

[ad_1]
To succeed with generative AI at scale, we have to give LLMs the diligence they deserve. Enter RAG and advantageous tuning.

The hype round LLMs is unprecedented, nevertheless it’s warranted. From AI-generated photos of the Pope in head-to-toe Balenciaga to customer support agents without pulses, generative AI has the potential to remodel society as we all know it.
And in some ways, LLMs are going to make information engineers extra priceless — and that’s thrilling!
Nonetheless, it’s one factor to indicate your boss a cool demo of an information discovery instrument or text-to-SQL generator — it’s one other factor to make use of it along with your firm’s proprietary information, or much more regarding, buyer information.
All too typically, firms rush into constructing AI functions with little foresight into the monetary and organizational influence of their experiments. And it’s not their fault — executives and boards are guilty for a lot of the “hurry up and go” mentality round this (and most) new applied sciences. (Bear in mind NFTs?).
For AI — notably generative AI — to succeed, we have to take a step again and bear in mind how any software program turns into enterprise prepared. To get there, we are able to take cues from different industries to know what enterprise readiness seems like and apply these tenets to generative AI.
For my part, enterpris-ready generative AI have to be:
- Safe & non-public: Your AI utility should be sure that your information is safe, non-public, and compliant, with correct entry controls. Suppose: SecOps for AI.
- Scalable: your AI utility have to be straightforward to deploy, use, and improve, in addition to be cost-efficient. You wouldn’t buy — or construct — an information utility if it took months to deploy, was tedious to make use of, and unattainable to improve with out introducing one million different points. We shouldn’t deal with AI functions any in another way.
- Trusted. Your AI utility ought to be sufficiently dependable and constant. I’d be hard-pressed to discover a CTO who’s prepared to wager her profession on shopping for or constructing a product that produces unreliable code or generates insights which are haphazard and deceptive.
With these guardrails in thoughts, it’s time we begin giving generative AI the diligence it deserves. Nevertheless it’s not really easy…
Put merely, the underlying infrastructure to scale, safe, and function LLM functions isn’t there but.
Not like most functions, AI may be very a lot a black field. We *know* what we’re placing in (uncooked, typically unstructured information) and we *know* what we’re getting out, however we don’t know the way it acquired there. And that’s tough to scale, safe and function.
Take GPT-4 for instance. While GPT-4 blew GPT 3.5 out of the water when it got here to some duties (like taking SAT and AP Calculus AB examination), a few of its outputs have been riddled with hallucinations or lacked essential context to adequately accomplish these duties. Hallucinations are attributable to a variety of factors from poor embeddings to data cutoff, and continuously have an effect on the standard of responses generated by publicly obtainable or open LLMs skilled on data scraped from the web, which account for many fashions.
To cut back hallucinations and much more importantly — to reply significant enterprise questions — firms want to reinforce LLMs with their very own proprietary information, which incorporates essential enterprise context. As an example, if a buyer asks an airline chatbot to cancel their ticket, the mannequin would wish to entry details about the shopper, about their previous transactions, about cancellation insurance policies and probably different items of data. All of those at present exist in databases and information warehouses.
With out that context, an AI can solely purpose with the general public data, sometimes printed on the Web, on which it was initially skilled. And right here lies the conundrum — exposing proprietary Enterprise information and incorporating it into enterprise workflows or buyer experiences nearly all the time requires stable safety, scalability and reliability.
In terms of making AI enterprise prepared, probably the most crucial elements come on the very finish of the LLM improvement course of: retrieval augmented generation (RAG) and fine tuning.
It’s vital to notice, nonetheless, that RAG and advantageous tuning should not mutually unique approaches, and ought to be leveraged — oftentimes in tandem — primarily based in your particular wants and use case.
When to make use of RAG

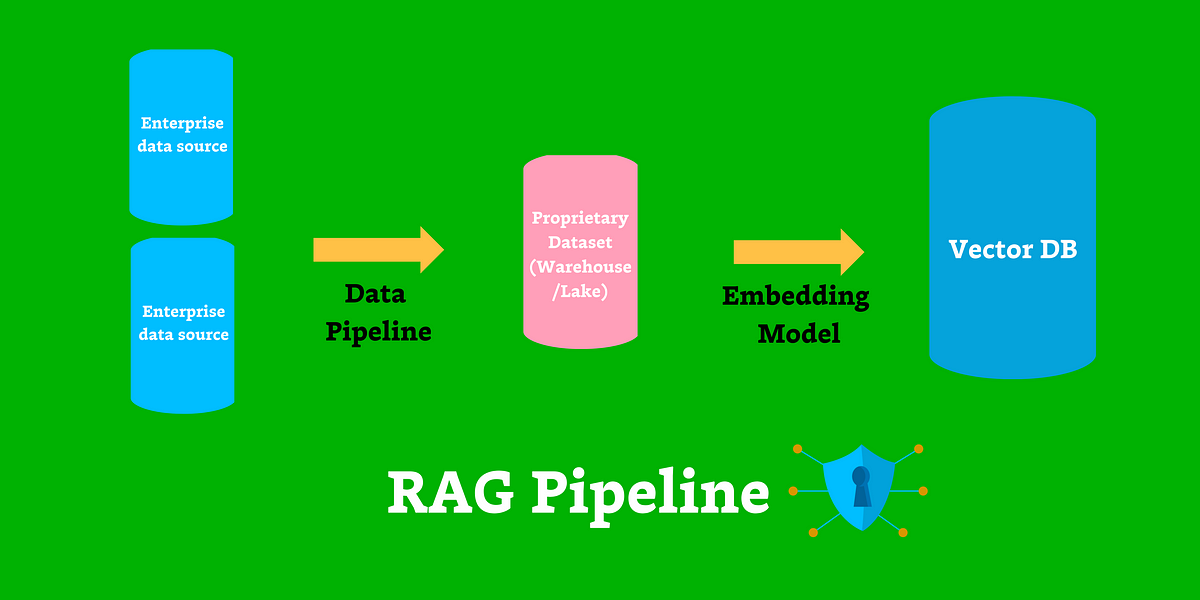
RAG is a framework that improves the standard of LLM outputs by giving the mannequin entry to a database whereas making an attempt to reply a immediate. The database — being a curated and trusted physique of doubtless proprietary information — permits the mannequin to include up-to-date and dependable data into its responses and reasoning. This strategy is finest fitted to AI functions that require further contextual data, equivalent to buyer assist responses (like our flight cancellations instance) or semantic search in your organization’s enterprise communication platform.
RAG functions are designed to retrieve related data from data sources earlier than producing a response, making them effectively fitted to querying structured and unstructured information sources, equivalent to vector databases and have shops. By retrieving data to extend the accuracy and reliability of LLMs at output era, RAG can also be extremely efficient at each reducing hallucinations and conserving coaching prices down. RAG additionally affords groups a stage of transparency since you recognize the supply of the information that you just’re piping into the mannequin to generate new responses.
One factor to notice about RAG architectures is that their efficiency closely depends in your means to construct efficient information pipelines that make enterprise information obtainable to AI fashions.
When to make use of advantageous tuning

High-quality tuning is the method of coaching an present LLM on a smaller, task-specific and labeled dataset, adjusting mannequin parameters and embeddings primarily based on this new information. High-quality tuning depends on pre-curated datasets that inform not simply data retrieval, however the nuance and terminologies of the area for which you’re trying to generate outputs.
In our expertise, advantageous tuning is finest fitted to domain-specific conditions, like responding to detailed prompts in a distinct segment tone or model, i.e. a authorized transient or buyer assist ticket. It is usually an awesome match for overcoming data bias and different limitations, equivalent to language repetitions or inconsistencies. Several studies over the previous yr have proven that fine-tuned fashions considerably outperform off-the-shelf variations of GPT-3 and different publically obtainable fashions. It has been established that for a lot of use circumstances, a fine-tuned small mannequin can outperform a big basic function mannequin — making advantageous tuning a believable path for price effectivity in sure circumstances.
Not like RAG, advantageous tuning typically requires much less information however on the expense of extra time and compute sources. Moreover, advantageous tuning operates like a black field; because the mannequin internalizes the brand new information set, it turns into difficult to pinpoint the reasoning behind new responses and hallucinations stay a significant concern.
High-quality tuning — like RAG architectures — requires constructing efficient information pipelines that make (labeled!) enterprise information obtainable to the advantageous tuning course of. No straightforward feat.

It’s vital to do not forget that RAG and advantageous tuning should not mutually unique approaches, have various strengths and weaknesses, and can be utilized collectively. Nevertheless, for the overwhelming majority of use circumstances, RAG seemingly makes probably the most sense in terms of delivering enterprise Generative AI functions.
Right here’s why:
- RAG safety and privateness is extra manageable: Databases have built-in roles and safety in contrast to AI fashions, and it’s fairly well-understood who sees what as a consequence of normal entry controls. Additional, you’ve got extra management over what information is utilized by accessing a safe and personal corpus of proprietary information. With advantageous tuning, any information included within the coaching set is uncovered to all customers of the appliance, with no apparent methods to handle who sees what. In lots of sensible eventualities — particularly in terms of buyer information — not having that management is a no-go.
- RAG is extra scalable: RAG is cheaper than advantageous tuning as a result of the latter includes updating the entire parameters of a big mannequin, requiring in depth computing energy. Additional, RAG doesn’t require labeling and crafting coaching units, a human-intensive course of that may take weeks and months to excellent per mannequin.
- RAG makes for extra trusted outcomes. Merely put, RAG works higher with dynamic information, producing deterministic outcomes from a curated information set of up-to-date information. Since advantageous tuning largely acts like a black field, it may be tough to pinpoint how the mannequin generated particular outcomes, reducing belief and transparency. With advantageous tuning, hallucinations and inaccuracies are doable and even seemingly, since you might be counting on the mannequin’s weights to encode enterprise data in a lossy method.
In our humble opinion, enterprise prepared AI will primarily depend on RAG, with advantageous tuning concerned in additional nuanced or area particular use circumstances. For the overwhelming majority of functions, advantageous tuning can be a nice-to-have for area of interest eventualities and are available into play way more continuously as soon as the trade can cut back price and sources essential to run AI at scale.
No matter which one you utilize, nonetheless, your AI utility improvement goes to require pipelines that feed these fashions with firm information by way of some information retailer (be it Snowflake, Databricks, a standalone vector database like Pinecone, or one thing else solely). On the finish of the day, if generative AI is utilized in inner processes to extract evaluation and perception from unstructured information — it is going to be utilized in… drumroll… an information pipeline.
Within the early 2010s, machine learning was touted as a magic algorithm that carried out miracles on command if you happen to gave its options the right weights. What sometimes improved ML efficiency, nonetheless, was investing in top quality options and particularly — information high quality.
Likewise, to ensure that enterprise AI to work, it’s worthwhile to deal with the standard and reliability of the information on which generative fashions rely — seemingly by way of a RAG structure.
Because it depends on dynamic, typically up-to-the-minute information, RAG requires data observability to reside as much as its enterprise prepared expectations. Knowledge can break for any variety of causes, equivalent to misformatted third-party information, defective transformation code or a failed Airflow job. And it all the time does.
Knowledge observability offers groups the flexibility to observe, alert, triage, and resolve information or pipeline points at scale throughout your total information ecosystem. For years, it’s been vital layer of the fashionable information stack; as RAG grows in significance and AI matures, observability will emerge as a crucial associate in LLM improvement.
The one manner RAG — and enterprise AI — work is if you happen to can belief the information. To realize this, groups want a scalable, automated manner to make sure reliability of information, in addition to an enterprise-grade method to establish root trigger and resolve points rapidly — earlier than they influence the LLMs they service.
The infrastructure and technical roadmap for AI tooling is being developed as we converse, with new startups rising daily to unravel numerous issues, and trade behemoths claiming that they, too, are tackling these challenges. In terms of incorporating enterprise information into AI, I see three major horses on this race.
The primary horse: vector databases. Pinecone, Weaviate, and others are making a reputation for themselves because the must-have database platforms to energy RAG architectures. Whereas these applied sciences present quite a lot of promise, they do require spinning up a brand new piece of the stack and creating workflows to assist it from a safety, scalability and reliability standpoint.
The second horse: hosted variations of fashions constructed by third-party LLM builders like OpenAI or Anthropic. At present, most groups get their generative AI repair by way of APIs with these up-and-coming AI leaders as a consequence of ease of use. Plug into the OpenAI API and leverage a innovative mannequin in minutes? Depend us in. This strategy works nice out-of-the-box if you happen to want the mannequin to generate code or remedy well-known, non-specific prompts primarily based on public data. In case you do need to incorporate proprietary data into these fashions, you can use the built-in fine tuning or RAG options that these platforms present.
And at last, the third horse: the modern data stack. Snowflake and Databricks have already introduced that they’re embedding vector databases into their platforms in addition to different tooling to assist incorporate information that’s already saved and processed on these platforms into LLMs. This makes quite a lot of sense for a lot of, and permits information groups charged with AI initiatives to leverage the instruments they already use. Why reinvent the wheel when you’ve got the foundations in place? To not point out the potential for with the ability to simply be part of conventional relational information with vector information… Like the 2 different horses, there are some downsides to this strategy: Snowflake Cortex, Lakehouse AI, and different MDS + AI merchandise are nascent and require some upfront funding to include vector search and mannequin coaching into your present workflows. For a extra in-depth take a look at this strategy, I encourage you to take a look at Meltano’s pertinent piece on why the most effective LLM stack often is the one sitting proper in entrance of you.
Whatever the horse we select, priceless enterprise questions can’t be answered by a mannequin skilled on the information that’s on the Web. It must have context from inside the firm. And by offering this context in a safe, scalable, and trusted manner, we are able to obtain enterprise prepared AI.
For AI to reside as much as this potential, information and AI groups have to deal with LLM augmentation with the diligence they deserve and make safety, scalability and reliability a first-class consideration. Whether or not your use case requires RAG or advantageous tuning — or each — you’ll want to make sure that your information stack foundations are in place to maintain prices low, efficiency constant, and reliability excessive.
Knowledge must be safe and personal; LLM deployment must be scalable; and your outcomes have to be trusted. Retaining a gradual pulse on information high quality by way of observability are crucial to those calls for.
The most effective a part of this evolution from siloed X demos to enterprise prepared AI? RAG offers information engineers the most effective seat on the desk in terms of proudly owning and driving ROI for generative AI investments.
I’m prepared for enterprise prepared AI. Are you?
Lior Gavish contributed to this text.
Join with Barr on LinkedIn for extra insights on information, AI, and the way forward for information belief.
[ad_2]
Source link
