


[ad_1]

“You shall know a phrase by the corporate it retains!”
—John Rupert Firth
Wouldn’t or not it’s unimaginable if computer systems might begin understanding Shakespeare? Or write fiction like J.Ok Rowling? This was unimaginable a number of years again. Latest developments in Natural Language Processing (NLP) and Natural Language Generation (NLG) have skyrocketed the power of computer systems to raised perceive text-based content material.
To know and generate textual content, NLP-powered techniques should have the ability to acknowledge phrases, grammar, and an entire lot of language nuances. For computer systems, that is simpler mentioned than performed as a result of they will solely comprehend numbers.
To bridge the hole, NLP consultants developed a method referred to as phrase embeddings that convert phrases into their numerical representations. As soon as transformed, NLP algorithms can simply digest these realized representations to course of textual info.
Phrase embeddings map the phrases as real-valued numerical vectors. It does so by tokenizing every phrase in a sequence (or sentence) and changing them right into a vector house. Phrase embeddings goal to seize the semantic which means of phrases in a sequence of textual content. It assigns related numerical representations to phrases which have related meanings.
Let’s take a look at a few of the most promising phrase embedding methods in NLP.
TF-IDF is a machine studying (ML) algorithm based mostly on a statistical measure of discovering the relevance of phrases within the textual content. The textual content could be within the type of a doc or numerous paperwork (corpus). It’s a mixture of two metrics: Time period Frequency (TF) and Inverse Doc Frequency (IDF).
TF rating is predicated on the frequency of phrases in a doc. Phrases are counted for his or her variety of occurrences within the paperwork. TF is calculated by dividing the variety of occurrences of a phrase (i) by the whole quantity (N) of phrases within the doc (j).
TF (i) = log (frequency (i,j)) / log (N (j))
IDF rating calculates the rarity of the phrases. It is necessary as a result of TF offers extra weightage to phrases that happen extra ceaselessly. Nevertheless, phrases which are not often used within the corpus could maintain important info. IDF captures this info. It may be calculated by dividing the whole quantity (N) of paperwork (d) by the variety of paperwork containing the phrase (i).
IDF (i) = log (N (d) / frequency (d,i))
The log is taken within the above formulation to dampen the impact of huge scores for TF and IDF. The ultimate TF-IDF rating is calculated by multiplying TF and IDF scores.
TF-IDF algorithm is utilized in fixing easier ML and NLP issues. It’s higher used for info retrieval, key phrase extraction, cease phrases (like ‘a’, ‘the’, ‘are’, ‘is’) elimination, and fundamental text analysis. It can’t seize the semantic which means of phrases in a sequence effectively.
Developed by Tomas Mikolov and different researchers at Google in 2013, Word2Vec is a phrase embedding approach for fixing superior NLP issues. It may possibly iterate over a big corpus of textual content to study associations or dependencies amongst phrases.
Word2Vec finds similarities amongst phrases by utilizing the cosine similarity metric. If the cosine angle is 1, meaning phrases are overlapping. If the cosine angle is 90, meaning phrases are unbiased or maintain no contextual similarity. It assigns related vector representations to related phrases.
Word2Vec presents two neural network-based variants: Steady Bag of Phrases (CBOW) and Skip-gram. In CBOW, the neural community mannequin takes numerous phrases as enter and predicts the goal phrase that’s intently associated to the context of the enter phrases. However, the Skip-gram structure takes one phrase as enter and predicts its intently associated context phrases.
CBOW is fast and finds higher numerical representations for frequent phrases, whereas Skip Gram can effectively signify uncommon phrases. Word2Vec fashions are good at capturing semantic relationships amongst phrases. For instance, the connection between a rustic and its capital, like Paris is the capital of France and Berlin is the capital of Germany. It’s best fitted to performing semantic analysis, which has software in advice techniques and information discovery.
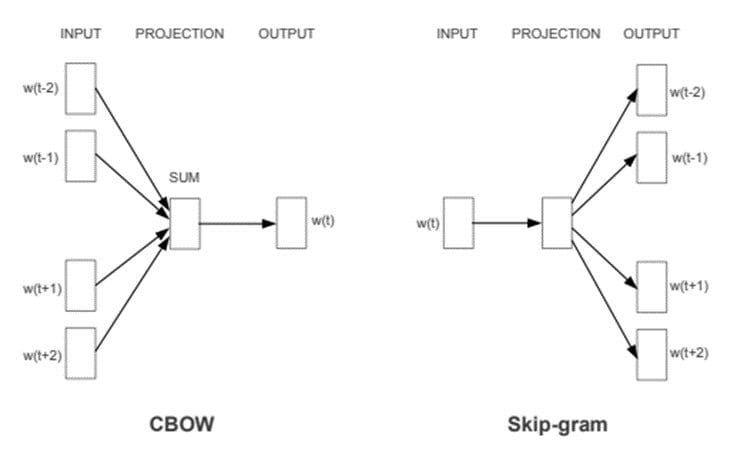
CBOW & Skip-gram architectures. Picture Supply: Word2Vec paper.
Developed by Jeffery Pennington and different researchers at Stanford, GloVe extends the work of Word2Vec to seize world contextual info in a textual content corpus by calculating a worldwide word-word co-occurrence matrix.
Word2Vec solely captures the native context of phrases. Throughout coaching, it solely considers neighboring phrases to seize the context. GloVe considers the complete corpus and creates a big matrix that may seize the co-occurrence of phrases inside the corpus.
GloVe combines the benefits of two-word vector studying strategies: matrix factorization like latent semantic analysis (LSA) and native context window technique like Skip-gram. The GloVe approach has an easier least square value or error operate that reduces the computational value of coaching the mannequin. The ensuing phrase embeddings are totally different and improved.
GloVe performs considerably higher in phrase analogy and named entity recognition issues. It’s higher than Word2Vec in some duties and competes in others. Nevertheless, each methods are good at capturing semantic info inside a corpus.

GloVe phrase vectors capturing phrases with related semantics. Picture Supply: Stanford GloVe.
Introduced by Google in 2019, BERT belongs to a category of NLP-based language algorithms often called transformers. BERT is a large pre-trained deeply bidirectional encoder-based transformer mannequin that is available in two variants. BERT-Base has 110 million parameters, and BERT-Massive has 340 million parameters.
For producing phrase embeddings, BERT depends on an attention mechanism. It generates high-quality context-aware or contextualized phrase embeddings. Through the coaching course of, embeddings are refined by passing by every BERT encoder layer. For every phrase, the eye mechanism captures phrase associations based mostly on the phrases on the left and the phrases on the appropriate. Phrase embeddings are additionally positionally encoded to maintain observe of the sample or place of every phrase in a sentence.
BERT is extra superior than any of the methods mentioned above. It creates higher phrase embeddings because the mannequin is pre-trained on large phrase corpus and Wikipedia datasets. BERT could be improved by fine-tuning the embeddings on task-specific datasets.
Although, BERT is most fitted to language translation duties. It has been optimized for a lot of different purposes and domains.
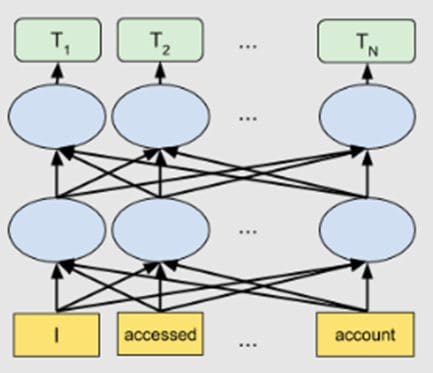
Bidirectional BERT structure. Picture Supply: Google AI Blog.
With developments in NLP, phrase embedding methods are additionally bettering. There are lots of NLP duties that don’t require superior embedding methods. Many can carry out equally properly with easy phrase embedding methods. The choice of a phrase embedding approach have to be based mostly on cautious experimentations and task-specific necessities. Tremendous-tuning the phrase embedding fashions can enhance the accuracy considerably.
On this article, we have now given a high-level overview of varied phrase embedding algorithms. Let’s summarize them beneath:
| Phrase Embedding Approach | Principal Traits | Use Instances |
| TF-IDF | Statistical technique to seize the relevance of phrases w.r.t the corpus of textual content. It doesn’t seize semantic phrase associations. | Higher for info retrieval and key phrase extraction in paperwork. |
| Word2Vec | Neural network-based CBOW and Skip-gram architectures, higher at capturing semantic info. | Helpful in semantic evaluation process. |
| GloVe | Matrix factorization based mostly on world word-word co-occurrence. It solves the native context limitations of Word2Vec. | Higher at phrase analogy and named-entity recognition duties. Comparable outcomes with Word2Vec in some semantic evaluation duties whereas higher in others. |
| BERT | Transformer-based consideration mechanism to seize high-quality contextual info. | Language translation, question-answering system. Deployed in Google Search engine to grasp search queries. |
References
- https://www.ibm.com/cloud/learn/natural-language-processing
- https://www.techopedia.com/definition/33012/natural-language-generation-nlg
- https://arxiv.org/abs/1301.3781
- https://www.machinelearningplus.com/nlp/cosine-similarity/
- https://www.ibm.com/cloud/learn/neural-networks
- https://www.expert.ai/blog/natural-language-process-semantic-analysis-definition/
- https://nlp.stanford.edu/pubs/glove.pdf
- https://medium.com/swlh/co-occurrence-matrix-9cacc5dd396e
- https://blog.marketmuse.com/glossary/latent-semantic-analysis-definition/
- https://www.investopedia.com/terms/l/least-squares-method.asp
- https://www.expert.ai/blog/entity-extraction-work/
- https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
- https://arxiv.org/abs/1810.04805
- https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
- https://www.analyticsvidhya.com/blog/2019/11/comprehensive-guide-attention-mechanism-deep-learning/
Neeraj Agarwal is a founding father of Algoscale, a knowledge consulting firm protecting information engineering, utilized AI, information science, and product engineering. He has over 9 years of expertise within the area and has helped a variety of organizations from start-ups to Fortune 100 corporations ingest and retailer huge quantities of uncooked information to be able to translate it into actionable insights for higher decision-making and quicker enterprise worth.
[ad_2]
Source link
