


[ad_1]

Picture by Mikechie Esparagoza
Day by day, we’re dealing more often than not with unlabeled textual content and supervised studying algorithms can’t be used in any respect to extract info from the info. A subfield of pure language can reveal the underlying construction in giant quantities of textual content. This self-discipline known as Matter Modeling, that’s specialised in extracting matters from textual content.
On this context, typical approaches, like Latent Dirichlet Allocation and Non-Unfavourable Matrix Factorization, demonstrated to not seize properly the relationships between phrases since they’re based mostly on bag-of-word.
For that reason, we’re going to concentrate on two promising approaches, Top2Vec and BERTopic, that handle these drawbacks by exploiting pre-trained language fashions to generate matters. Let’s get began!
Top2Vec is a mannequin able to detecting mechanically matters from the textual content by utilizing pre-trained phrase vectors and creating significant embedded matters, paperwork and phrase vectors.
On this method, the process to extract matters might be cut up into totally different steps:
- Create Semantic Embedding: collectively embedded doc and phrase vectors are created. The concept is that related paperwork needs to be nearer within the embedding house, whereas dissimilar paperwork needs to be distant between them.
- Cut back the dimensionality of the doc embedding: The applying of the dimensionality discount method is vital to protect a lot of the variability of the embedding of paperwork whereas decreasing the excessive dimensional house. Furthermore, it permits to identification of dense areas, during which every level represents a doc vector. UMAP is the everyday dimensionality discount method chosen on this step as a result of it’s capable of protect the native and international construction of the high-dimensional knowledge.
- Determine clusters of paperwork: HDBScan, a density-based clustering method, is utilized to search out dense areas of comparable paperwork. Every doc is assigned as noise if it’s not in a dense cluster, or a label if it belongs to a dense space.
- Calculate centroids within the authentic embedding house: The centroid is computed by contemplating the excessive dimensional house, as a substitute of the lowered embedding house. The basic technique consists in calculating the arithmetic imply of all of the doc vectors belonging to a dense space, obtained within the earlier step with HDBSCAN. On this method, a subject vector is generated for every cluster.
- Discover phrases for every subject vector: the closest phrase vectors to the doc vector are semantically probably the most consultant.
Instance of Top2Vec
On this tutorial, we’re going to analyze the unfavourable evaluations of McDonald’s from a dataset out there on data.world. Figuring out the matters from these evaluations might be helpful for the multinational to enhance the merchandise and the organisation of this quick meals chain within the USA areas supplied by the info.
import pandas as pd
from top2vec import Top2Vec
file_path = "McDonalds-Yelp-Sentiment-DFE.csv"
df = pd.read_csv(
file_path,
usecols=["_unit_id", "city", "review"],
encoding="unicode_escape",
)
df.head()
docs_bad = df["review"].values.tolist()

In a single line of code, we’re going to carry out all of the steps of the top2vec defined beforehand.
topic_model = Top2Vec(
docs_bad,
embedding_model="universal-sentence-encoder",
pace="deep-learn",
tokenizer=tok,
ngram_vocab=True,
ngram_vocab_args={"connector_words": "phrases.ENGLISH_CONNECTOR_WORDS"},
)
The principle arguments of Top2Vec are:
- docs_bad: is an inventory of strings.
- universal-sentence-encoder: is the chosen pre-trained embedding mannequin.
- deep-learn: is a parameter that determines the standard of the produced doc vector.
topic_model.get_num_topics() #3
topic_words, word_scores, topic_nums = topic_model.get_topics(3)
for subject in topic_nums:
topic_model.generate_topic_wordcloud(subject)
Probably the most

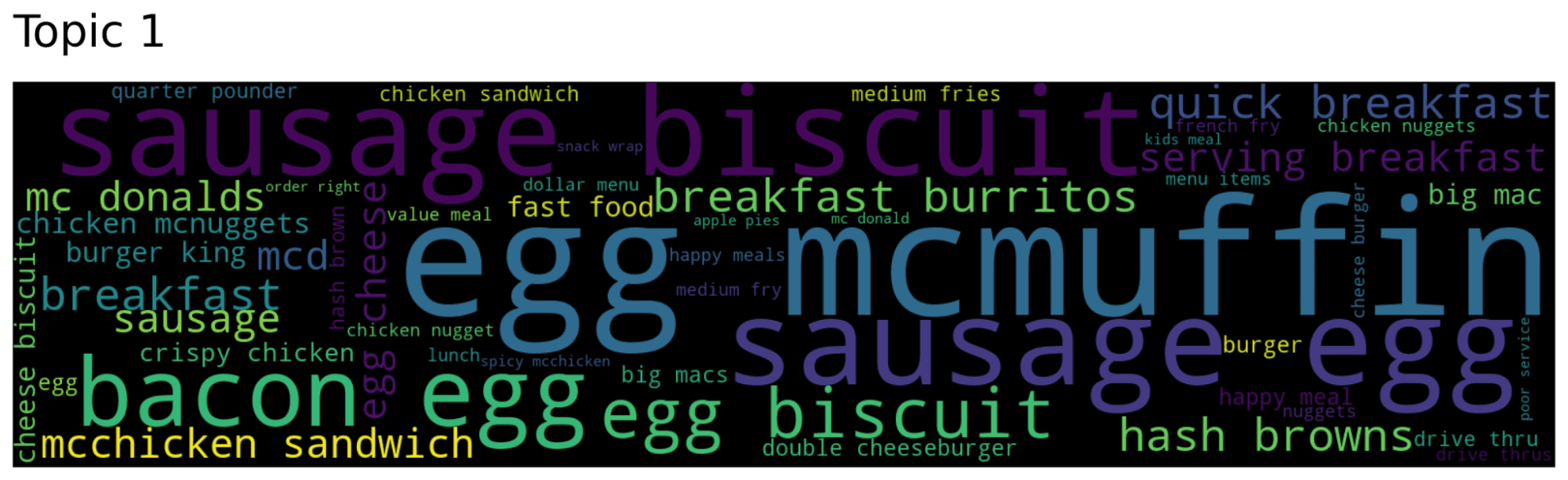

From the phrase clouds, we are able to deduce that the subject 0 is about basic complaints in regards to the service in McDonald, like “gradual service”, “horrible service” and “order incorrect”, whereas the subject 1 and a pair of refer respectively to breakfast meals (McMuffin, biscuit, egg) and occasional (iced espresso and cup espresso).
Now, we attempt to search paperwork utilizing two key phrases, incorrect and gradual:
(
paperwork,
document_scores,
document_ids,
) = topic_model.search_documents_by_keywords(
key phrases=["wrong", "slow"], num_docs=5
)
for doc, rating, doc_id in zip(paperwork, document_scores, document_ids):
print(f"Doc: {doc_id}, Rating: {rating}")
print("-----------")
print(doc)
print("-----------")
print()
Output:
Doc: 707, Rating: 0.5517634093633295
-----------
horrible.... that's all. don't go there.
-----------
Doc: 930, Rating: 0.4242547340973836
-----------
no drive by means of :-/
-----------
Doc: 185, Rating: 0.39162203345993046
-----------
the drive by means of line is horrible. they're painfully gradual.
-----------
Doc: 181, Rating: 0.3775083338082392
-----------
terrible service and very gradual. go elsewhere.
-----------
Doc: 846, Rating: 0.35400602635951994
-----------
they've dangerous service and really impolite
-----------
“BERTopic is a subject modeling method that leverages transformers and c-TF-IDF to create dense clusters permitting for simply interpretable matters while protecting vital phrases within the subject descriptions.”
Because the title suggests, BERTopic utilises highly effective transformer fashions to establish the matters current within the textual content. One other attribute of this subject modeling algorithm is the usage of a variant of TF-IDF, referred to as class-based variation of TF-IDF.
Like Top2Vec, it doesn’t have to know the variety of matters, however it mechanically extracts the matters.
Furthermore, equally to Top2Vec, it’s an algorithm that entails totally different phases. The primary three steps are the identical: creation of embedding paperwork, dimensionality discount with UMAP and clustering with HDBScan.
The successive phases start to diverge from Top2Vec. After discovering the dense areas with HDBSCAN, every subject is tokenized right into a bag-of-words illustration, which takes into consideration if the phrase seems within the doc or not. After the paperwork belonging to a cluster are thought of a singular doc and TF-IDF is utilized. So, for every subject, we establish probably the most related phrases, that ought to have the best c-TF-IDF.
Instance of BERTopic
We repeat the evaluation on the identical dataset.
We’re going to extract the matters from the evaluations utilizing BERTopic:
model_path_bad = 'mannequin/bert_bad'
topic_model_bad = train_bert(docs_bad,model_path_bad)
freq_df = topic_model_bad.get_topic_info()
print("Variety of matters: {}".format( len(freq_df)))
freq_df['Percentage'] = spherical(freq_df['Count']/freq_df['Count'].sum() * 100,2)
freq_df = freq_df.iloc[:,[0,1,3,2]]
freq_df.head()
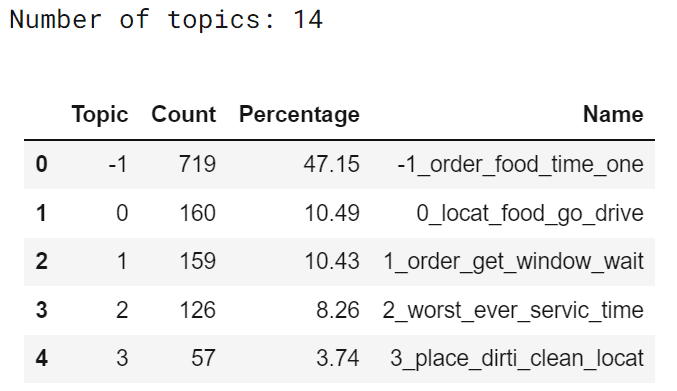
The desk returned by the mannequin offers details about the 14 matters extracted. Matter corresponds to the subject identifier, apart from all of the outliers which are ignored which are labeled as -1.
Now, we’re going to cross to probably the most fascinating half relating to the visualization of our matters into interactive graphs, such because the visualization of probably the most related phrases for every subject, the intertopic distance map, the two-dimensional illustration of the embedding house and the subject hierarchy.
Let’s start to point out the bar charts for the highest ten matters. For every subject, we are able to observe crucial phrases, sorted in lowering order based mostly on the c-TF-IDF rating. The extra a phrase is related, the extra the rating is greater.
The primary subject comprises generic phrases, like location and meals, subject 1 order and wait, subject 2 worst and repair, subject 3 place and soiled, advert so on.
After visualizing the bar charts, it’s time to check out the intertopic distance map. We scale back the dimensionality of c-TF-IDF rating right into a two-dimensional house to visualise the matters in a plot. On the backside, there’s a slider that permits choosing the subject that might be colored in purple. We will discover that the matters are grouped in two totally different clusters, one with generic thematics like meals, rooster and placement, and one with totally different unfavourable features, comparable to worst service, soiled, place and chilly.
The subsequent graph permits to see the connection between the evaluations and the matters. Particularly, it may be helpful to know why a evaluate is assigned to a particular subject and is aligned with probably the most related phrases discovered. For instance, we are able to concentrate on the purple cluster, akin to subject 2 with some phrases in regards to the worst service. The paperwork inside this dense space appear fairly unfavourable, like “Horrible customer support and even worse meals”.
At first sight, these approaches have many features in frequent, like discovering mechanically the variety of matters, no necessity of pre-processing in most of circumstances, the applying of UMAP to scale back the dimensionality of doc embeddings and, then, HDBSCAN is used for modelling these lowered doc embeddings, however they’re basically totally different when wanting on the method they assign the matters to the paperwork.
Top2Vec creates subject representations by discovering phrases positioned near a cluster’s centroid.
In another way from Top2Vec, BERTopic doesn’t take into consideration the cluster’s centroid, however it thought of all of the paperwork in a cluster as a singular doc and extracts subject representations utilizing a class-based variation of TF-IDF.
| Top2Vec | BERTopic |
| The technique to extract matters based mostly on cluster’s centroids. | The technique to extract matters based mostly on c-TF-IDF. |
| It doesn’t help Dynamic Matter Modeling. | It helps Dynamic Matter Modeling. |
| It builds phrase clouds for every subject and offers looking out instruments for matters, paperwork and phrases. | It permits for constructing Interactive visualization plots, permitting to interpretation of the extracted matters. |
The Matter Modeling is a rising subject of Pure Language Processing and there are quite a few potential functions, like evaluations, audio and social media posts. Because it has been proven, this text offers an overviews of Topi2Vec and BERTopic, which are two promising approaches, that may provide help to to establish matters with few strains of code and interpret the outcomes by means of knowledge visualizations. In case you have questions on these methods or you might have different solutions about different approaches to detect matters, write it within the feedback.
Eugenia Anello is presently a analysis fellow on the Division of Data Engineering of the College of Padova, Italy. Her analysis venture is targeted on Continuous Studying mixed with Anomaly Detection.
[ad_2]
Source link
