

[ad_1]

Textual content Classification is the method of categorizing textual content into a number of totally different courses to arrange, construction, and filter into any parameter. For instance, textual content classification is utilized in authorized paperwork, medical research and recordsdata, or so simple as product critiques. Knowledge is extra essential than ever; corporations are spending fortunes attempting to extract as many insights as doable.
With textual content/doc information being far more considerable than different information varieties, new strategies of using them are crucial. Since information is inherently unstructured and very plentiful, organizing information to know it in digestible methods can drastically enhance its worth. Utilizing Textual content Classification with Machine Studying can mechanically construction related textual content in a quicker and more cost effective manner.
We’ll outline textual content classification, the way it works, a few of its most identified algorithms, and supply information units which may assist begin your textual content classification journey.
Why Use Machine Studying Textual content Classification?
- Scale: Guide information entry, evaluation, and organizing are tedious and gradual. Machine Studying permits for an automated evaluation that may be utilized to datasets regardless of how large or small.
- Consistency: Human error happens as a consequence of fatigue and desensitization to materials within the dataset. Machine studying will increase the scalability and drastically improves accuracy because of the unbiased nature and consistency of the algorithm.
- Velocity: Knowledge generally could should be accessed and arranged rapidly. A machine-learned algorithm can parse by way of information to ship data in a digestible method.
Getting Began With 6 Common Steps

Some fundamental strategies can classify totally different textual content paperwork to a sure diploma, however probably the most generally used strategies contain machine studying. There are six fundamental steps {that a} textual content classification mannequin goes by way of earlier than being deployed.
1. Offering a Excessive-High quality Dataset
Datasets are uncooked information chunks used as the info supply to gas our mannequin. Within the case of textual content classification, supervised machine studying algorithms are used, thus offering our machine studying mannequin with labeled information. Labeled information is information predefined for our algorithm with an informative tag hooked up to it.
2. Filtering and processing the info
As machine studying fashions can solely perceive numerical values, tokenization and phrase embedding of the supplied textual content will probably be crucial for the mannequin to accurately acknowledge information.
Tokenization is the method of splitting textual content paperwork into smaller items known as tokens Tokens may be represented as the whole phrase, a sub-word, or a person character. For instance, tokenizing the work smarter may be accomplished as so:
- Token Phrase: Smarter
- Token Subword: Good-er
- Token Character: S-m-a-r-t-e-r
Tokenization is essential as a result of textual content classification fashions can solely course of information on a token-based degree and can’t perceive and course of full sentences. Additional processing on the given uncooked dataset could be required for our mannequin to simply digest the given information. Take away pointless options, filtering out null and infinite values, and extra. Shuffling the whole dataset would assist forestall any biases through the coaching part.
3. Splitting our dataset right into a coaching and testing datasets
We wish to practice out information on 80% of the dataset whereas reserving 20% of the info set to check the algorithm for accuracy.
4. Practice the Algorithm
By operating our mannequin with the coaching dataset, the algorithm can categorize the supplied texts into totally different classes by figuring out hidden patterns and insights.
5. Testing and checking the mannequin’s efficiency
Subsequent, check the mannequin’s integrity utilizing the testing information set as talked about in step 3. The testing dataset will probably be unlabeled to check the mannequin’s accuracy in opposition to the precise outcomes. To precisely check the mannequin the testing dataset should comprise new check instances (totally different information than the earlier coaching dataset) to keep away from overfitting our mannequin.
6. Tuning the mannequin
Tune the machine studying mannequin by adjusting the mannequin’s totally different hyperparameters with out overfitting or making a excessive variance. A hyperparameter is a parameter whose worth controls the educational strategy of the mannequin. You are now able to deploy!
Phrase Embedding
Within the filtering course of talked about earlier, machine and deep studying algorithms can solely perceive numerical values, forcing us to carry out some phrase embedding strategies on our information set. Phrase embedding is the method of representing phrases into actual worth vectors that may encode the that means of the given phrase.
- Word2Vec: An unsupervised phrase embedding methodology developed by Google. It makes use of neural networks to study from massive textual content information units. Because the identify implies, the Word2Vec method converts every phrase right into a given vector.
- GloVe: Often known as World Vector, is an unsupervised machine studying mannequin for acquiring vector representations of phrases. Just like the Word2Vec methodology, the GloVe algorithm maps phrases into significant areas the place the gap between the phrases is said to semantic similarity.
- TF-IDF: Quick for time period frequency-inverse doc frequency, TF-IDF is a phrase embedding algorithm that evaluates how essential a phrase is inside a given doc. The TF-IDF assigns every phrase a given rating to suggest its significance in a set of paperwork.
Listed here are three of probably the most well-known and efficient textual content classification algorithms. Consider there are additional defining algorithms embedded inside every methodology.
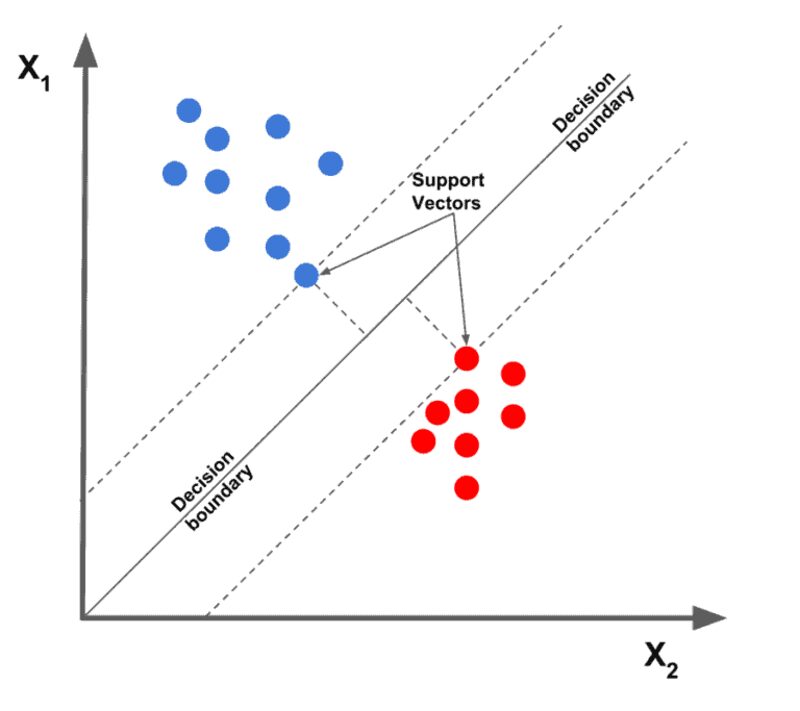
1. Linear Help Vector Machine
Considered the most effective textual content classification algorithms on the market, the linear help vector machine algorithm plots the given information factors regarding their given options, then attracts a finest match line to separate and categorize the info into totally different courses.
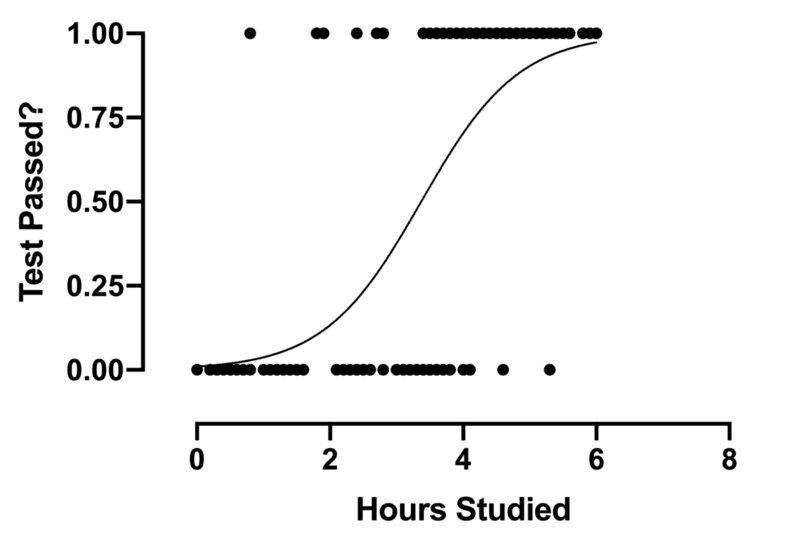
2. Logistic Regression
Logistic regression is a sub-class of regression that focuses primarily on classification issues. It makes use of a call boundary, regression, and distance to judge and classify the dataset.
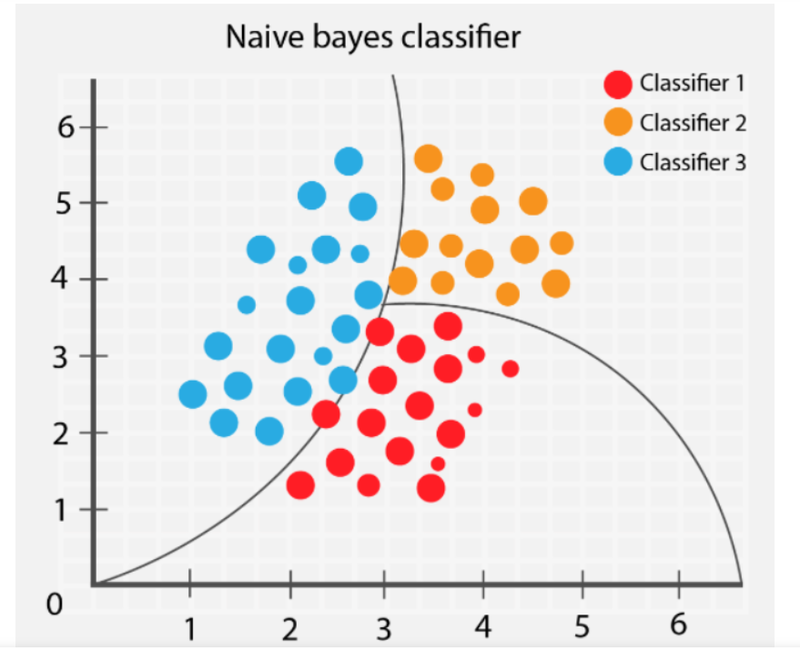
3. Naive Bayes
The Naive Bayes algorithm classifies totally different objects relying on their supplied options. It then attracts group boundaries to extrapolate these group classification to resolve and categorize additional.
Overcrowded Coaching Knowledge
Offering your algorithm with low-quality information will end in poor future predictions. Nevertheless, a quite common drawback amongst machine studying practitioners is feeding the coaching mannequin with a knowledge set that’s too detailed that embody pointless options. Overcrowding the info with irrelevant information can lead to a lower in mannequin efficiency. In terms of selecting and organizing a knowledge set, Much less is Extra.
Fallacious coaching to testing information ratios will can enormously have an effect on your mannequin’s efficiency and have an effect on shuffling and filtering. With exact information factors that aren’t skewed by different unneeded components, the coaching mannequin will carry out extra effectively.
When coaching your mannequin select a knowledge set that matches your mannequin’s necessities, filter the pointless values, shuffle the info set, and check your ultimate mannequin for accuracy. Less complicated algorithms take much less computing time and sources; one of the best fashions are the only ones that may clear up complicated issues.
Overfitting and Underfitting
Accuracy of fashions when coaching reaches a peak after which slowly tapers off as coaching continues. That is known as overfitting; the mannequin begins to learns unintended patterns since coaching has lasted too lengthy . Be cautious when attaining excessive accuracy on the coaching set because the most important aim is to develop fashions which have their accuracy rooted within the testing set (information the mannequin has not seen earlier than).
On the opposite finish, underfitting is when the coaching mannequin nonetheless has room for enchancment and has not but reached its most potential. Poorly skilled fashions stem from the size of time skilled or is over-regularized to the dataset. This exemplifies the purpose of getting concise and exact information.
Discovering the candy spot when coaching a mannequin is essential. Splitting the dataset 80/20 is an effective begin, however tuning the parameters could also be what your particular mannequin must carry out at its finest.
Incorrect Textual content Format
Though not closely talked about on this article, utilizing the right textual content format to your textual content classification drawback will result in higher outcomes. Some approaches to representing your textual information embody GloVe, Word2Vec, and embedding fashions.
Utilizing the right Textual content Format will enhance how the mannequin reads and interprets the dataset and in flip, helps it perceive the patterns.

- Filtering Spam: By trying to find sure key phrases, an e mail may be categorized as helpful or spam.
- Categorizing Textual content: Through the use of textual content classifications, purposes can categorize totally different objects(articles, books, and so on) into totally different courses by classifying associated texts such because the merchandise identify, description, and so forth. Utilizing such strategies can enhance the expertise because it makes it simpler for customers to navigate all through a database.
- Figuring out Hate Speech: Sure social media corporations use textual content classification to detect and ban feedback or posts with offensive mannerisms as not permitting any variation of profanity to be typed out and chatted in a multiplayer youngsters’s recreation.
- Advertising and marketing and Promoting: Firms could make particular adjustments to fulfill their clients by understanding how customers react to sure merchandise. It could additionally advocate sure merchandise relying on consumer critiques towards related merchandise. Textual content classification algorithms can be utilized along side recommender methods, one other deep studying algorithm that many on-line web sites use to achieve repeat enterprise.
With tons of labeled and ready-to-use datasets on the market, you possibly can all the time seek for the proper information set that matches your mannequin’s necessities.
When you can face some issues when deciding which one to make use of, within the coming half we are going to advocate among the most well-known datasets on the market which are accessible for public use.
Web sites similar to Kaggle comprise quite a lot of datasets overlaying all matters. Strive operating your mannequin on a few the above-mentioned information units for apply!
With machine studying having huge affect within the final decade, corporations try each doable methodology to make the most of machine studying to automate processes. Evaluations, feedback, posts, articles, journals, and documentation all maintain priceless worth in textual content. With Textual content Classification utilized in many artistic methods to extract consumer insights and patterns, corporations could make choices backed by information; professionals can acquire and study precious data faster than ever.
Kevin Vu manages Exxact Corp weblog and works with lots of its proficient authors who write about totally different features of Deep Studying.
Original. Reposted with permission.
[ad_2]
Source link
