


[ad_1]
Geometric Deep Studying is an umbrella time period for approaches contemplating a broad class of ML issues from the views of symmetry and invariance. It supplies a typical blueprint permitting to derive from first rules neural community architectures as numerous as CNNs, GNNs, and Transformers. Right here, we research how these concepts have emerged by historical past from historical Greek geometry to Graph Neural Networks.

The final decade has witnessed an experimental revolution in information science and machine studying, epitomised by deep studying strategies. Certainly, many high-dimensional studying duties beforehand considered past attain — pc imaginative and prescient, enjoying Go, or protein folding — are in reality possible with applicable computational scale. Remarkably, the essence of deep studying is constructed from two easy algorithmic rules: first, the notion of illustration or function studying, whereby tailored, typically hierarchical, options seize the suitable notion of regularity for every process, and second, studying by gradient descent-type optimisation, sometimes carried out as backpropagation.
Whereas studying generic capabilities in excessive dimensions is a cursed estimation downside, most duties of curiosity should not generic and include important predefined regularities arising from the underlying low-dimensionality and construction of the bodily world. Geometric Deep Learning is worried with exposing these regularities by unified geometric rules that may be utilized all through a broad spectrum of purposes.
Exploiting the identified symmetries of a big system is a strong and classical treatment in opposition to the curse of dimensionality, and types the premise of most bodily theories. Deep studying programs aren’t any exception, and because the early days, researchers have tailored neural networks to use the low-dimensional geometry arising from bodily measurements, e.g. grids in pictures, sequences in time-series, or place and momentum in molecules, and their related symmetries, comparable to translation or rotation.
Since these concepts have deep roots in science, we are going to try to see how they’ve developed all through historical past, culminating in a typical blueprint that may be utilized to most of right now’s standard neural community architectures.
“Symmetry, as vast or as slender as you could outline its which means, is one thought by which man by the ages has tried to understand and create order, magnificence, and perfection.” — Hermann Weyl (1952)
This considerably poetic definition of symmetry is given within the eponymous e-book of the good mathematician Hermann Weyl [1], his Schwanengesang on the eve of retirement from the Institute for Superior Examine in Princeton. Weyl traces the particular place symmetry has occupied in science and artwork to historical instances, from Sumerian symmetric designs to the Pythagoreans, who believed the circle to be excellent as a result of its rotational symmetry. Plato thought of the 5 common polyhedra bearing his identify right now so basic that they have to be the fundamental constructing blocks shaping the fabric world.
But, although Plato is credited with coining the time period συμμετρία (‘symmetria’) which accurately interprets as ‘identical measure’, he used it solely vaguely to convey the great thing about proportion in artwork and concord in music. It was the German astronomer and mathematician Johannes Kepler who tried the primary rigorous evaluation of the symmetric form of water crystals. In his treatise ‘On the Six-Cornered Snowflake’ [2], he attributed the six-fold dihedral construction of snowflakes to hexagonal packing of particles — an concept that although preceded the clear understanding of how matter is fashioned, nonetheless holds right now as the premise of crystallography [3].

In trendy arithmetic, symmetry is sort of univocally expressed within the language of group theory. The origins of this principle are normally attributed to Évariste Galois, who coined the time period and used it to check the solvability of polynomial equations within the 1830s [4]. Two different names related to group principle are these of Sophus Lie and Felix Klein, who met and labored fruitfully collectively for a time period [5]. The previous would develop the idea of steady symmetries that right now bears his identify (Lie groups); the latter proclaimed group principle to be the organising precept of geometry in his Erlangen Programme. Provided that Klein’s Programme is the inspiration for Geometric Deep Studying, it’s worthwhile to spend extra time on its historic context and revolutionary influence.

The foundations of recent geometry have been formalised in historical Greece almost 2300 years in the past by Euclid in a treatise named the Parts. Euclidean geometry (which continues to be taught at college as ‘the geometry’) was a set of outcomes constructed upon 5 intuitive axioms or postulates. The Fifth Postulate — stating that it’s attainable to cross just one line parallel to a given line by some extent outdoors it — appeared much less apparent and an illustrious row of mathematicians broke their enamel making an attempt to show it since antiquity, to no avail.
An early strategy to the issue of the parallels seems within the eleventh-century Persian treatise ‘A commentary on the difficulties regarding the postulates of Euclid’s Parts’ by Omar Khayyam [6]. The eighteenth-century Italian Jesuit priest Giovanni Saccheri was seemingly conscious of this earlier work judging by the title of his personal work Euclides ab omni nævo vindicatus (‘Euclid cleared of each stain’).
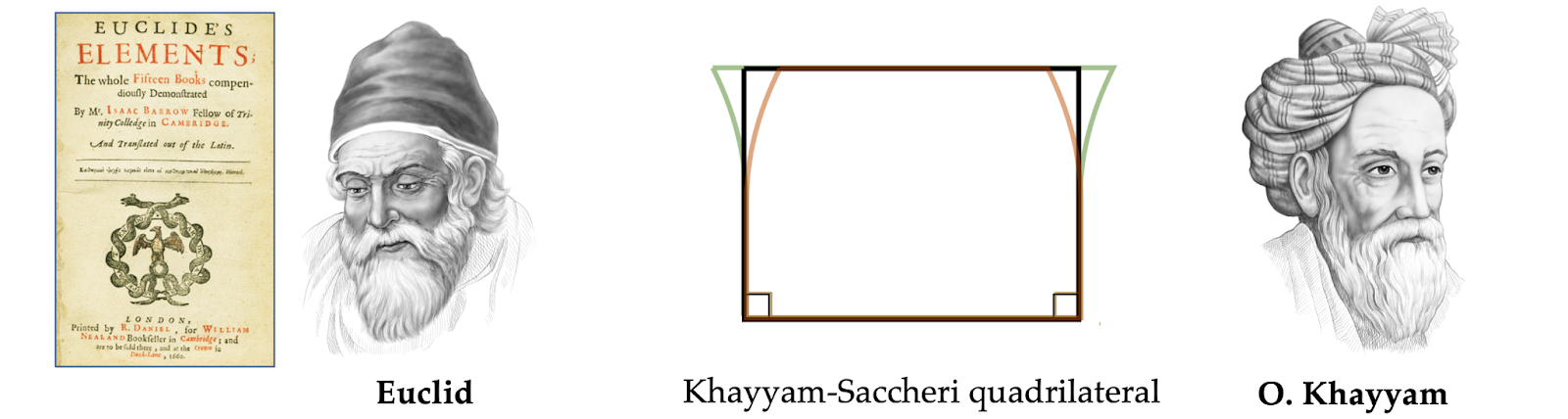
Like Khayyam, he thought of the summit angles of a quadrilateral with sides perpendicular to the bottom. The conclusion that acute angles result in infinitely many non-intersecting strains that may be handed by some extent not on a straight line appeared so counter-intuitive that he rejected it as ‘repugnatis naturæ linæ rectæ’ (‘repugnant to the character of straight strains’) [7].

The nineteenth century has introduced the realisation that the Fifth Postulate will not be important and one can assemble different geometries primarily based on completely different notions of parallelism. One such early instance is projective geometry, arising, because the identify suggests, in perspective drawing and structure. On this geometry, factors and contours are interchangeable, and there aren’t any parallel strains within the traditional sense: any strains meet in a ‘level at infinity.’ Whereas ends in projective geometry had been identified since antiquity, it was first systematically studied by Jean-Victor Poncelet in 1812 [8].

The credit score for the primary development of a real non-Euclidean geometry is disputed. The princeps mathematicorum Carl Friedrich Gauss labored on it round 1813 however by no means revealed any outcomes [9]. The primary publication with regards to non-Euclidean geometry was ‘On the Origins of Geometry’ by the Russian mathematician Nikolai Lobachevsky [10]. On this work, he thought of the Fifth Postulate an arbitrary limitation and proposed an alternate one, that multiple line can cross by some extent that’s parallel to a given one. Such development requires an area with detrimental curvature — what we now name a hyperbolic area — a notion that was nonetheless not totally mastered at the moment [11].

Lobachevsky’s thought appeared heretical and he was overtly derided by colleagues [12]. The same development was independently found by the Hungarian János Bolyai, who revealed it in 1832 beneath the identify ‘absolute geometry.’ In an earlier letter to his father dated 1823, he wrote enthusiastically about this new growth:
“I’ve found such fantastic issues that I used to be amazed… out of nothing I’ve created an odd new world.” — János Bolyai (1823)
Within the meantime, new geometries continued to come back out like from a cornucopia. August Möbius [13], of the eponymous surface fame, studied affine geometry. Gauss’ scholar Bernhardt Riemann launched a really broad class of geometries — known as right now Riemannian is his honour — in his habilitation lecture, subsequently revealed beneath the title Über die Hypothesen, welche der Geometrie zu Grunde liegen (‘On the Hypotheses on which Geometry is Primarily based’) [14]. A particular case of Riemannian geometry is the ‘elliptic’ geometry of the sphere, one other development violating Euclid’s Fifth Postulate, as there is no such thing as a level on the sphere by which a line could be drawn that by no means intersects a given line.
In direction of the second half of the nineteenth century, Euclid’s monopoly over geometry was fully shattered. New sorts of geometry (affine, projective, hyperbolic, spherical) emerged and have become unbiased fields of research. Nonetheless, the relationships of those geometries and their hierarchy weren’t understood.
It was on this thrilling however messy scenario that Felix Klein got here forth, with a genius perception to make use of group principle as an algebraic abstraction of symmetry to organise the ‘geometric zoo.’ Solely 23 years outdated on the time of his appointment as a professor in Erlangen, Klein, because it was customary in German universities, was requested to ship an inaugural analysis programme — titled Vergleichende Betrachtungen über neuere geometrische Forschungen (‘A comparative assessment of latest researches in geometry’), it has entered the annals of arithmetic because the “Erlangen Programme” [15].
The breakthrough perception of Klein was to strategy the definition of geometry because the research of invariants, or in different phrases, constructions which are preserved beneath a sure kind of transformations (symmetries). Klein used the formalism of group principle to outline such transformations and use the hierarchy of teams and their subgroups as a way to classify completely different geometries arising from them.
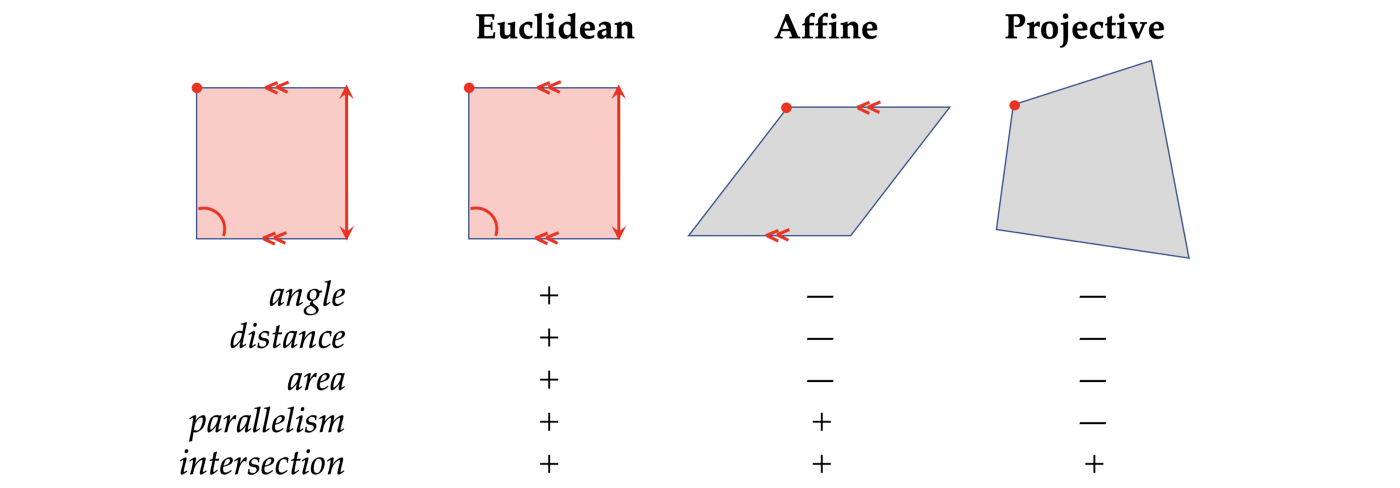
It appeared that Euclidean geometry is a particular case of affine geometry, which is in flip a particular case of projective geometry (or, when it comes to group principle, the Euclidean group is a subgroup of the projective group). Klein’s Erlangen Programme was in a way the ‘second algebraisation’ of geometry (the primary one being the analytic geometry of René Descartes and the tactic of coordinates bearing his Latinised identify Cartesius) that allowed to provide outcomes inconceivable by earlier strategies.
Extra normal Riemannian geometry was explicitly excluded from Klein’s unified geometric image, and it took one other fifty years earlier than it was built-in, largely due to the work of Élie Cartan within the Twenties. Moreover, Category Theory, now pervasive in pure arithmetic, could be “considered a continuation of the Klein Erlangen Programme, within the sense {that a} geometrical area with its group of transformations is generalized to a class with its algebra of mappings”, within the phrases of its creators Samuel Eilenberg and Saunders Mac Lane [16].

Contemplating projective geometry essentially the most normal of all, Klein complained in his Vergleichende Betrachtungen [17]:
“How persistently the mathematical physicist disregards the benefits afforded him in lots of instances by solely a average cultivation of the projective view.” — Felix Klein (1872)
His advocating for the exploitation of symmetry in physics has foretold the next century revolutionary developments within the subject.
In Göttingen [18], Klein’s colleague Emmy Noether [19] proved that each differentiable symmetry of the motion of a bodily system has a corresponding conservation legislation [20]. It was a surprising outcome: beforehand, meticulous experimental remark was required to find basic legal guidelines such because the conservation of power. Noether’s Theorem — “a guiding star to twentieth and Twenty first century physics,” within the phrases of the Nobel laureate Frank Wilczek — allowed for instance to indicate that the conservation of power emerges from the translational symmetry of time.

One other symmetry was related to cost conservation, the worldwide gauge invariance of the electromagnetic subject, first appeared in Maxwell’s formulation of electrodynamics [21]; nonetheless, its significance initially remained unnoticed. The identical Hermann Weyl, who wrote so dithyrambically about symmetry, first launched the idea of gauge invariance in physics within the early twentieth century [22], emphasizing its function as a precept from which electromagnetism could be derived. It took a number of a long time till this basic precept — in its generalised type developed by Yang and Mills [23] — proved profitable in offering a unified framework to explain the quantum-mechanical behaviour of electromagnetism and the weak and robust forces. Within the Seventies, it culminated within the Normal Mannequin that captures all the elemental forces of nature however gravity [24]. As succinctly put by one other Nobel-winning physicist, Philip Anderson [25],
“it’s only barely overstating the case to say that physics is the research of symmetry” — Philip Anderson (1972)
An impatient reader would possibly marvel at this level, what does all this tour into the historical past of geometry and physics, nonetheless thrilling it could be, must do with deep studying? As we are going to see, the geometric notions of symmetry and invariance have been recognised as essential even in early makes an attempt to do ‘sample recognition,’ and it’s truthful to say that geometry has accompanied the nascent subject of synthetic intelligence from its very starting.
Whereas it’s onerous to agree on a particular cut-off date when ‘synthetic intelligence’ was born as a scientific subject (in the long run, people have been obsessive about comprehending intelligence and studying from the daybreak of civilisation), we are going to strive a much less dangerous process of trying on the precursors of deep studying — the primary subject of our dialogue. This historical past could be packed into lower than a century [26].
By the Nineteen Thirties, it has turn into clear that the thoughts resides within the mind, and analysis efforts turned to explaining mind capabilities comparable to reminiscence, notion, and reasoning, when it comes to mind community constructions. McCulloch and Pitts [27] are credited with the primary mathematical abstraction of the neuron, exhibiting its functionality to compute logical capabilities. Only a 12 months after the legendary Dartmouth College workshop that coined the very time period ‘synthetic intelligence’ [28], an American psychologist Frank Rosenblatt from Cornell Aeronautical laboratory proposed a category of neural networks he known as ‘perceptrons’ [29].
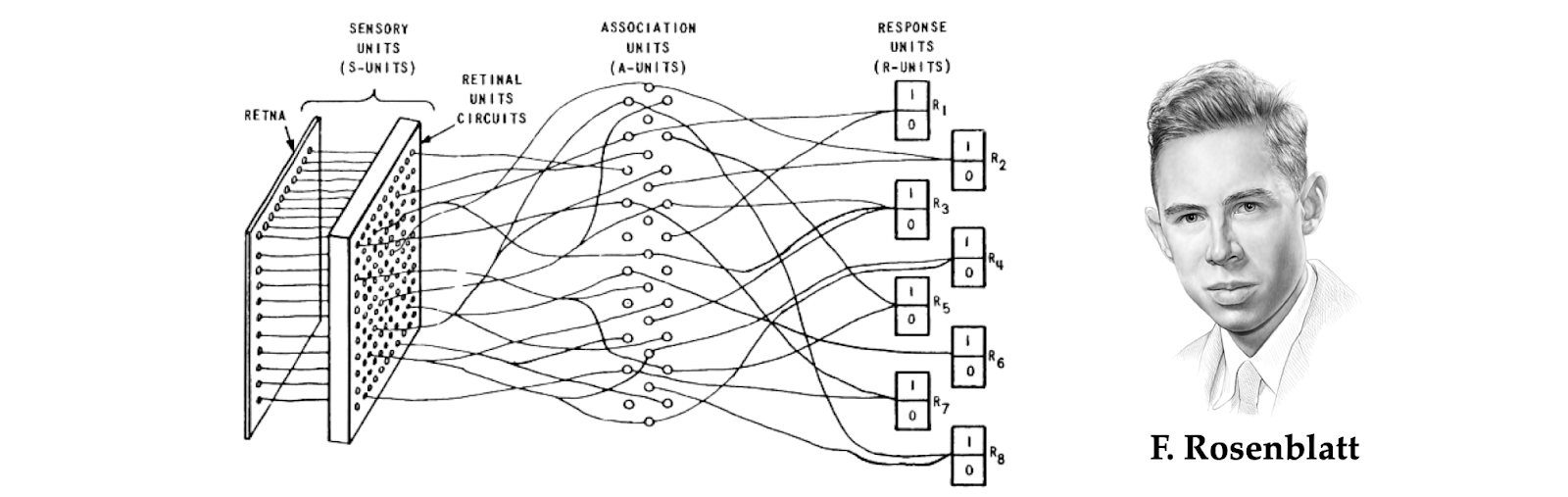
Perceptrons, first carried out on a digital machine after which in devoted {hardware}, managed to resolve easy sample recognition issues comparable to classification of geometric shapes. Nonetheless, the short rise of ‘connectionism’ (how AI researchers engaged on synthetic neural networks labeled themselves) acquired a bucket of chilly water within the type of the now-infamous e-book Perceptrons by Marvin Minsky and Seymour Papert [30].
Within the deep studying group, it’s common to retrospectively blame Minsky and Papert for the onset of the primary ‘AI Winter,’ which made neural networks fall out of vogue for over a decade. A typical narrative mentions the ‘XOR Affair,’ a proof that perceptrons have been unable to be taught even quite simple logical capabilities as proof of their poor expressive energy. Some sources even add a pinch of drama recalling that Rosenblatt and Minsky went to the identical college and even alleging that Rosenblatt’s untimely dying in a boating accident in 1971 was a suicide within the aftermath of the criticism of his work by colleagues.

The fact might be extra mundane and extra nuanced on the identical time. First, a much more believable cause for the ‘AI Winter’ within the USA is the 1969 Mansfield Amendment, which required the army to fund “mission-oriented direct analysis, quite than primary undirected analysis.” Since many efforts in synthetic intelligence on the time, together with Rosenblatt’s analysis, have been funded by army businesses and didn’t present speedy utility, the reduce in funding has had dramatic results. Second, neural networks and synthetic intelligence typically have been over-hyped: it is sufficient to recall a 1958 New Yorker article calling perceptrons a
“first severe rival to the human mind ever devised” — The New Yorker (1958)
and “exceptional machines” that have been “able to what quantities to thought” [31], or the overconfident MIT Summer Vision Project anticipating a “development of a big a part of a visible system” and attaining the power to carry out “sample recognition” [32] throughout one summer time time period of 1966. A realisation by the analysis group that preliminary hopes to ‘remedy intelligence’ had been overly optimistic was only a matter of time.

If one, nonetheless, seems into the substance of the dispute, it’s obvious that what Rosenblatt known as a ‘perceptron’ is quite completely different from what Minsky and Papert understood beneath this time period. Minsky and Papert targeted their evaluation and criticism on a slender class of single-layer neural networks they known as ‘easy perceptrons’ (and what’s sometimes related to this time period in trendy instances) that compute a weighted linear mixture of the inputs adopted by a nonlinear perform [33]. However, Rosenblatt thought of a broader class of architectures that antedated many concepts of what would now be thought of ‘trendy’ deep studying, together with multi-layered networks with random and native connectivity [34].
Rosenblatt may have in all probability rebutted a few of the criticism regarding the expressive energy of perceptrons had he identified in regards to the proof of the Thirteenth Hilbert Problem [35] by Vladimir Arnold and Andrey Kolmogorov [36-37] establishing {that a} steady multivariate perform could be written as a superposition of steady capabilities of a single variable. The Arnold–Kolmogorov theorem was a precursor of a subsequent class of outcomes often known as ‘common approximation theorems’ for multi-layer (or ‘deep’) neural networks that put these issues to relaxation.
Whereas most keep in mind the e-book of Minsky and Papert for the function it performed in slicing the wings of the early day connectionists and lament the misplaced alternatives, an vital ignored facet is that it for the primary time offered a geometrical evaluation of studying issues. This reality is mirrored within the very identify of the e-book, subtitled ‘An introduction to Computational Geometry.’ On the time it was a radically new thought, and one crucial assessment of the e-book [38] (which basically stood within the protection of Rosenblatt), questioned:
“Will the brand new topic of “Computational Geometry” develop into an lively subject of arithmetic; or will it peter out in a miscellany of lifeless ends?” — Block (1970)
The previous occurred: computational geometry is now a well-established subject [39].
Moreover, Minsky and Papert in all probability deserve the credit score for the primary introduction of group principle into the realm of machine studying: their Group Invariance theorem acknowledged that if a neural community is invariant to some group, then its output may very well be expressed as capabilities of the orbits of the group. Whereas they used this outcome to show the restrictions of what a perceptron may be taught, comparable approaches have been subsequently utilized by Shun’ichi Amari [40] for the development of invariant options in sample recognition issues. An evolution of those concepts within the works of Terrence Sejnowski [41] and John Shawe-Taylor [42–43], sadly hardly ever cited right now, offered the foundations of the Geometric Deep Learning Blueprint.
The aforementioned notion of common approximation deserves additional dialogue. The time period refers back to the means to approximate any steady multivariate perform to any desired accuracy; within the machine studying literature, outcomes of this kind are normally credited to Cybenko [44] and Hornik [45]. Not like ‘easy’ (single-layer) perceptrons criticised by Minsky and Papert, multilayer neural networks are common approximators and thus are an interesting selection of structure for studying issues. We will consider supervised machine studying as a perform approximation downside: given the outputs of some unknown perform (e.g., a picture classifier) on a coaching set (e.g., pictures of cats and canine), we attempt to discover a perform from some speculation class that matches properly the coaching information and permits to foretell the outputs on beforehand unseen inputs (‘generalisation’).
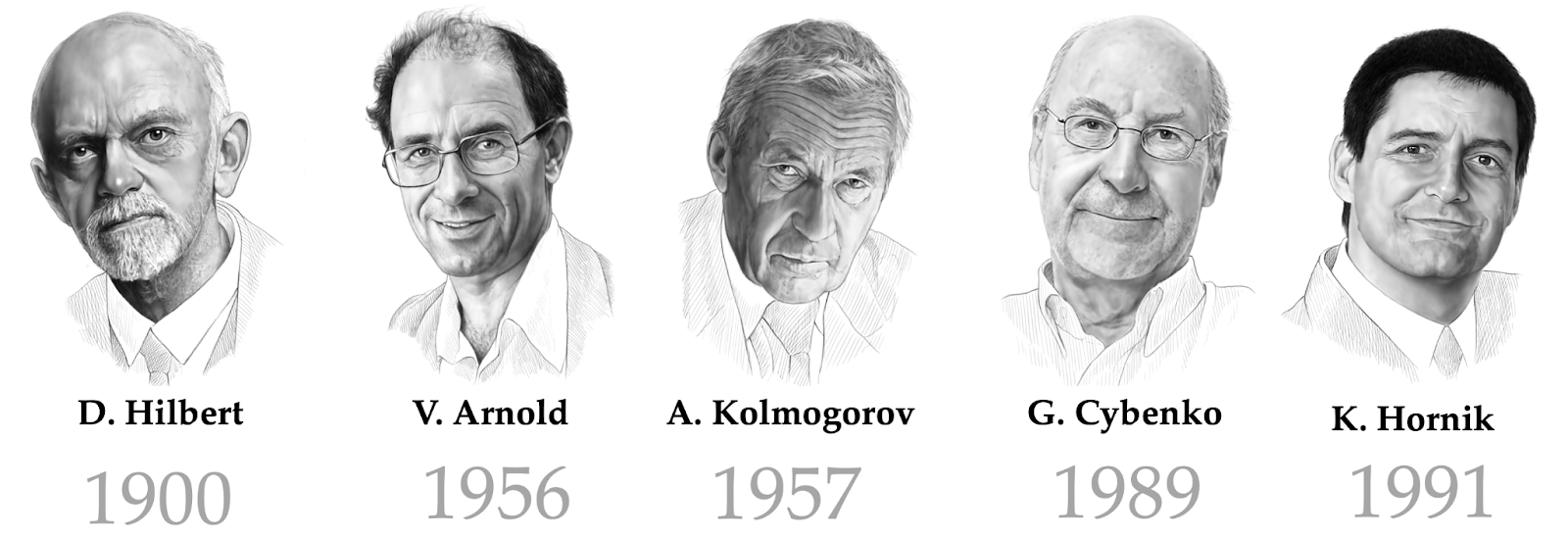
Common approximation ensures that we are able to specific capabilities from a really broad regularity class (steady capabilities) by the use of a multi-layer neural community. In different phrases, there exists a neural community with a sure variety of neurons and sure weights that approximates a given perform mapping from the enter to the output area (e.g., from the area of pictures to the area of labels). Nonetheless, common approximation theorems don’t inform us how you can discover such weights. The truth is, studying (i.e., discovering weights) in neural networks has been a giant problem within the early days.
Rosenblatt confirmed a studying algorithm just for a single-layer perceptron; to coach multi-layer neural networks, Aleksey Ivakhnenko and Valentin Lapa [46] used a layer-wise studying algorithm known as ‘group technique of knowledge dealing with.’ This allowed Ivakhnenko [47] to go as deep as eight layers — a exceptional feat for the early Seventies!

A breakthrough got here with the invention of backpropagation, an algorithm utilizing the chain rule to compute the gradient of the weights with respect to the loss perform, and allowed to make use of gradient descent-based optimisation methods to coach neural networks. As of right now, that is the usual strategy in deep studying. Whereas the origins of backpropagation date again to a minimum of 1960 [48] the primary convincing demonstration of this technique in neural networks was within the broadly cited Nature paper of Rumelhart, Hinton, and Williams [49]. The introduction of this straightforward and environment friendly studying technique has been a key contributing issue to the return of neural networks to the AI scene within the Nineteen Eighties and Nineteen Nineties.
Taking a look at neural networks by the lens of approximation principle has led some cynics to name deep studying a “glorified curve becoming.” We are going to let the reader choose how true this maxim is by making an attempt to reply an vital query: what number of samples (coaching examples) are wanted to precisely approximate a perform? Approximation theorists will instantly retort that the category of steady capabilities that multilayer perceptrons can symbolize is clearly approach too giant: one can cross infinitely many various steady capabilities by a finite assortment of factors [50]. It’s essential to impose further regularity assumptions comparable to Lipschitz continuity [51], wherein case one can present a certain on the required variety of samples.
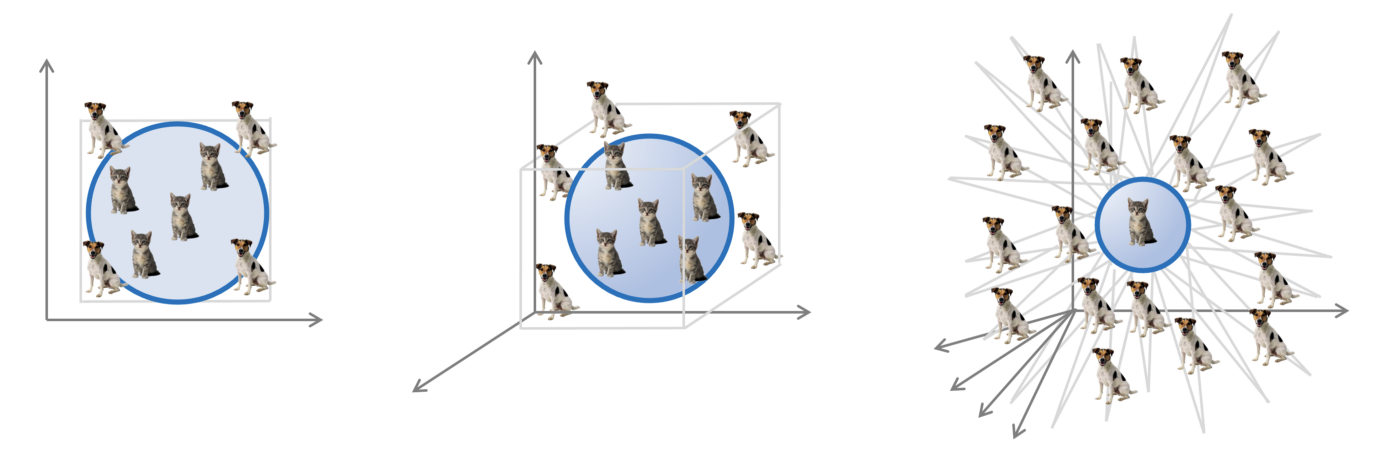
Sadly, these bounds scale exponentially with dimension — a phenomenon colloquially often known as the ‘curse of dimensionality’ [52] — which is unacceptable in machine studying issues: even small-scale sample recognition issues, comparable to picture classification, cope with enter areas of 1000’s of dimensions. If one needed to rely solely on classical outcomes from approximation principle, machine studying could be inconceivable. In our illustration, the variety of examples of cat and canine pictures that will be required in principle as a way to be taught to inform them aside could be approach bigger than the variety of atoms within the universe [53] — there are merely not sufficient cats and canine round to do it.

The wrestle of machine studying strategies to scale to excessive dimensions was introduced up by the British mathematician Sir James Lighthill in a paper that AI historians name the ‘Lighthill Report’ [54], wherein he used the time period ‘combinatorial explosion’ and claimed that present AI strategies may solely work on toy issues and would turn into intractable in real-world purposes.
“Most employees in AI analysis and in associated fields confess to a pronounced feeling of disappointment in what has been achieved prior to now twenty-five years. […] In no a part of the sector have the discoveries made thus far produced the key influence that was then promised.” — Sir James Lighthill (1972)
For the reason that Lighthill Report was commissioned by the British Science Analysis Council to guage educational analysis within the subject of synthetic intelligence, its pessimistic conclusions resulted in funding cuts throughout the pond. Along with comparable selections by the American funding businesses, this amounted to a wrecking ball for AI analysis within the Seventies.
The following technology of neural networks, which culminated within the triumphant reemergence of deep studying we have now witnessed a decade in the past, drew their inspiration from neuroscience.
In a collection of experiments that will turn into classical and produce them a Nobel Prize in drugs, the duo of Harvard neurophysiologists David Hubel and Torsten Wiesel [55–56] unveiled the construction and performance of part of the mind answerable for sample recognition — the visible cortex. By presenting altering gentle patterns to a cat and measuring the response of its mind cells (neurons), they confirmed that the neurons within the visible cortex have a multi-layer construction with native spatial connectivity: a cell would produce a response provided that cells in its proximity (‘receptive subject’ [57]) have been activated.

Moreover, the organisation gave the impression to be hierarchical, the place the responses of ‘easy cells’ reacting to native primitive oriented step-like stimuli have been aggregated by ‘complicated cells,’ which produced responses to extra complicated patterns. It was hypothesized that cells in deeper layers of the visible cortex would reply to more and more complicated patterns composed of easier ones, with a semi-joking suggestion of the existence of a ‘grandmother cell’ [58] that reacts solely when proven the face of 1’s grandmother.
The understanding of the construction of the visible cortex has had a profound influence on early works in pc imaginative and prescient and sample recognition, with a number of makes an attempt to mimic its important substances. Kunihiko Fukushima, at the moment a researcher on the Japan Broadcasting Company, developed a brand new neural community structure [59] “much like the hierarchy mannequin of the visible nervous system proposed by Hubel and Wiesel,” which was given the identify neocognitron [60].
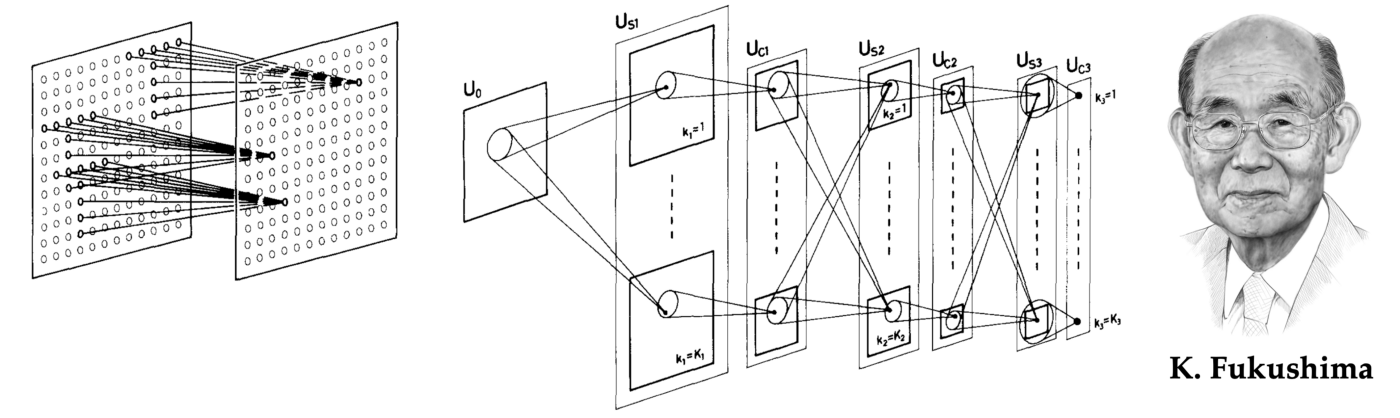
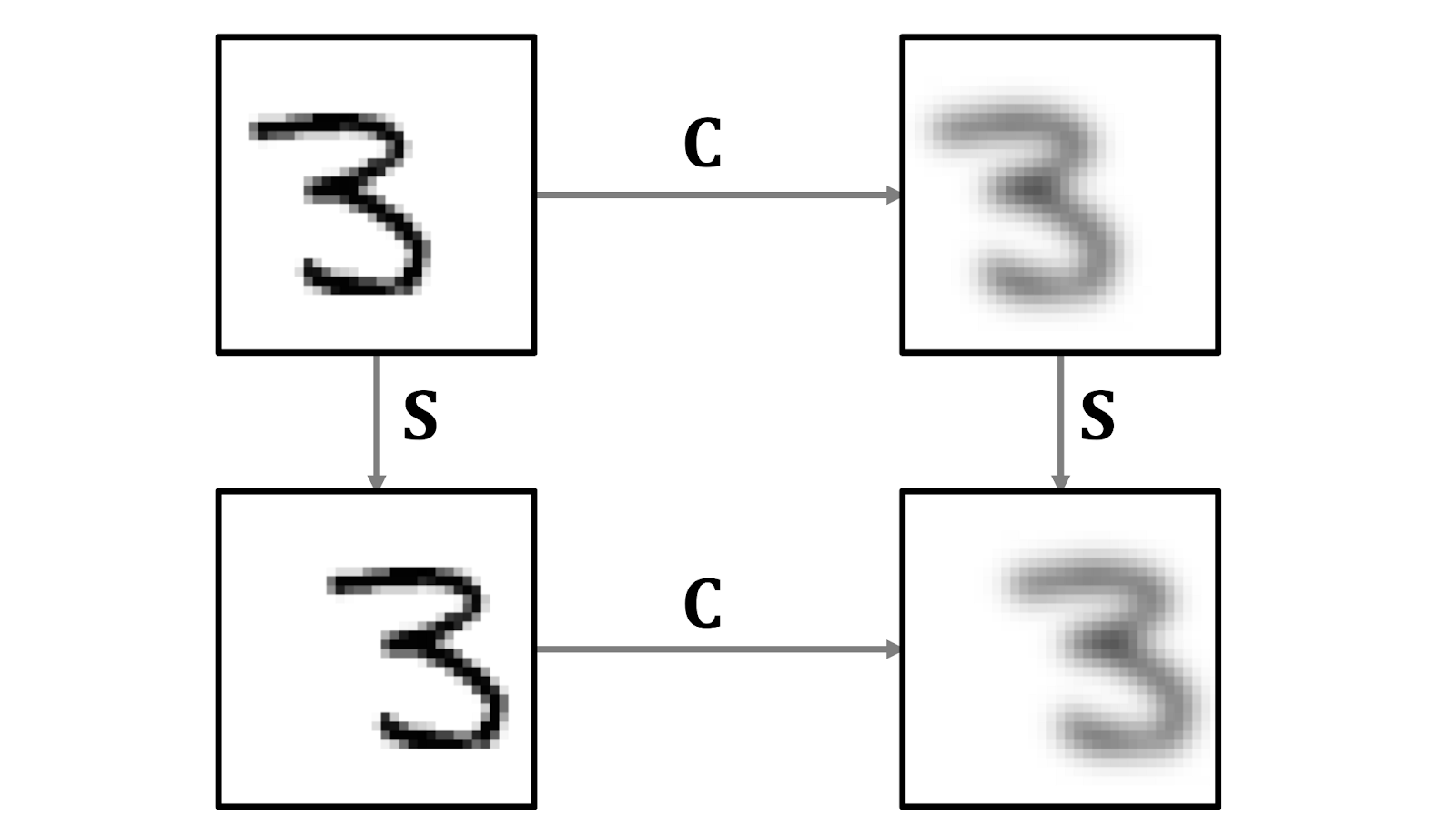
The neocognitron consisted of interleaved S– and C-layers of neurons (a naming conference reflecting its inspiration within the organic visible cortex); the neurons in every layer have been organized in 2D arrays following the construction of the enter picture (‘retinotopic’), with a number of ‘cell-planes’ (function maps in trendy terminology) per layer. The S-layers have been designed to be translationally symmetric: they aggregated inputs from a neighborhood receptive subject utilizing shared learnable weights, leading to cells in a single cell-plane having receptive fields of the identical perform, however at completely different positions. The rationale was to choose up patterns that would seem anyplace within the enter. The C-layers have been mounted and carried out native pooling (a weighted common), affording insensitivity to the precise location of the sample: a C-neuron could be activated if any of the neurons in its enter are activated.
For the reason that important software of the neocognitron was character recognition, translation invariance [61] was essential. This property was a basic distinction from earlier neural networks comparable to Rosenblatt’s perceptron: as a way to use a perceptron reliably, one needed to first normalise the place of the enter sample, whereas within the neocognitron, the insensitivity to the sample place was baked into the structure. Neocognitron achieved it by interleaving translationally-equivariant native function extraction layers with pooling, making a multiscale illustration [62]. Computational experiments confirmed that Fukushima’s structure was capable of efficiently recognise complicated patterns comparable to letters or digits, even within the presence of noise and geometric distortions.
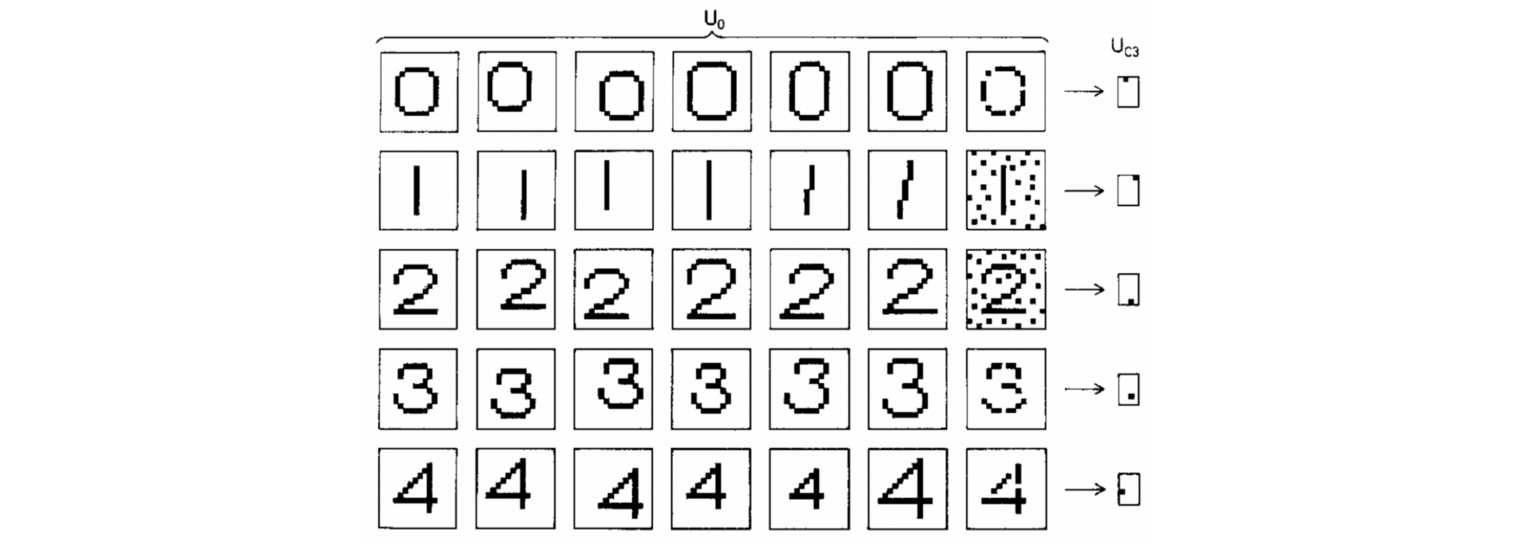
Wanting from the vantage level of 4 a long time of progress within the subject, one finds that the neocognitron already had strikingly many traits of recent deep studying architectures: depth (Fukishima simulated a seven-layer community in his paper), native receptive fields, shared weights, and pooling. It even used half-rectifier (ReLU) activation perform, which is commonly believed to be launched in latest deep studying architectures [63]. The primary distinction from trendy programs was in the way in which the community was educated: neocognitron was educated in an unsupervised method since backpropagation had nonetheless not been broadly used within the neural community group.
Fukushima’s design was additional developed by Yann LeCun, a recent graduate from the College of Paris [64] with a PhD thesis on the usage of backpropagation for coaching neural networks. In his first post-doctoral place on the AT&T Bell Laboratories, LeCun and colleagues constructed a system to recognise hand-written digits on envelopes as a way to permit the US Postal Service to mechanically route mail.

In a paper that’s now classical [65], LeCun et al. described the primary three-layer convolutional neural community (CNN) [66]. Equally to the neocognitron, LeCun’s CNN additionally used native connectivity with shared weights and pooling. Nonetheless, it forwent Fukushima’s extra complicated nonlinear filtering (inhibitory connections) in favour of straightforward linear filters that may very well be effectively carried out as convolutions utilizing multiply-and-accumulate operations on a digital sign processor (DSP) [67].
This design selection, departing from the neuroscience inspiration and terminology and transferring into the realm of sign processing, would play an important function within the ensuing success of deep studying. One other key novelty of CNN was the usage of backpropagation for coaching.
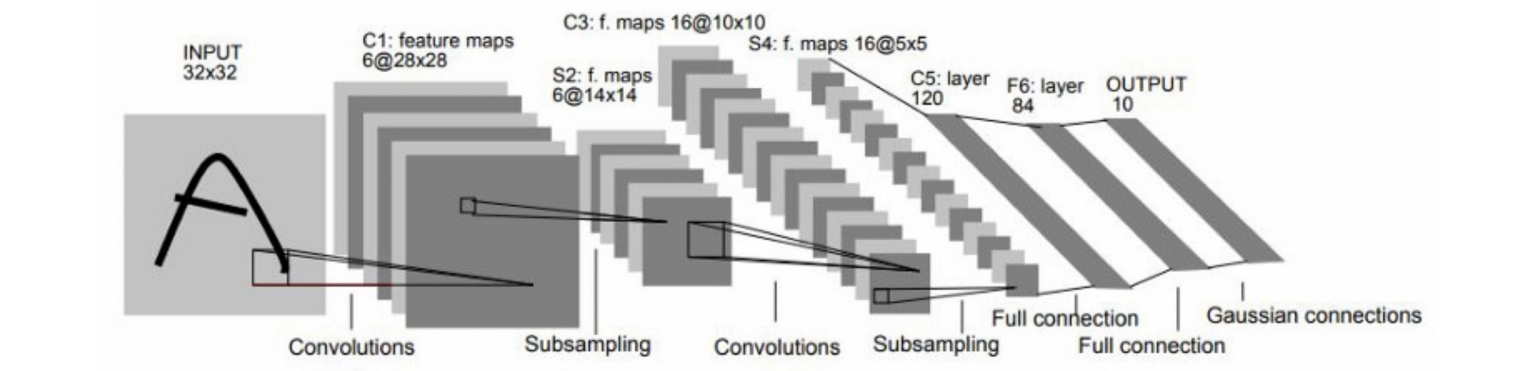
LeCun’s works convincingly confirmed the ability of gradient-based strategies for complicated sample recognition duties and was one of many first sensible deep learning-based programs for pc imaginative and prescient. An evolution of this structure, a CNN with 5 layers named LeNet-5 as a pun on the writer’s identify [68], was utilized by US banks to learn handwritten cheques.
The pc imaginative and prescient analysis group, nonetheless, in its overwhelming majority steered away from neural networks and took a distinct path. The standard structure of visible recognition programs of the primary decade of the brand new millennium was a fastidiously hand-crafted function extractor (sometimes detecting fascinating factors in a picture and offering their native description in a approach that’s strong to perspective transformations and distinction adjustments [69]) adopted by a easy classifier (most frequently a assist vector machine (SVM) and extra hardly ever, a small neural community) [70].
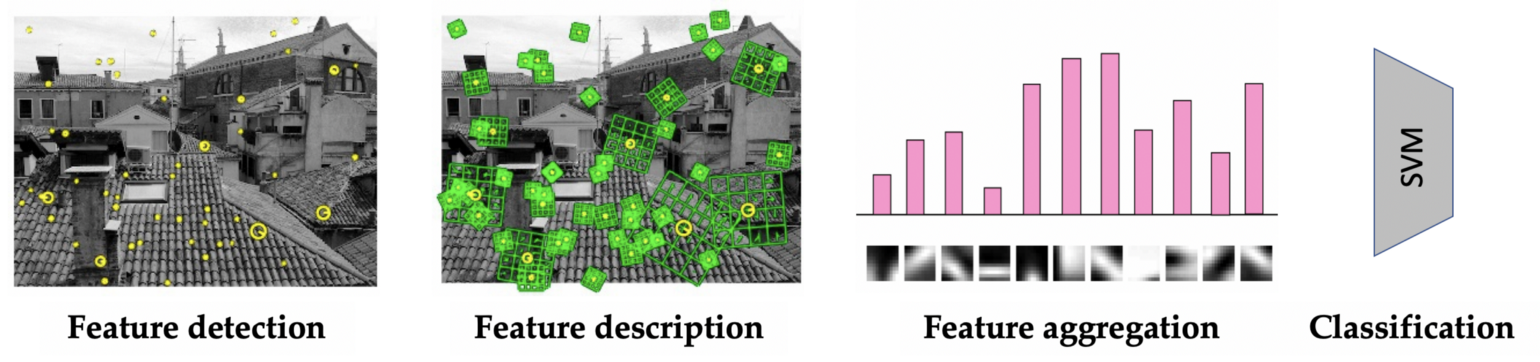
Whereas CNNs have been primarily utilized to modelling information with spatial symmetries comparable to pictures, one other growth was brewing: one which recognises that information is commonly non-static, however can evolve in a temporal method as properly. The only type of temporally-evolving information is a time collection consisting of a sequence of steps with a knowledge level offered at every step.
A mannequin dealing with time-series information therefore must be able to meaningfully adapting to sequences of arbitrary size—a feat that CNNs weren’t trivially able to. This led to growth of Recurrent Neural Networks (RNNs) within the late Nineteen Eighties and early Nineteen Nineties [71], the earliest examples of which merely applies a shared replace rule distributed by time [72–73]. At each step, the RNN state is up to date as a perform of the earlier state and the present enter.
One situation that plagued RNNs from the start was the vanishing gradient downside. Vanishing gradients come up in very deep neural networks—of which RNNs are sometimes an occasion of, provided that their efficient depth is the same as the sequence size—with sigmoidal activations is unrolled over many steps, suffers from gradients shortly approaching zero as backpropagation is carried out. This impact strongly limits the affect of earlier steps within the sequence to the predictions made within the latter steps.
An answer to this downside was first elaborated in Sepp Hochreiter’s Diploma thesis [74] (carried out in Munich beneath the supervision of Jürgen Schmidhuber) within the type of an structure that was dubbed Lengthy Quick-Time period Reminiscence (LSTM) [75]. LSTMs fight the vanishing gradient downside by having a reminiscence cell, with express gating mechanisms deciding how a lot of that cell’s state to overwrite at each step—permitting one to be taught the diploma of forgetting from information (or alternatively, remembering for very long time). In distinction, easy RNNs [72–73] carry out a full overwrite at each step.
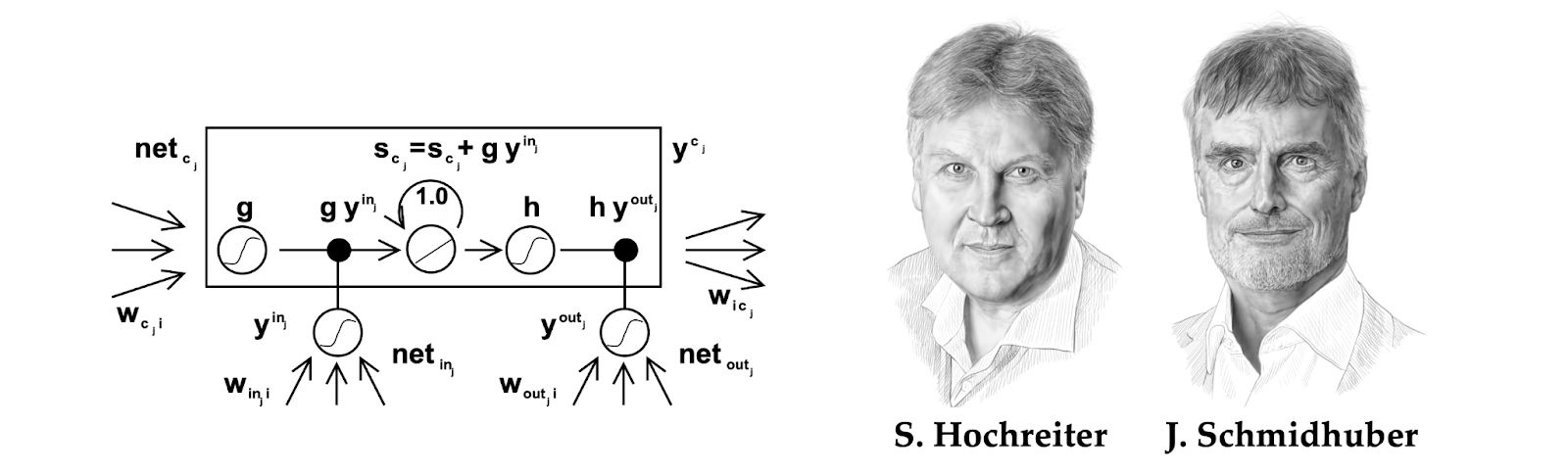
This means to recollect context for very long time turned essential in pure language processing and speech evaluation purposes, the place recurrent fashions have been proven profitable purposes ranging from the early 2000s [76–77]. Nonetheless, prefer it occurred with CNNs in pc imaginative and prescient, the breakthrough would want to attend for one more decade to come back.
In our context, it will not be initially apparent whether or not recurrent fashions embody any sort of symmetry or invariance precept much like the translational invariance we have now seen in CNNs. Almost three a long time after the event of RNNs, Corentin Tallec and Yann Ollivier [78] confirmed that there’s a kind of symmetry underlying recurrent neural networks: time warping.
Time collection have an important however delicate nuance: it’s hardly ever the case that the person steps of a time collection are evenly spaced. Certainly, in lots of pure phenomena, we might intentionally select to take many measurements at a while factors and only a few (or no) measurements throughout others. In a approach, the notion of “time” offered to the RNN engaged on such information undergoes a type of warping operation. Can we one way or the other assure that our RNN is “resistant” to time warping, within the sense that we are going to at all times be capable of discover a set of helpful parameters for it, whatever the warping operation utilized?
In an effort to deal with time warping with a dynamic fee, the community wants to have the ability to dynamically estimate how shortly time is being warped (the so-called “warping by-product”) at each step. This estimate is then used to selectively overwrite the RNN’s state. Intuitively, for bigger values of the warping by-product, a extra strict state overwrite must be carried out, as extra time has elapsed since.
The thought of dynamically overwriting information in a neural community is carried out by the gating mechanism. Tallec and Ollivier successfully present that, as a way to fulfill time warping invariance, an RNN wants to have a gating mechanism. This supplies a theoretical justification for gate RNN fashions, such because the aforementioned LSTMs of Hochreiter and Schmidhuber or the Gated Recurrent Unit (GRU) [79]. Full overwriting utilized in easy RNNs corresponds to an implicit assumption of a continuing time warping by-product equal to 1 – a scenario unlikely to occur in most real-world eventualities – which additionally explains the success of LSTMs.
As already talked about, the preliminary reception of what would later be known as “deep studying” had initially been quite lukewarm. The pc imaginative and prescient group, the place the primary decade of the brand new century was dominated by handcrafted function descriptors, gave the impression to be significantly hostile to the usage of neural networks. The steadiness of energy was quickly to be modified by the speedy progress in computing energy and the quantities of obtainable annotated visible information. It grew to become attainable to implement and practice more and more larger and extra complicated CNNs that allowed for the addressing of more and more difficult visible sample recognition duties [80], culminating in a Holy Grail of pc imaginative and prescient at the moment: the ImageNet Massive Scale Visible Recognition Problem. Established by the American-Chinese language researcher Fei-Fei Li in 2009, ImageNet was an annual problem consisting of the classification of hundreds of thousands of human-labeled pictures into 1000 completely different classes.
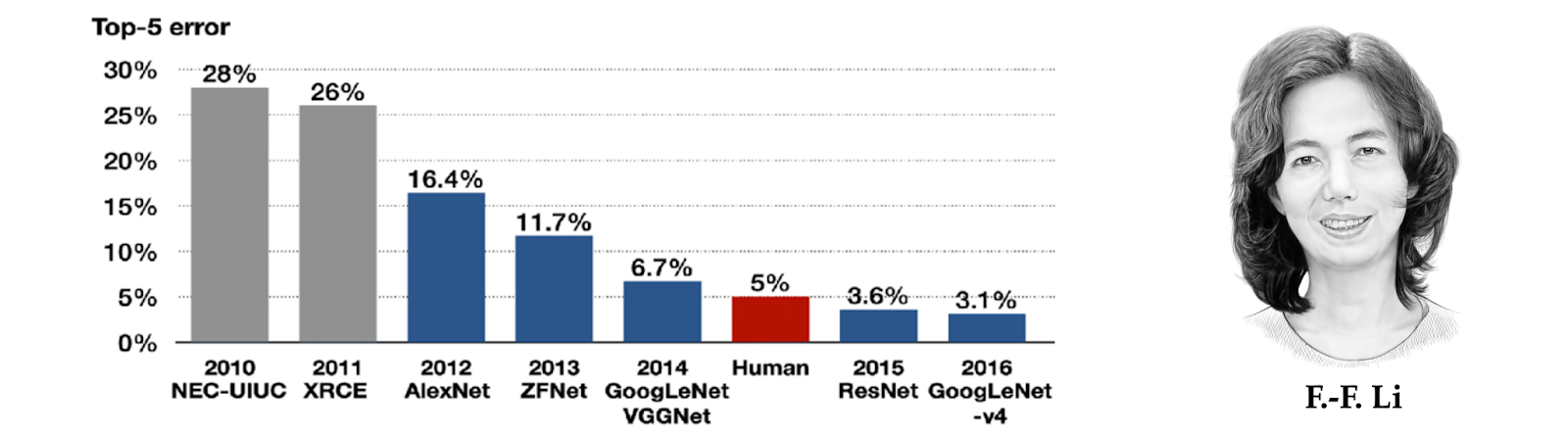
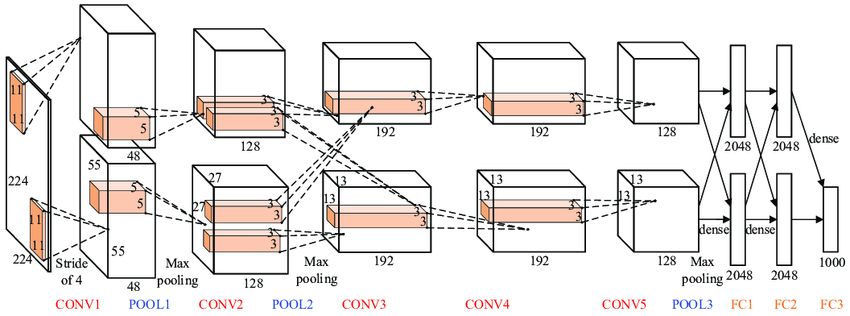
A CNN structure developed on the College of Toronto by Krizhevsky, Sutskever, and Hinton [81] managed to beat by a big margin [82] all of the competing approaches comparable to well engineered function detectors primarily based on a long time of analysis within the subject. AlexNet (because the structure was known as in honour of its developer, Alex Krizhevsky) was considerably larger when it comes to the variety of parameters and layers in comparison with its older sibling LeNet-5 [83], however conceptually the identical. The important thing distinction was the usage of a graphics processor (GPU) for coaching [84], now the mainstream {hardware} platform for deep studying [85].
The success of CNNs on ImageNet grew to become the turning level for deep studying and heralded its broad acceptance within the following decade. The same transformation occurred in pure language processing and speech recognition, which moved solely to neural network-based approaches throughout the 2010s; indicatively, Google [86] and Fb [87] switched their machine translations programs to LSTM-based architectures round 2016-17. Multi-billion greenback industries emerged on account of this breakthrough, with deep studying efficiently utilized in industrial programs starting from speech recognition in Apple iPhone to Tesla self-driving vehicles. Greater than forty years after the scathing assessment of Rosenblatt’s work, the connectionists have been lastly vindicated.
If the history of symmetry is tightly intertwined with physics, the historical past of graph neural networks, a “poster youngster” of Geometric Deep Studying, has roots in one other department of pure science: chemistry.
Chemistry has traditionally been — and nonetheless is — probably the most data-intensive educational disciplines. The emergence of recent chemistry within the eighteenth century resulted within the speedy progress within the variety of identified chemical compounds and an early want for his or her organisation. This function was initially performed by periodicals such because the Chemisches Zentralblatt [88] and “chemical dictionaries” just like the Gmelins Handbuch der anorganischen Chemie (an early compendium of inorganic compounds first published in 1817 [89]) and Beilsteins Handbuch der organischen Chemie (an analogous effort for natural chemistry) — initially revealed in German, which was one of many dominant language of science within the early twentieth century.
Within the English-speaking world, the Chemical Abstracts Service (CAS) was created in 1907 and has progressively turn into the central repository for the world’s revealed chemical info [90]. Nonetheless, the sheer quantity of knowledge (the Beilstein alone has grown to over 500 volumes and almost half one million pages over its lifetime) has shortly made it impractical to print and use such chemical databases.

For the reason that mid-nineteenth century, chemists have established a universally understood strategy to seek advice from chemical compounds by structural formulae, indicating a compound’s atoms, the bonds between them, and even their 3D geometry. However such constructions didn’t lend themselves to straightforward retrieval.
Within the first half of the twentieth century, with the speedy progress of newly found compounds and their industrial use, the issue of organising, looking, and evaluating molecules grew to become of essential significance: for instance, when a pharmaceutical firm sought to patent a brand new drug, the Patent Workplace needed to confirm whether or not an analogous compound had been beforehand deposited.
To handle this problem, a number of programs for indexing molecules have been launched within the Nineteen Forties, forming foundations for a brand new self-discipline that will later be known as chemoinformatics. One such system, named the ‘GKD chemical cipher’ after the authors Gordon, Kendall, and Davison [91], was developed on the English tire agency Dunlop for use with early punchcard-based computer systems [92]. In essence, the GKD cipher was an algorithm for parsing a molecular construction right into a string that may very well be extra simply regarded up by a human or a pc.
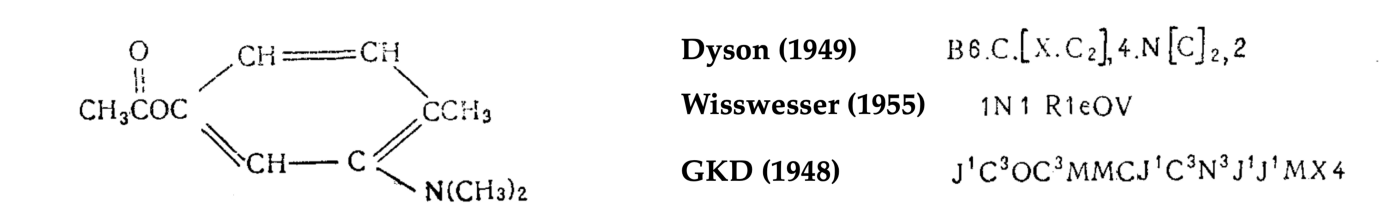
Nonetheless, the GKD cipher and different associated strategies [93] have been removed from passable. In chemical compounds, comparable constructions typically lead to comparable properties. Chemists are educated to develop instinct to identify such analogies, and search for them when evaluating compounds. For instance, the affiliation of the benzene ring with odouriferous properties was the explanation for the naming of the chemical class of “fragrant compounds” within the Nineteenth century.
However, when a molecule is represented as a string (comparable to within the GKD cipher), the constituents of a single chemical construction could also be mapped into completely different positions of the cipher. In consequence, two molecules containing an analogous substructure (and thus probably comparable properties) could be encoded in very alternative ways.
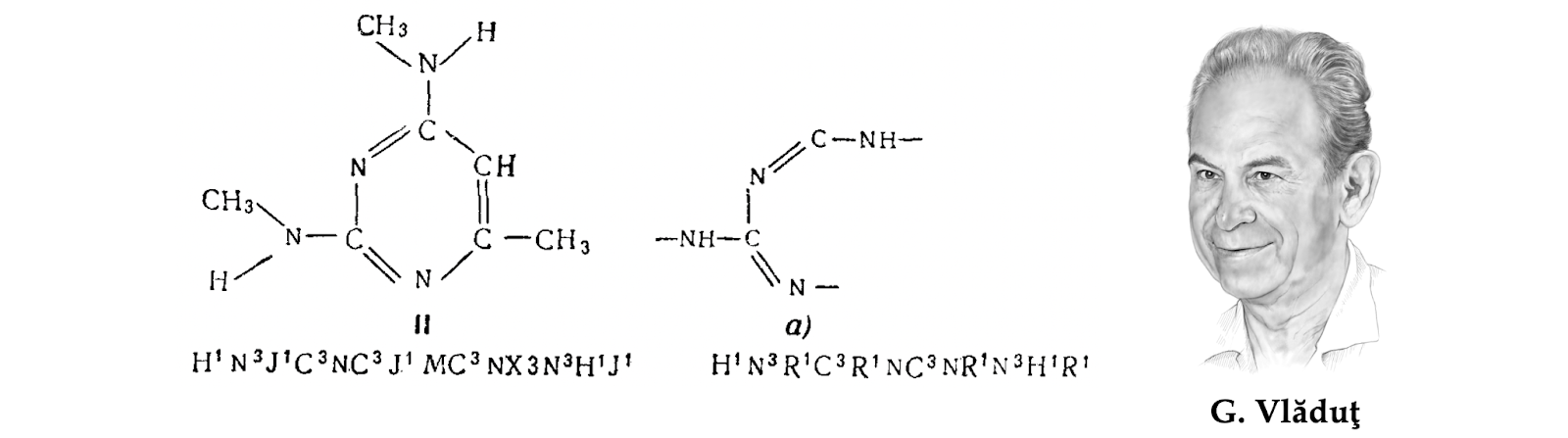
This realisation has inspired the event of “topological ciphers,” making an attempt to seize the construction of the molecule. First works of this type have been completed within the Dow Chemical compounds firm [94] and the US Patent Workplace [95] — each heavy customers of chemical databases. Probably the most well-known such descriptors, often known as the ‘Morgan fingerprint’ [96], was developed by Harry Morgan on the Chemical Abstracts Service [97] and used till right now.
A determine that has performed a key function in growing early “structural” approaches for looking chemical databases is the Romanian-born Soviet researcher George Vlăduţ [98]. A chemist by coaching (he defended a PhD in natural chemistry on the Moscow Mendeleev Institute in 1952), he skilled a traumatic encounter with the gargantuan Beilstein handbook in his freshman years [99]. This steered his analysis pursuits in the direction of chemoinformatics [100], a subject wherein he labored for the remainder of his life.
Vlăduţ is credited as one of many pioneers of utilizing graph principle for modeling the constructions and reactions of chemical compounds. In a way, this could not come as a shock: graph principle has been traditionally tied to chemistry, and even the time period ‘graph’ (referring to a set of nodes and edges, quite than a plot of a perform) was launched by the mathematician James Sylvester in 1878 as a mathematical abstraction of chemical molecules [101].

Particularly, Vlăduţ advocated the formulation of molecular construction comparability because the graph isomorphism downside; his most well-known work was on classifying chemical reactions because the partial isomorphism (most frequent subgraph) of the reactant and product molecules [102].
Vlăduţ’s work impressed [103] a pair of younger researchers, Boris Weisfeiler (an algebraic geometer) and Andrey Lehman [104] (self-described as a “programmer” [105]). In a classical joint paper [106], the duo launched an iterative algorithm for testing whether or not a pair of graphs are isomorphic (i.e., the graphs have the identical construction as much as reordering of nodes), which grew to become often known as the Weisfeiler-Lehman (WL) test [107]. Although the 2 had identified one another from college years, their methods parted shortly after their publication and every grew to become completed in his respective subject [108].
Weisfeiler and Lehman’s preliminary conjecture that their algorithm solved the graph isomorphism downside (and does it in polynomial time) was incorrect: whereas Lehman demonstrated it computationally for graphs with at most 9 nodes [109], a bigger counterexample was discovered a 12 months later [110] (and in reality, a strongly common graph failing the WL check known as the Shrinkhande graph had been identified even earlier [111]).

The paper of Weisfeiler and Lehman has turn into foundational in understanding graph isomorphism. To place their work in historic perspective, one ought to do not forget that within the Nineteen Sixties, complexity principle was nonetheless embryonic and algorithmic graph principle was solely taking its first child steps. As Lehman recollected within the late Nineteen Nineties,
“Within the 60s, one may in a matter of days re-discover all of the details, concepts, and methods in graph isomorphism principle. I doubt that the phrase ‘principle’ is relevant; every little thing was at such a primary stage.” — Andrey Lehman, 1999
Their outcome spurred quite a few follow-up works, together with high-dimensional graph isomorphism checks [112]. Within the context of graph neural networks, Weisfeiler and Lehman have just lately turn into family names with the proof of the equivalence of their graph isomorphism check to message passing [113–114].
Although chemists have been utilizing GNN-like algorithms for many years, it’s seemingly that their works on molecular illustration remained virtually unknown within the machine studying group [115]. We discover it onerous to pinpoint exactly when the idea of graph neural networks has begun to emerge: partly as a result of the truth that a lot of the early work didn’t place graphs as a first-class citizen, partially as a result of graph neural networks solely grew to become sensible within the late 2010s, and partly as a result of this subject emerged from the confluence of a number of adjoining analysis areas.
Early types of graph neural networks could be traced again a minimum of to the Nineteen Nineties, with examples together with “Labeling RAAM” by Alessandro Sperduti [116], the “backpropagation by construction” by Christoph Goller and Andreas Küchler [117], and adaptive processing of knowledge constructions [118–119]. Whereas these works have been primarily involved with working over “constructions” (typically bushes or directed acyclic graphs), most of the invariances preserved of their architectures are paying homage to the GNNs extra generally in use right now.

The primary correct remedy of the processing of generic graph constructions (and the coining of the time period ‘graph neural community’) occurred after the flip of the Twenty first century. A College of Siena group led by Marco Gori [120] and Franco Scarselli [121] proposed the primary “GNN.” They relied on recurrent mechanisms, required the neural community parameters to specify contraction mappings, and thus computing node representations by trying to find a hard and fast level — this in itself necessitated a particular type of backpropagation and didn’t rely upon node options in any respect. All the above points have been rectified by the Gated GNN (GGNN) mannequin of Yujia Li [122], which introduced many advantages of recent RNNs, comparable to gating mechanisms [123] and backpropagation by time.
The neural community for graphs (NN4G) proposed by Alessio Micheli across the identical time [124] used a feedforward quite than recurrent structure, in reality resembling extra the trendy GNNs.

One other vital class of graph neural networks, also known as “spectral,” has emerged from the work of Joan Bruna and coauthors [125] utilizing the notion of the Graph Fourier rework. The roots of this development are within the sign processing and computational harmonic evaluation communities, the place coping with non-Euclidean indicators has turn into distinguished within the late 2000s and early 2010s [126].
Influential papers from the teams of Pierre Vandergheynst [127] and José Moura [128] popularised the notion of “Graph Sign Processing” (GSP) and the generalisation of Fourier transforms primarily based on the eigenvectors of graph adjacency and Laplacian matrices. The graph convolutional neural networks counting on spectral filters by Michaël Defferrard [129] and Thomas Kipf and Max Welling [130] are among the many most cited within the subject.
It’s value noting that, whereas the idea of GNNs skilled a number of unbiased rederivations within the 2010s arising from a number of views (e.g., computational chemistry [131,135], digital sign processing [127–128], probabilistic graphical fashions [132], and pure language processing [133]), the truth that all of those fashions arrived at completely different cases of a typical blueprint is actually telling. The truth is, it has just lately been posited [134] that GNNs might provide a common framework for processing discretised information. Different neural architectures we have now mentioned (CNNs or RNNs) could also be recovered as particular instances of GNNs by inserting applicable priors into the message passing capabilities or the graph construction over which the messages are computed.
In a considerably ironic coincidence, trendy GNNs have been triumphantly re-introduced to chemistry, a subject they originated from, by David Duvenaud [131] as a substitute for handcrafted Morgan’s molecular fingerprints, and by Justin Gilmer [135] within the type of message-passing neural networks equal to the Weisfeiler-Lehman check [113–114]. After fifty years, the circle lastly closed.
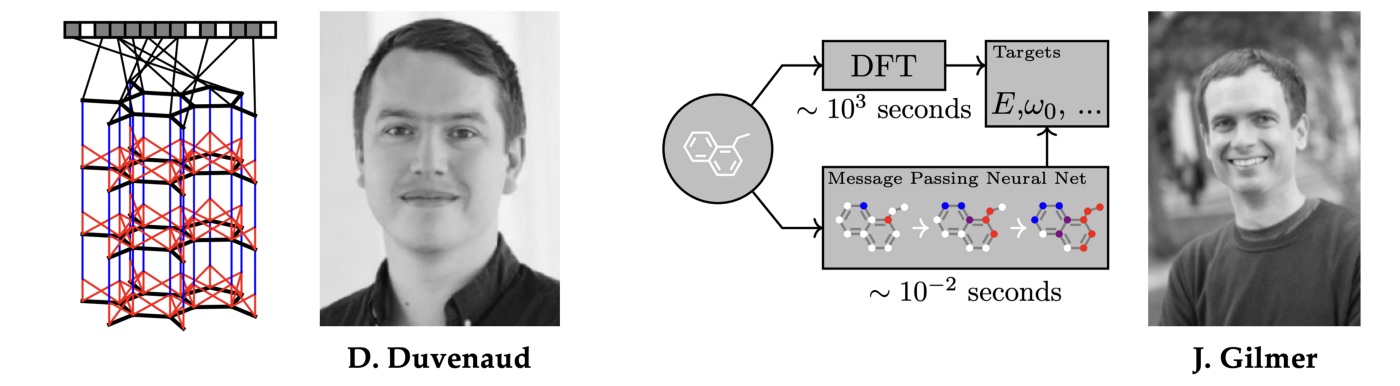
Graph neural networks are actually a normal software in chemistry and have already seen uses in drug discovery and design pipelines. A notable accolade was claimed with the GNN-based discovery of novel antibiotic compounds [136] in 2020. DeepMind’s AlphaFold 2 [137] used equivariant consideration (a type of GNN that accounts for the continual symmetries of the atomic coordinates) as a way to deal with a trademark downside in structural biology — the issue of protein folding.
In 1999, Andrey Lehman wrote to a mathematician colleague that he had the “pleasure to be taught that ‘Weisfeiler-Leman’ was identified and nonetheless brought on curiosity.” He didn’t dwell to see the rise of GNNs primarily based on his work of fifty years earlier. Nor did George Vlăduţ see the realisation of his concepts, lots of which remained on paper throughout his lifetime.
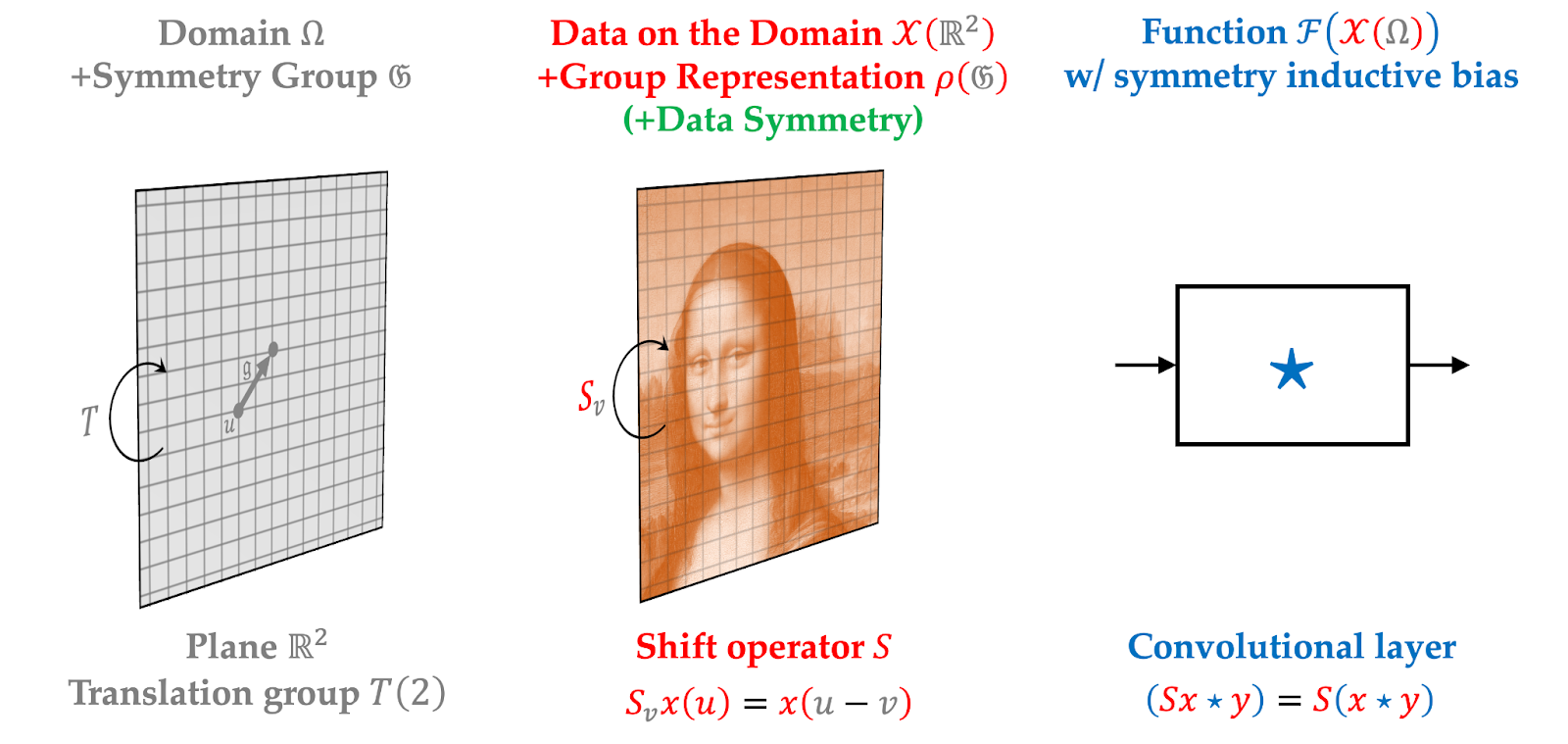
Our historic overview of the geometric foundations of deep studying has now naturally introduced us to the blueprint that underpins this e-book. Taking Convolutional and Graph Neural Networks as two prototypical examples, on the first look fully unrelated, we discover a number of frequent traits. First, each function on information (pictures within the case of CNNs or molecules within the case of GNNs) which have underlying geometric domains (respectively, a grid or a graph).
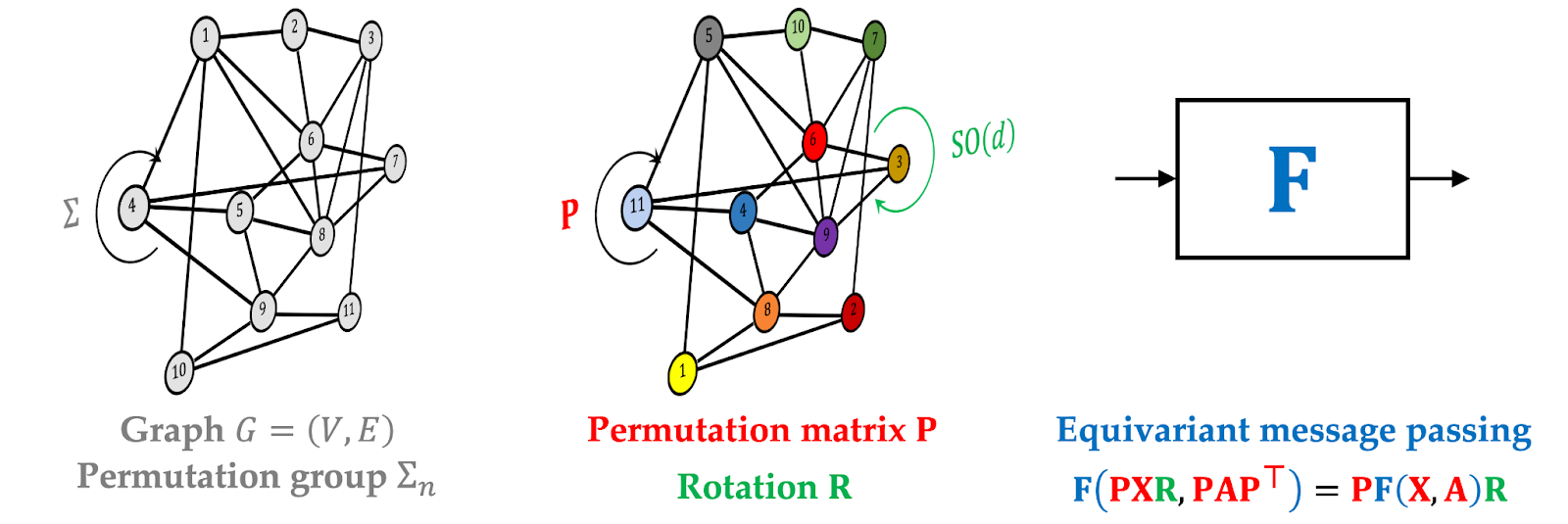
Second, in each instances the duties have a pure notion of invariance (e.g., to the place of an object in picture classification, or the numbering of atoms in a molecule in chemical property prediction) that may be formulated by applicable symmetry group (translation within the former instance and permutation within the latter).
Third, each CNNs and GNNs bake the respective symmetries into their structure by utilizing layers that work together appropriately with the motion of the symmetry group on the enter. In CNNs, it comes within the type of convolutional layers whose output transforms in the identical approach because the enter (this property is named translation-equivariance, which is similar as saying that convolution commutes with the shift operator).
In GNNs, it assumes the type of a symmetric message passing perform that aggregates neighbouring nodes regardless of their order. The general output of a message passing layer transforms no matter permutations of the enter (permutation-equivariant).
Lastly, in some architectural cases, the info are processed in a multi-scale vogue; this corresponds to pooling in CNNs (uniformly sub-sampling the grid that underlies the picture) or graph coarsening in some sorts of GNNs. Total, this seems to be a really normal precept that may be utilized to a broad vary of issues, sorts of information, and architectures.
The Geometric Deep Studying Blueprint can be utilized to derive from first rules a few of the most typical and standard neural community architectures (CNNs, GNNs, LSTMs, DeepSets, Transformers), which as of right now represent the vast majority of the deep studying toolkit. All the above could be obtained by an applicable selection of the area and the related symmetry group.
Additional extensions of the Blueprint, comparable to incorporating further symmetries of the info along with these of the area, will permit acquiring a brand new class of equivariant GNN architectures. Such architectures have just lately come to the highlight within the subject of biochemistry. Particularly, we must always point out the groundbreaking success of AlphaFold 2, addressing the long-standing onerous downside of structural biology: predicting protein folding.
Conclusions and Outlook
In conclusion, we are going to attempt to present an outlook as to what could be subsequent in retailer for Geometric Deep Studying [138]. One apparent query is whether or not one can mechanically uncover symmetries or invariances related to a sure process or dataset, quite than hard-wiring them into the neural community. A number of latest works have answered this query positively [139].
Second, the group theoretical framework underlying the Geometric Deep Studying blueprint is a mathematical abstraction, and in actuality one might want to accommodate transformations that don’t essentially type a bunch. A key idea on this setting is geometric stability [140], which could be interpreted as approximate invariance or equivariance relation [141]. An extension of this notion permits to account for the perturbation of the area, e.g. altering the connectivity of a graph on which a GNN acts [142].
Third, equally to how Klein’s blueprint has led to the event of latest mathematical disciplines together with trendy differential geometry, algebraic topology, and class principle, we see exploiting instruments and concepts from these fields as one attainable subsequent step within the evolution of Geometric Deep Studying. Current works confirmed extensions of GNNs utilizing “unique” constructions from algebraic topology known as mobile sheaves [143], providing architectures which are extra expressive and whose expressive energy could be generalised with out resorting to the Weisfeiler-Lehman formalism [145]. One other line of works makes use of constructions from Class Principle to increase our blueprint past teams [146].
Lastly, being attentive to the deep connections between geometry and physics, we imagine that fascinating insights could be introduced into the evaluation and design of Geometric Deep Studying architectures (particularly, GNNs) by realising them as discretised bodily dynamical programs [146–148].
–
Michael Bronstein is the DeepMind Professor of AI on the College of Oxford. Joan Bruna is Affiliate Professor of Laptop Science on the Courant Institute, New York College. Taco Cohen is Machine Studying Researcher and Principal Engineer at Qualcomm AI Analysis. Petar Veličković is Employees Analysis Scientist at DeepMind and Affiliate Lecturer on the College of Cambridge. The 4 authors are presently engaged on a e-book “Geometric Deep Studying” that may seem with MIT Press.
We’re grateful to Ihor Gorskiy for the hand-drawn portraits and to Tariq Daouda for modifying this put up.
—
[1] H. Weyl, Symmetry (1952), Princeton College Press.
[2] Absolutely titled Strena, Seu De Nive Sexangula (’New 12 months’s reward, or on the Six-Cornered Snowflake’) was, as steered by the title, a small booklet despatched by Kepler in 1611 as a Christmas reward to his patron and buddy Johannes Matthäus Wackher von Wackenfels.
[3] P. Ball, In retrospect: On the six-cornered snowflake (2011), Nature 480 (7378):455–455.
[4] Galois famously described the concepts of group principle (which he thought of within the context of discovering options to polynomial equations) and coined the time period “group” (groupe in French) in a letter to a friend written on the eve of his deadly duel. He requested to speak his concepts to distinguished mathematicians of the time, expressing the hope that they’d be capable of “‘decipher all this mess’” (“‘déchiffrer tout ce gâchis”). Galois died two days later from wounds suffered within the duel aged solely 20, however his work has been transformational in arithmetic.
[5] See biographic notes in R. Tobies, Felix Klein — Mathematician, Academic Organizer, Educational Reformer (2019), The Legacy of Felix Klein 5–21, Springer.
[6] Omar Khayyam is these days primarily remembered as a poet and writer of the immortal line “‘a flask of wine, a e-book of verse, and thou beside me.”
[7] The publication of Euclides vindicatus required the approval of the Inquisition, which got here in 1733 only a few months earlier than the writer’s dying. Rediscovered by the Italian differential geometer Eugenio Beltrami within the nineteenth century, Saccheri’s work is now thought of an early almost-successful try to assemble hyperbolic geometry.
[8] Poncelet was a army engineer and participant in Napoleon’s Russian marketing campaign, the place he was captured and held as a prisoner till the tip of the conflict. It was throughout this captivity interval that he wrote the Traité des propriétés
projectives des figures (‘Treatise on the projective properties of figures,’ 1822) that revived the curiosity in projective geometry. Earlier basis work on this topic was completed by his compatriot Gérard Desargues in 1643.
[9] Within the 1832 letter to Farkas Bolyai following the publication of his son’s outcomes, Gauss famously wrote: “To reward it might quantity to praising myself. For the whole content material of the work coincides nearly precisely with my very own meditations which have occupied my thoughts for the previous thirty or thirty-five years.” Gauss was additionally the primary to make use of the time period ‘non-Euclidean geometry,’ referring strictu sensu to his personal development of hyperbolic geometry. See
R. L. Faber, Foundations of Euclidean and non-Euclidean geometry (1983), Dekker and the blog post in Cantor’s Paradise.
[10] Н. И. Лобачевский, О началах геометрии (1829).
[11] A mannequin for hyperbolic geometry often known as the pseudosphere, a floor with fixed detrimental curvature, was proven by Eugenio Beltrami, who additionally proved that hyperbolic geometry was logically constant. The time period ‘hyperbolic geometry’ was launched by Felix Klein.
[12] For instance, an 1834 pamphlet signed solely with the initials “S.S.” (believed by some to belong to Lobachevsky’s long-time opponent Ostrogradsky) claimed that Lobachevsky made “an obscure and heavy principle” out of “the lightest and clearest chapter of arithmetic, geometry,” questioned why one would print such “ridiculous fantasies,” and steered that the e-book was a “joke or satire.”
[13] A. F. Möbius, Der barycentrische Calcul (1827).
[14] B. Riemann, Über die Hypothesen, welche der Geometrie zu Grunde liegen (1854). See English translation.
[15] In keeping with a preferred perception, repeated in lots of sources together with Wikipedia, the Erlangen Programme was delivered in Klein’s inaugural deal with in October 1872. Klein certainly gave such a chat (although on December 7, 1872), nevertheless it was for a non-mathematical viewers and anxious primarily his concepts of mathematical training; see[4]. The identify “Programme” comes from the subtitle of the revealed brochure [17], Programm zum Eintritt in die philosophische Fakultät und den Senat der ok. Friedrich-Alexanders-Universität zu Erlangen (‘Programme for entry into the Philosophical School and the Senate of the Emperor Friedrich-Alexander College of Erlangen’).
[16] S. Eilenberg and S. MacLane, General theory of natural equivalences (1945), Trans. AMS 58(2):231–294. See additionally J.-P. Marquis, Class Principle and Klein’s Erlangen Program (2009), From a Geometrical Level of View 9–40, Springer. Ideas from class principle can be used to clarify deep studying architectures even past the lens of symmetry, see e.g. P. De Haan et al., Pure graph networks (2020), NeurIPS.
[17] F. Klein, Vergleichende Betrachtungen über neuere geometrische Forschungen (1872). See English translation.
[18] On the time, Göttingen was Germany’s and the world’s main centre of arithmetic. Although Erlangen is pleased with its affiliation with Klein, he stayed there for less than three years, transferring in 1875 to the Technical College of Munich (then known as Technische Hochschule), adopted by Leipzig (1880), and at last settling down in Göttingen from 1886 till his retirement.
[19] Emmy Noether is rightfully considered probably the most vital ladies in arithmetic and one of many biggest mathematicians of the 20th century. She was unfortunate to be born and dwell in an epoch when the educational world was nonetheless entrenched within the medieval beliefs of the unsuitability of ladies for science. Her profession as one of many few ladies in arithmetic having to beat prejudice and contempt was a really trailblazing one. It must be stated to the credit score of her male colleagues that a few of them tried to interrupt the foundations. When Klein and David Hilbert first unsuccessfully tried to safe a educating place for Noether at Göttingen, they met fierce opposition from the educational hierarchs. Hilbert reportedly retorted sarcastically to issues introduced up in a single such dialogue: “I don’t see that the intercourse of the candidate is an argument in opposition to her admission as a Privatdozent. In spite of everything, the Senate will not be a bathhouse”(see C. Reid, Courant in Göttingen and New York: The Story of an Unbelievable Mathematician (1976), Springer). However, Noether loved nice esteem amongst her shut collaborators and college students, and her male friends in Göttingen affectionately referred to her as “Der Noether,” within the masculine (see C. Quigg, Colloquium: A Century of Noether’s Theorem (2019), arXiv:1902.01989).
[20] E. Noether, Invariante Variationsprobleme (1918), König Gesellsch. d. Wiss. zu Göttingen, Math-Phys. 235–257. See English translation.
[21] J. C. Maxwell, A dynamical theory of the electromagnetic field (1865), Philosophical Transactions of the Royal Society of London 155:459–512.
[22] Weyl first conjectured (incorrectly) in 1919 that invariance beneath the change of scale or “gauge” was a neighborhood symmetry of electromagnetism. The time period gauge, or Eich in German, was chosen by analogy to the assorted monitor gauges of railroads. After the event of quantum mechanics, he modified the gauge selection by changing the dimensions issue with a change of wave part in iH. Weyl, Elektron und gravitation (1929), Zeitschrift für Physik 56 (5–6): 330–352. See N. Straumann, Early history of gauge theories and weak interactions (1996), arXiv:hep-ph/9609230.
[23] C.-N. Yang and R. L. Mills, Conservation of isotopic spin and isotopic gauge invariance (1954), Bodily Assessment 96 (1):191.
[24] The time period “Normal Mannequin” was coined by A. Pais and S. B. Treiman, What number of appeal quantum numbers are there? (1975), Physical Review Letters 35(23):1556–1559. The Nobel laureate Frank Wilczek is thought for the criticism of this time period, since, in his phrases “‘mannequin’ connotes a disposable makeshift, awaiting substitute by the ‘actual factor’” whereas “‘customary’ connotes ‘standard’ and hints at superior knowledge.” As an alternative, he steered renaming the Normal Mannequin into “Core Principle.”
[25] P. W. Anderson, More is different (1972), Science 177 (4047): 393–396.
[26] Our assessment is in no way a complete one and goals at highlighting the event of geometric facets of deep studying. Our option to give attention to CNNs, RNNs and GNNs is merely pedagogical and doesn’t indicate there haven’t been different equally vital contributions within the subject.
[27] W. S. McCulloch and W. Pitts, A logical calculus of the ideas immanent in nervous activity (1943), The Bulletin of Mathematical Biophysics 5(4):115–133.
[28] The Dartmouth Summer Research Project on Artificial Intelligence was a 1956 summer time workshop at Dartmouth Faculty that’s thought of to be the founding occasion of the sector of synthetic intelligence.
[29] F. Rosenblatt, The perceptron, a perceiving and recognizing automaton (1957), Cornell Aeronautical Laboratory. The identify is a portmanteau of ‘notion’ and the Greek suffix –τρον denoting an instrument.
[30] M. Minsky and S. A. Papert, Perceptrons: An introduction to computational geometry (1969), MIT Press.
[31] That’s the reason we are able to solely smile at comparable latest claims in regards to the ‘consciousness’ of deep neural networks: אין כל חדש תחת השמש.
[32] Sic in quotes, as “sample recognition” has not but turn into an official time period.
[33] Particularly, Minsky and Papert thought of binary classification issues on a 2D grid (‘retina’ of their terminology) and a set of linear threshold capabilities. Whereas the shortcoming to compute the XOR perform is at all times introduced up as the primary level of criticism within the e-book, a lot of the eye was devoted to geometric predicates comparable to parity and connectedness. This downside is alluded to on the quilt of the e-book, which is adorned by two patterns: one is related, and one other one will not be. Even for a human, it is extremely tough to find out which is which.
[34] E. Kussul, T. Baidyk, L. Kasatkina, and V. Lukovich, Rosenblatt perceptrons for handwritten digit recognition (2001), IJCNN confirmed that Rosenblatt’s 3-layer perceptrons carried out on the Twenty first-century {hardware} obtain an accuracy of 99.2% on the MNIST digit recognition process, which is on par with trendy fashions.
[35] Hilbert’s Thirteenth Problem is without doubt one of the 23 issues compiled by David Hilbert in 1900 and entailing the proof of whether or not an answer exists for all Seventh-degree equations utilizing steady capabilities of two arguments. Kolmogorov and his scholar Arnold confirmed an answer of a generalised model of this downside, which is now often known as the Arnold–Kolmogorov Superposition Theorem.
[36] В. И. Арнольд, О представлении непрерывных функций нескольких переменных суперпозициями непрерывных функций меньшего числа переменных (1956), Доклады Академии Наук СССР 108:179–182.
[37] В. И. Арнольд, О функции трех переменных (1957), Доклады Академии Наук СССР 114:679–681.
[38] H. D. Block, A review of “Perceptrons: An introduction to computational geometry” (1970), Info and Management 17(5): 501–522.
[39] Computational Geometry has topic code I.3.5 within the ACM Computing Classification System.
[40] S.-I. Amari, Feature spaces which admit and detect invariant signal transformations (1978), Joint Convention on Sample Recognition.
[41] T. Sejnowski et al., Studying symmetry teams with hidden items: Past the perceptron (1986), Physica D: Nonlinear Phenomena 22(1–3):260–275.
[42] J. Shawe-Taylor, Constructing symmetries into feedforward networks (1989), ICANN.
[43] J. Shawe-Taylor, Symmetries and discriminability in feedforward community architectures (1993), IEEE Trans. Neural Networks 4(5): 816–826.
[44] G. Cybenko, Approximation by superpositions of a sigmoidal function (1989), Arithmetic of Management, Alerts and Methods 2(4):303–314.
[45] Okay. Hornik, Approximation capabilities of multilayer feedforward networks (1991) Neural Networks 4(2):251–257.
[46] А. Г. Ивахненко, В. Г. Лапа, Кибернетические предсказывающие устройства (1965), Наукова думка.
[47] A. Ivakhnenko, Polynomial theory of complex systems (1971), IEEE Trans. Methods, Man, and Cybernetics 4:364–378.
[48] Backpropagation is predicated on the chain rule of differentiation that itself goes again to the co-inventor of differential calculus Gottfried Wilhelm von Leibniz in 1676. A precursor of backpropagation was utilized by H. J. Kelley, Gradient principle of optimum flight paths (1960), Ars Journal 30(10):947–954 to carry out optimisation of complicated nonlinear multi-stage programs. Environment friendly backpropagation that’s nonetheless in use right now was described within the Finnish grasp’s thesis of S. Linnainmaa, Algoritmin kumulatiivinen pyoristysvirhe yksittaisten pyoristysvirheiden taylor-kehitelmana (1970), College of Helsinki. The earliest use in neural networks is because of P. J. Werbos, Purposes of advances in nonlinear sensitivity evaluation (1982), System Modeling and Optimization 762–770, Springer, which is normally cited because the origin of the tactic. See J. Schmidhuber, Deep learning in neural networks: An overview (2015), Neural Networks 61:85–117.
[49] D. E. Rumelhart, G. E. Hinton, and R. J. Williams, Learning representations by back-propagating errors (1986), Nature 323(6088):533–536.
[50] There are even examples of steady nowhere differentiable functions comparable to the development of Weierstrass (1872).
[51] Roughly, Lipschitz-continuous capabilities don’t arbitrarily shrink or increase the gap between factors on the area. For differentiable capabilities, Lipschitz continuity could be expressed as an higher certain on the norm of the gradient, implying that the perform doesn’t ‘leap’ too abruptly.
[52] The primary to make use of the time period was Richard Bellman within the preface of his 1957 e-book Dynamic Programming, the place he refers to dimensionality as “a curse which has hung over the pinnacle of the physicist and astronomer for a lot of a 12 months.”
[53] The variety of protons within the observable universe, often known as the Eddington number, is estimated at 10⁸⁰.
[54] J. Lighthill, Artificial intelligence: A general survey (1973) Synthetic Intelligence 1–21, Science Analysis Council London.
[55] D. H. Hubel and T. N. Wiesel, Receptive fields of single neurones within the cat’s striate cortex (1959), The Journal of Physiology 148(3):574.
[56] D. H. Hubel and T. N. Wiesel, Receptive fields, binocular interplay and useful structure within the cat’s visible cortex (1962), The Journal of Physiology 160(1):106.
[57] The time period ‘receptive subject’ predates Hubel and Wiesel and was utilized by neurophysiologists from the early twentieth century, see C. Sherrington, The integrative motion of the nervous system (1906), Yale College Press.
[58] The time period ‘grandmother cell’ is more likely to have first appeared in Jerry Lettvin’s course ‘Organic Foundations for Notion and Data’ held at MIT in 1969. The same idea of ‘gnostic neurons’ was launched two years earlier in a e-book by Polish neuroscientist J. Konorski, Integrative exercise of the mind; an interdisciplinary strategy (1967). See C. G. Gross, Genealogy of the “grandmother cell” (2002), The Neuroscientist 8(5):512–518.
[59] Okay. Fukushima, Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position (1980), Organic Cybernetics 36:196– 202. The shift-invariance property is alluded to within the title.
[60] Usually misspelled as ‘neurocognitron’, the identify ‘neocognitron’ suggests it was an improved model of an earlier structure of Okay. Fukushima, Cognitron: a self-organizing multilayered neural community (1975), Organic Cybernetics 20:121–136.
[61] Within the phrases of the writer himself, having an output that’s “dependent solely upon the form of the stimulus sample, and isn’t affected by the place the place the sample is offered.”
[62] We seek advice from this precept as scale separation, which, like symmetry, is a basic property of many bodily programs. In convolutional architectures, scale separation permits coping with a broader class of geometric transformations along with translations.
[63] ReLU-type activations date again to a minimum of the Nineteen Sixties and have been beforehand employed in Okay. Fukushima, Visible function extraction by a multilayered community of analog threshold components (1969), IEEE Trans. Methods Science and Cybernetics 5(4):322–333.
[64] Université Pierre-et-Marie-Curie, right now a part of the Sorbonne College.
[65] Y. LeCun et al., Backpropagation utilized to handwritten zip code recognition (1989) Neural Computation 1(4):541–551.
[66] In LeCun’s 1989 paper, the structure was not named; the time period ‘convolutional neural community’ or ‘convnet’ would seem in a later paper in 1998 [68].
[67] LeCun’s first CNN was educated on a CPU (a SUN-4/250 machine). Nonetheless, the picture recognition system utilizing a educated CNN was run on AT&T DSP-32C (a second-generation digital sign processor with 256KB of reminiscence able to performing 125m floating-point multiply-and-accumulate operations per second with 32-bit precision), attaining over 30 classifications per second.
[68] Y. LeCun et al., Gradient-based studying utilized to doc recognition (1998), Proc. IEEE 86(11): 2278–2324.
[69] Probably the most standard function descriptors was the scale-invariant feature transform (SIFT), launched by David Lowe in 1999. The paper was rejected a number of instances and appeared solely 5 years later, D. G. Lowe, Distinctive picture options from scale-invariant keypoints, (2004) IJCV 60(2):91–110. It is without doubt one of the most cited pc imaginative and prescient papers.
[70] A prototypical strategy was “bag-of-words” representing pictures as histograms of vector-quantised native descriptors. See e.g. J. Sivic and A. Zisserman, Video Google: A textual content retrieval strategy to object matching in movies (2003), ICCV.
[71] Because it typically occurs, it’s onerous to level to the primary RNN design. Recurrence in neural networks was already described McCulloch and Pitts [27], who famous that “the nervous system incorporates many round paths” and referred to “exact specification of those implications by the use of recursive capabilities and willpower of these that may be embodied within the exercise of nervous nets.” The e-book M. Minsky, Computation: Finite and Infinite Machines (1967), Prentice-Corridor, makes use of McCulloch-Pitts neurons and calls recurrent architectures “networks with cycles.” D. E. Rumelhart, G. E. Hinton, and R. J. Williams, Studying inner representations by error propagation (1985), ICS Report (an earlier model of the well-known Nature paper [49] by the identical authors) incorporates generalisations for studying in RNNs, that are named “recurrent nets,” and credit to Minsky and Papert [30].
[72] M. I. Jordan, Serial Order: A parallel distributed processing strategy (1986), ICS Report.
[73] J. L. Elman, Discovering construction in time (1990), Cognitive Science 14(2):179–211.
[74] S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, TUM, 1991. The paper presenting LSTMs was initially rejected from NIPS in 1995 and appeared solely two years later as S. Hochreiter, J. Schmidhuber, Lengthy Quick-Time period Reminiscence (1997) Neural Computation 9(8):1735-1780.
[75] See additionally Y. Bengio et al., Studying long-term dependencies with gradients is tough (1994), Trans. Neural Networks 5(2):157–166 and R. Pascanu et al., On the difficulty of training recurrent neural networks (2003), ICML.
[76] F. A. Gers and J. Schmidhuber. LSTM recurrent networks be taught easy context free and context delicate languages (2001), IEEE Transactions on Neural Networks 12(6):1333-1340.
[77] A. Graves et al., Biologically believable speech recognition with LSTM neural nets (2004), Workshop on Biologically Impressed Approaches to Superior Info Expertise.
[78] C. Tallec and Y. Ollivier, Can recurrent neural networks warp time? (2018), ICLR.
[79] Okay. Cho et al., On the properties of neural machine translation: Encoder–decoder approaches (2014), ACL.
[80] Particularly, the group of Jürgen Schmidhuber developed deep large-scale CNN fashions that gained a number of imaginative and prescient competitions, together with Chinese language character recognition (D. C. Ciresan et al., Deep huge easy neural nets for handwritten digit recognition (2010), Neural Computation 22(12):3207–3220) and site visitors signal recognition (D. C. Ciresan et al., Multi-column deep neural community for site visitors signal classification, Neural Networks 32:333–338, 2012).
[81] A. Krizhevsky, I. Sutskever, and G. E. Hinton, ImageNet classification with deep convolutional neural networks (2012), NIPS.
[82] AlexNet achieved an error over 10.8% smaller than the runner up.
[83] AlexNet had eleven layers was educated on 1.2M pictures from ImageNet (for comparability, LeNet-5 had 5 layers and was educated on 60K MNIST digits). Further vital adjustments in comparison with LeNet-5 have been the usage of ReLU activation (as a substitute of tanh), most pooling, dropout regularisation, and information augmentation.
[84] It took almost every week to coach AlexNet on a pair of Nvidia GTX 580 GPUs, able to ~200G FLOP/sec.
[85] Although GPUs have been initially designed for graphics purposes, they turned out to be a handy {hardware} platform for general-purpose computations (“GPGPU”). First such works confirmed linear algebra algorithms, see e.g. J. Krüger and R. Westermann, Linear algebra operators for GPU implementation of numerical algorithms (2003), ACM Trans. Graphics 22(3):908–916. The primary use of GPUs for neural networks was by Okay.-S. Oh and Okay. Jung, GPU implementation of neural networks (2004), Sample Recognition 37(6):1311–1314, predating AlexNet by almost a decade.
[86] C. Metz, An infusion of AI makes Google Translate more powerful than ever (2016), Wired.
[87] A. Sidorov, Transitioning entirely to neural machine translation (2017), Meta Engineering Weblog.
[88] Initially Pharmaceutisches Central-Blatt, it was the oldest German chemical abstracts journal revealed between 1830 and 1969.
[89] Named after Leopold Gmelin who revealed the primary model in 1817, the Gmelins Handbuch final print version appeared within the Nineteen Nineties. The database presently incorporates 1.5 million compounds and 1.3 million completely different reactions found between 1772 and 1995.
[90] In 1906, the American Chemical Society authorised the publication of Chemical Abstracts, charging it with the mission of abstracting the world’s literature of chemistry and assigning an preliminary price range of fifteen thousand {dollars}. The primary publication appeared in 1907 beneath the stewardship of William Noyes. Over a century since its institution, the CAS incorporates almost 200 million natural and inorganic substances disclosed in publications because the early 1800s.
[91] M. Gordon, C. E. Kendall, and W. H. T. Davison, Chemical Ciphering: a Common Code as an Help to Chemical Systematics (1948), The Royal Institute of Chemistry.
[92] A particular goal pc (“Digital Structural Correlator”), for use along side a punch card sorter, was proposed by the Gordon-Kendall-Davison group in reference to their system of chemical ciphering, however by no means constructed.
[93] There have been a number of contemporaneous programs that competed with one another, see W. J. Wisswesser, 107 Years of line-formula notations (1968), J. Chemical Documentation 8(3):146–150.
[94] A. Opler and T. R. Norton, A Guide for programming computer systems to be used with a mechanized system for looking natural compounds (1956), Dow Chemical Firm.
[95] L. C. Ray and R. A. Kirsch, Discovering chemical data by digital computer systems (1957), Science 126(3278):814–819.
[96] H. L. Morgan. The technology of a novel machine description for chemical constructions — a way developed at Chemical Abstracts Service (1965), J. Chemical Documentation 5(2):107–113.
[97] Not a lot biographical info is out there about Harry Morgan. In keeping with an obituary, after publishing his well-known molecular fingerprints paper, he moved to a managerial place at IBM, the place he stayed till retirement in 1993. He died in 2007.
[98] In Russian publications, Vlăduţ’s identify appeared as Георгий Эмильевич Влэдуц, transliterated as Vleduts or Vladutz. We stick right here to the unique Romanian spelling.
[99] In keeping with Vladimir Uspensky, Vlăduţ informed the anecdote of his encounter with Beilstein within the first lecture of his undergraduate course on natural chemistry throughout his Patterson-Crane Award acceptance speech on the American Chemical Society. See В. А. Успенский, Труды по нематематике (2002).
[100] Г. Э. Влэдуц, В. В. Налимов, Н. И. Стяжкин, Научная и техническая информация как одна из задач кибернетики (1959), Успехи физических наук 69:1.
[101] J. J. Sylvester, Chemistry and algebra (1878), Nature 17:284.
[102] G. E. Vleduts, Regarding one system of classification and codification of natural reactions (1963), Info Storage and Retrieval 1:117–146.
[103] We have been unable to search out stable proof of whether or not or how Weisfeiler and Lehman interacted with Vlăduţ, as the general public who had identified each are actually lifeless. The strongest proof is a remark of their classical paper [106] acknowledging Vlăduţ for “formulating the issue” (“авторы выражают благодарность В. Э. Влэдуцу за постановку задачи”). Additionally it is sure that Weisfeiler and Lehman have been conscious of the strategies developed within the chemical group, particularly the tactic of Morgan [96], whom they cited of their paper as a “comparable process.”
[104] Andrey Lehman’s surname is commonly additionally spelled Leman, a variant that he most popular himself, stating in an email that the previous spelling arose from a e-book by the German writer Springer who believed “that each Leman is a hidden Lehman”. Since Lehman’s household had Teutonic origins by his personal admission, we follow the German spelling.
[105] Lehman unsuccessfully tried to defend a thesis primarily based on his work on graph isomorphism in 1971, which was rejected because of the private enmity of the pinnacle of the dissertation committee with a verdict “it’s not arithmetic.” To this, Lehman bitterly responded: “I’m not a mathematician, I’m a programmer.” He ultimately defended one other dissertation in 1973, on subjects in databases.
[106] Б. Вейсфейлер, А. Леман, Приведение графа к каноническому виду и возникающая при этом алгебра (1968), Научно-техн. информ. Сб. ВИНИТИ 2(9):12–16 (see English translation).
[107] There are in reality a number of variations of the Weisfeiler-Lehman check. The unique paper [106] described what’s now known as the “2-WL check,” which is nonetheless equal to 1-WL or node color refinement algorithm. See our previous blog post on the Weisfeiler-Lehman checks.
[108] Since little biographical info is out there in English on our heroes of yesteryear, we are going to use this observe to stipulate the remainder of their careers. All of the three ended up in the US. George Vlăduţ utilized for emigration in 1974, which was a shock to his bosses and resulted in his demotion from the pinnacle of laboratory put up (emigration was thought of a “mortal sin” within the USSR — to individuals from the West, it’s now onerous to think about what an epic effort it was once for Soviet residents). Vlăduţ left his household behind and labored on the Institute for Scientific Info in Philadelphia till his dying in 1990. Being of Jewish origin, Boris Weisfeiler determined to to migrate in 1975 as a result of rising official antesemitism within the USSR — the final drop was the refusal to publish a monograph on which he had labored extensively as too many authors had “non-Russian final names.” He grew to become a professor at Pennsylvania State College engaged on algebraic geometry after a brief interval of keep on the Institute for Superior Examine in Princeton. An avid mountaineer, he disappeared throughout a hike in Chile in 1985 (see the account of Weisfeiler’s nephew). Andrey Lehman left the USSR in 1990 and subsequently labored as programmer in a number of American startups. He died in 2012 (see Sergey Ivanov’s post).
[109] А. Леман, Об автоморфизмах некоторых классов графов (1970), Автоматика и телемеханика 2:75–82.
[110] G. M. Adelson-Velski et al., An instance of a graph which has no transitive group of automorphisms (1969), Dokl. Akad. Nauk 185:975–976.
[111] S. S. Shrikhande, The distinctiveness of the L₂ affiliation scheme (1959), Annals of Mathematical Statistics 30:781–798.
[112] L. Babai, Graph isomorphism in quasipolynomial time (2015), arXiv:1512.03547.
[113] Okay. Xu et al., How powerful are graph neural networks? (2019), ICLR.
[114] C. Morris et al., Weisfeiler and Leman go neural: Higher-order graph neural networks (2019), AAAI.
[115] Within the chemical group, a number of works proposed GNN-like fashions together with D. B. Kireev, Chemnet: a novel neural community primarily based technique for graph/property mapping (1995), J. Chemical Info and Laptop Sciences 35(2):175–180; I. I. Baskin, V. A. Palyulin, and N. S. Zefirov. A neural system for looking direct correlations between constructions and properties of chemical compounds (1997), J. Chemical Info and Laptop Sciences 37(4): 715–721; and C. Merkwirth and T. Lengauer. Computerized technology of complementary descriptors with molecular graph networks (2005), J. Chemical Info and Modeling, 45(5):1159–1168.
[116] A. Sperduti, Encoding labeled graphs by labeling RAAM (1994), NIPS.
[117] C. Goller and A. Kuchler, Studying task-dependent distributed representations by backpropagation by construction (1996), ICNN.
[118] A. Sperduti and A. Starita. Supervised neural networks for the classification of constructions (1997), IEEE Trans. Neural Networks 8(3):714–735.
[119] P. Frasconi, M. Gori, and A. Sperduti, A normal framework for adaptive processing of knowledge constructions (1998), IEEE Trans. Neural Networks 9(5):768–786.
[120] M. Gori, G. Monfardini, and F. Scarselli, A new model for learning in graph domains (2005), IJCNN.
[121] F. Scarselli et al., The graph neural network model (2008), IEEE Trans. Neural Networks 20(1):61–80.
[122] Y. Li et al., Gated graph sequence neural networks (2016) ICLR.
[123] Okay. Cho et al., Studying phrase representations utilizing RNN encoder-decoder for statistical machine translation (2014), arXiv:1406.1078.
[124] A. Micheli, Neural network for graphs: A contextual constructive approach (2009), IEEE Trans. Neural Networks 20(3):498–511.
[125] J. Bruna et al., Spectral networks and locally connected networks on graphs (2014), ICLR.
[126] It’s value noting that within the subject of pc graphics and geometry processing, non-Euclidean harmonic evaluation predates Graph Sign Processing by a minimum of a decade. We will hint spectral filters on manifolds and meshes to the works of G. Taubin, T. Zhang, and G. Golub, Optimal surface smoothing as filter design (1996), ECCV. These strategies grew to become mainstream within the 2000s following the influential papers of Z. Karni and C. Gotsman, Spectral compression of mesh geometry (2000), Laptop Graphics and Interactive Methods, and B. Lévy, Laplace-Beltrami eigenfunctions towards an algorithm that “understands” geometry (2006), Form Modeling and Purposes.
[127] D. I. Shuman et al., The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains (2013), IEEE Sign Processing Journal 30(3):83–98.
[128] A. Sandryhaila and J. M. F. Moura, Discrete signal processing on graphs (2013), IEEE Trans. Sign Processing 61(7):1644–1656.
[129] M. Defferrard, X. Bresson, and P. Vandergheynst, Convolutional neural networks on graphs with fast localized spectral filtering (2016), NIPS.
[130] T. Kipf and M. Welling, Semi-supervised classification with graph convolutional networks (2017), ICLR.
[131] D. Okay. Duvenaud et al., Convolutional networks on graphs for learning molecular fingerprints (2015), NIPS.
[132] H. Dai, B. Dai, and L. Track, Discriminative embeddings of latent variable fashions for structured information (2016), ICML.
[133] A. Vaswani et al., Consideration is all you want (2017), NIPS.
[134] P. Veličković, Message passing all the way in which up (2022), arXiv:2202.11097.
[135] J. Gilmer et al., Neural message passing for quantum chemistry (2017), ICML.
[136] J. M. Stokes et al., A deep learning approach to antibiotic discovery (2020) Cell 180(4):688–702.
[137] J. Jumper et al., Highly accurate protein structure prediction with AlphaFold, Nature 596:583–589, 2021.
[138] One ought to keep in mind that making predictions in ML is a dangerous process as the sector evolves very quickly, so we’re totally conscious that our outlook won’t age properly.
[139] N. Dehmamy et al., Computerized Symmetry Discovery with Lie Algebra Convolutional Community (2021), arXiv:2109.07103.
[140] Roughly, geometric stability implies that if the enter of a G-invariant perform f(x) is subjected to a change h that’s ε-distant from the group G, then ∥f(x)–f(h.x)∥ ≤ 𝒪(ε). In pictures with the two-dimensional translation group G=T(2), one can contemplate warpings of the shape τ:ℝ²→ℝ² with the Dirichlet power ∥∇τ∥ measuring how far it’s from a translation.
[141] J. Bruna and S. Mallat, Invariant scattering convolutional networks (2012), PAMI 35(8):1872–1886.
[142] See e.g. R. Levie et al., Transferability of spectral Graph Convolutional Neural Networks (2021) JMLR 22:1–59.
[143] C. Bodnar, F. Di Giovanni, et al., Neural sheaf diffusion: A topological perspective on heterophily and oversmoothing in GNNs (2022) NeurIPS. See an accompanying blog post.
[144] P. de Haan, T. Cohen, and M. Welling, Pure Graph Networks (2020) NeurIPS.
[145] A. Dudzik and P. Veličković, Graph Neural Networks are Dynamic Programmers (2022), arXiv:2203.15544.
[146] B. Chamberlain et al., GRAND: Graph Neural Diffusion (2021) ICML. See additionally an accompanying blog post.
[147] F. Di Giovanni, J. Rowbottom et al., Graph Neural Networks as Gradient Flows (2022), arXiv:2206.10991.
[148] H. Tanaka and D. Kunin, Noether’s studying dynamics: Position of symmetry breaking in neural networks (2021), arXiv:2105.02716.
[ad_2]
Source link
