming “clusters” of extremely related factors. The early exaggeration is positioned on originally of the iteration scheme (T<250) after which turned off in any other case. Early exaggeration will probably be set to 4 in our case. We are going to see this in motion in our visible under following implementation.
Now, placing the entire items collectively for the algorithm, we now have the next:
def tSNE(X: np.array([]),
perplexity = 10,
T = 1000,
η = 200,
early_exaggeration = 4,
n_dimensions = 2):n = len(X)
# Get authentic affinities matrix
p_ij = get_original_pairwise_affinities(X, perplexity)
p_ij_symmetric = get_symmetric_p_ij(p_ij)
# Initialization
Y = np.zeros(form=(T, n, n_dimensions))
Y_minus1 = np.zeros(form=(n, n_dimensions))
Y[0] = Y_minus1
Y1 = initialization(X, n_dimensions)
Y[1] = np.array(Y1)
print("Optimizing Low Dimensional Embedding....")
# Optimization
for t in vary(1, T-1):
# Momentum & Early Exaggeration
if t < 250:
α = 0.5
early_exaggeration = early_exaggeration
else:
α = 0.8
early_exaggeration = 1
# Get Low Dimensional Affinities
q_ij = get_low_dimensional_affinities(Y[t])
# Get Gradient of Value Perform
gradient = get_gradient(early_exaggeration*p_ij_symmetric, q_ij, Y[t])
# Replace Rule
Y[t+1] = Y[t] - η * gradient + α * (Y[t] - Y[t-1]) # Use damaging gradient
# Compute present worth of value perform
if t % 50 == 0 or t == 1:
value = np.sum(p_ij_symmetric * np.log(p_ij_symmetric / q_ij))
print(f"Iteration {t}: Worth of Value Perform is {value}")
print(f"Accomplished Embedding: Ultimate Worth of Value Perform is {np.sum(p_ij_symmetric * np.log(p_ij_symmetric / q_ij))}")
resolution = Y[-1]
return resolution, Y
Calling resolution, Y = tSNE(X) we receive the next output :

the place resolution is the ultimate 2-D mapping and Y is our mapped 2-D values at every step of the iteration. Plotting the evolution of Y the place Y[-1] is our ultimate 2-D mapping, we receive (be aware how the algorithm behaves with early exaggeration on and off):
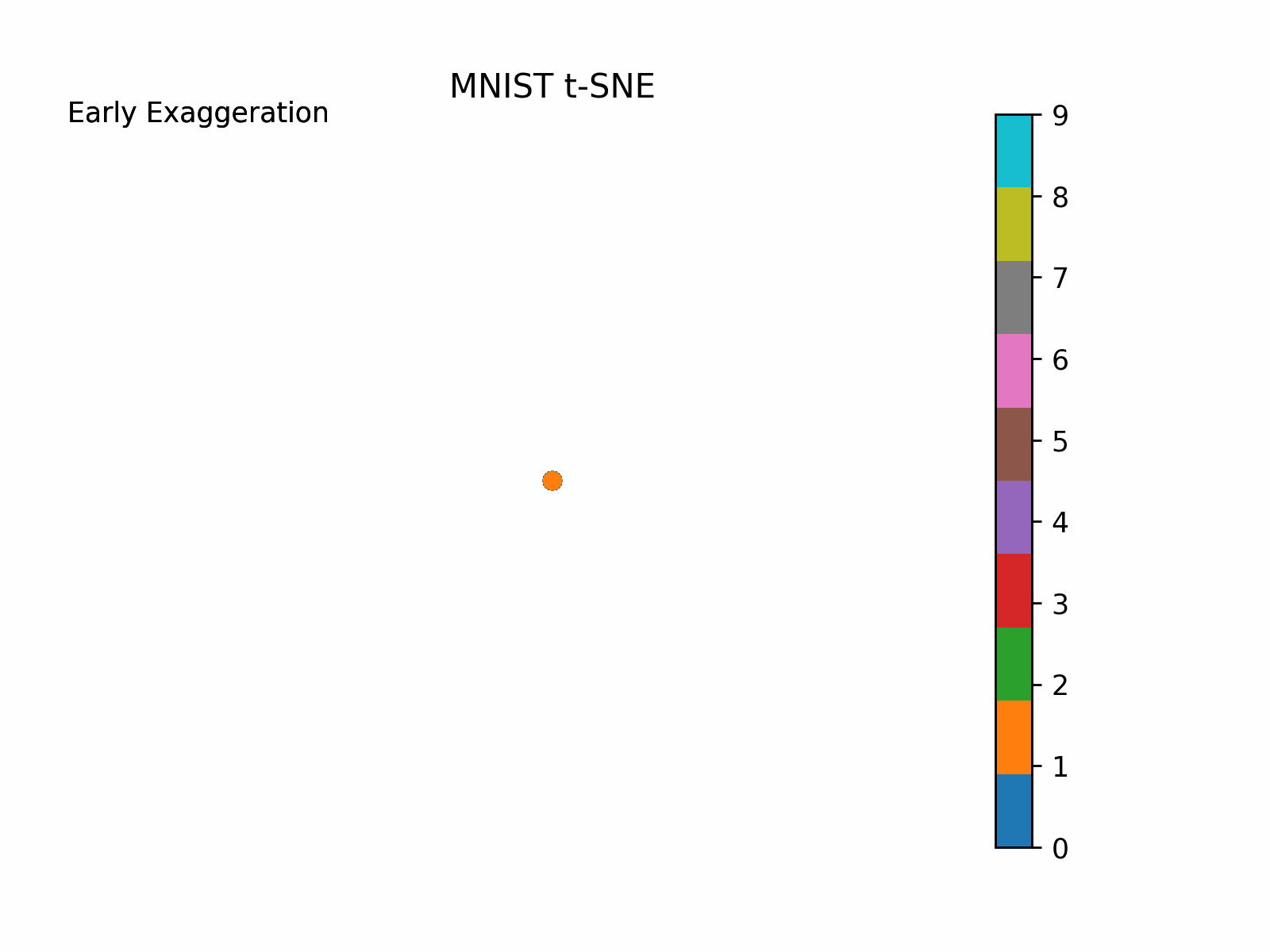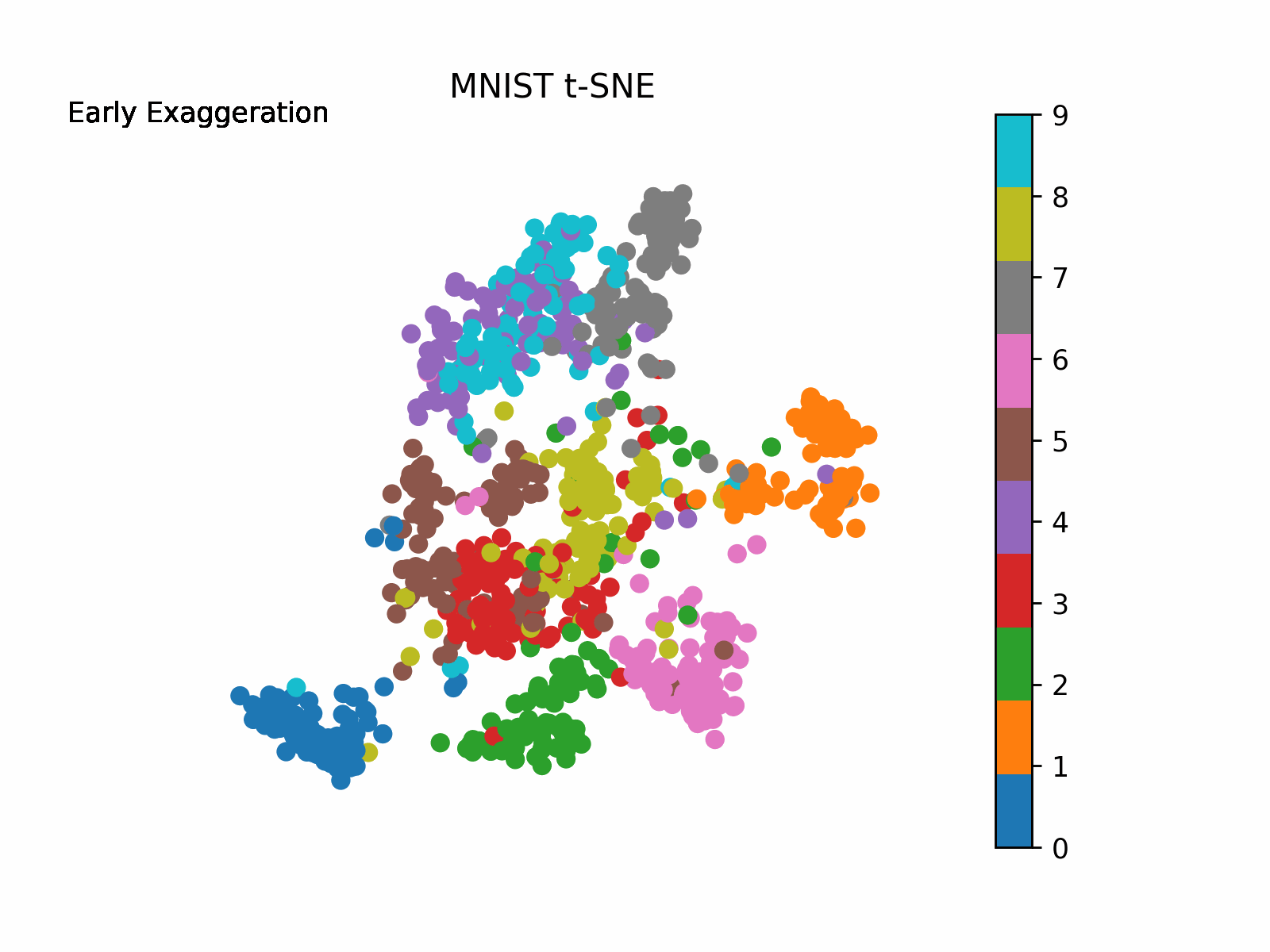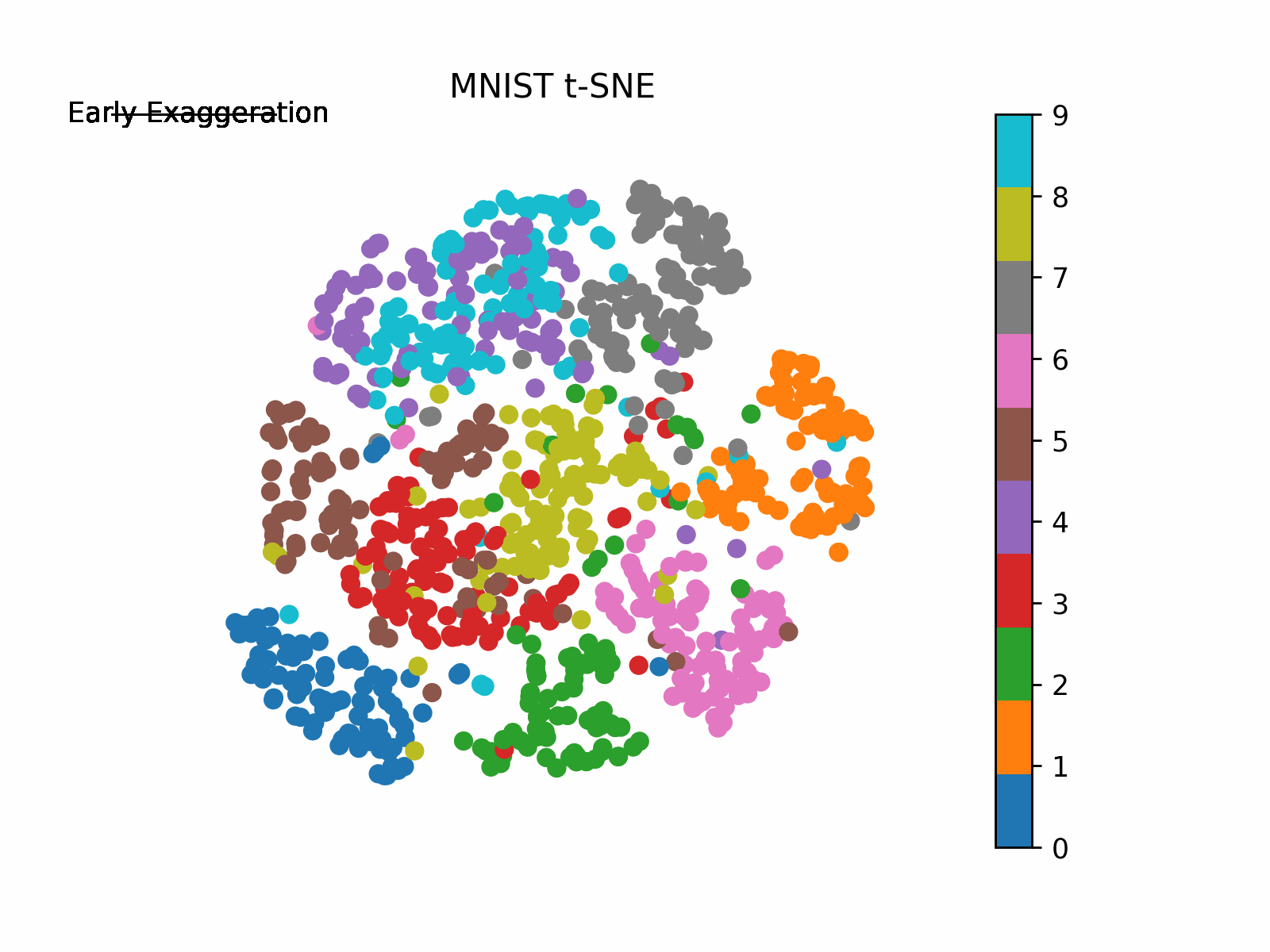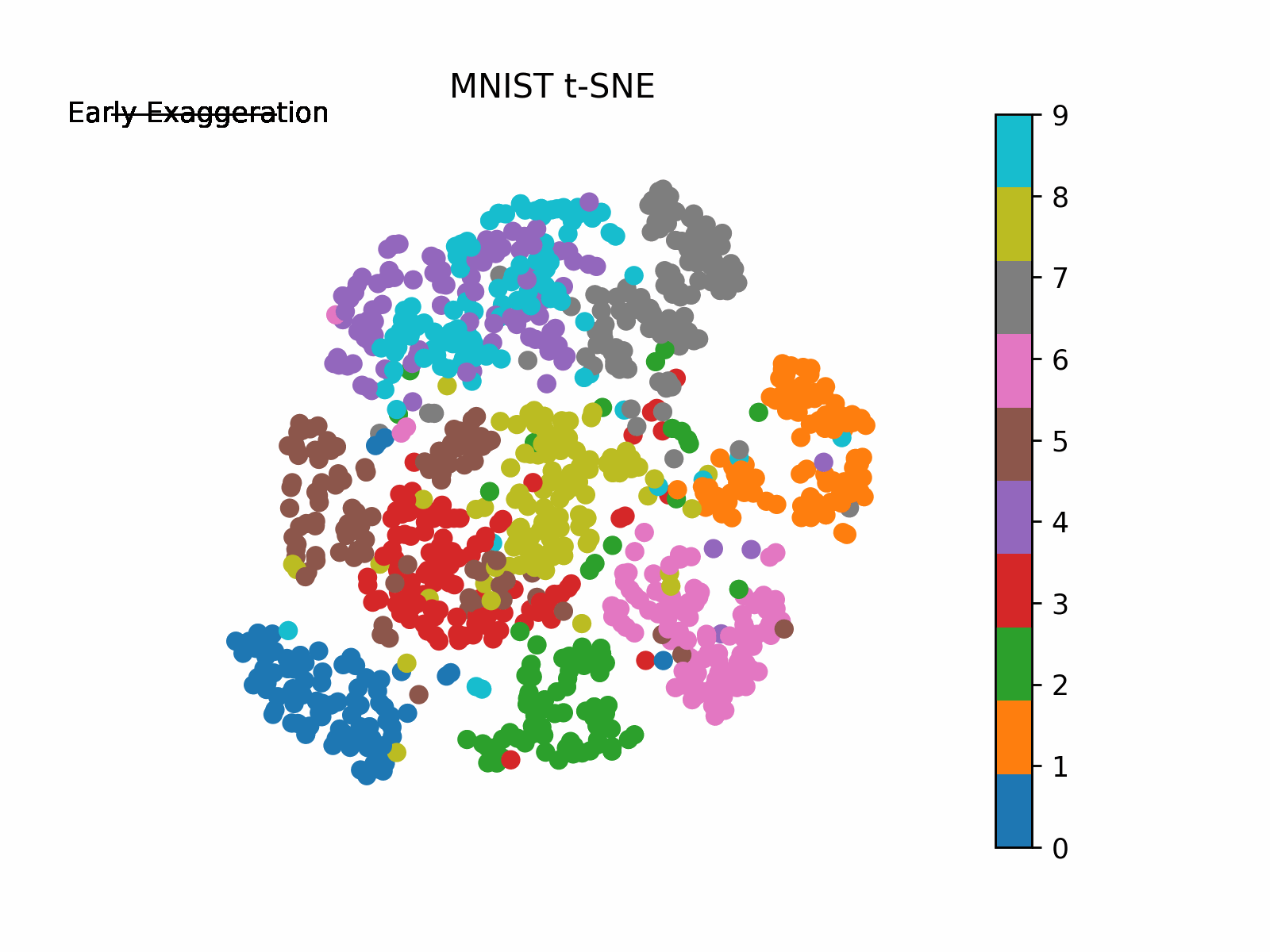
I like to recommend enjoying round with completely different values of the parameters (i.e., perplexity, studying charge, early exaggeration, and many others.) to see how the answer differs (See the original paper and the scikit-learn documentation for guides on utilizing these parameters).
[ad_2]
Source link
