


[ad_1]
The final two years have been a number of the most enjoyable and extremely anticipated in Automated Speech Recognition’s (ASR’s) lengthy and wealthy historical past, as we noticed a number of enterprise-level absolutely neural network-based ASR fashions go to market (e.g. Alexa, Rev, AssemblyAI, ASAPP, and so on). The accelerated success of ASR deployments is because of many elements, together with the rising ecosystem of freely accessible toolkits, extra open supply datasets, and a rising curiosity on the a part of engineers and researchers within the ASR downside. This confluence of forces has produced a tremendous momentum shift in industrial ASR. We actually are on the onset of huge adjustments within the ASR area and of huge adoption of the know-how.
These developments will not be solely enhancing current makes use of of the know-how, similar to Siri’s and Alexa’s accuracies, however they’re additionally increasing the market ASR know-how serves. For instance, as ASR will get higher with very noisy environments, it may be used successfully in police body cams, to routinely report and transcribe interactions. Protecting a report of necessary interactions, and maybe figuring out interactions earlier than they develop into harmful, might save lives. We’re seeing extra firms providing automated captions to stay movies, making stay content material accessible to extra folks. These new use-cases and prospects are pushing the necessities for ASR, which is accelerating analysis.
What’s Subsequent for ASR?
“By 2030, speech recognition will characteristic actually multilingual fashions, wealthy standardized output objects, and be accessible to all and at scale. People and machines will collaborate seamlessly, permitting machines to be taught new phrases and speech kinds organically. Lastly, speech recognition will engender the rules of accountable AI, and function with out bias.”
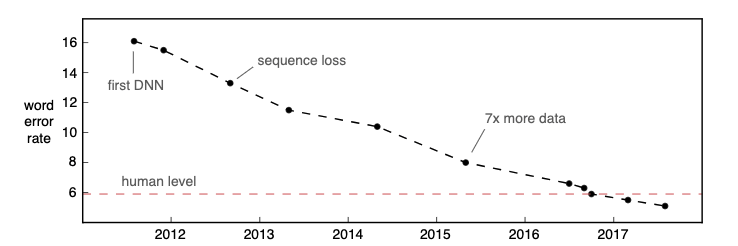
Supply: Hannun, Awni, “Speech Recognition is not Solved”.
In 2016, 6 years in the past already, Microsoft Research published an article saying they’d reached human efficiency (as measured utilizing Word Error Rate, WER) on a 25-year outdated knowledge set known as Switchboard. As Zelasko et al. have identified, such optimistic outcomes don’t maintain up on knowledge reflecting pure human speech spoken by a various inhabitants.
However, ASR accuracy has continued to enhance, reaching human parity on extra datasets and in additional use instances. On high of constant to push the bounds of accuracy for English techniques, and, in doing so, redefining how we measure accuracy as we method human-level accuracy, we foresee 5 necessary areas the place analysis and industrial techniques will evolve within the subsequent ten years.
Really Multilingual ASR Fashions
“Within the subsequent decade, we see absolutely multilingual fashions being deployed in manufacturing environments, enabling builders to construct purposes that may perceive anyone in any language, actually unlocking the ability of speech recognition to the world at giant.”
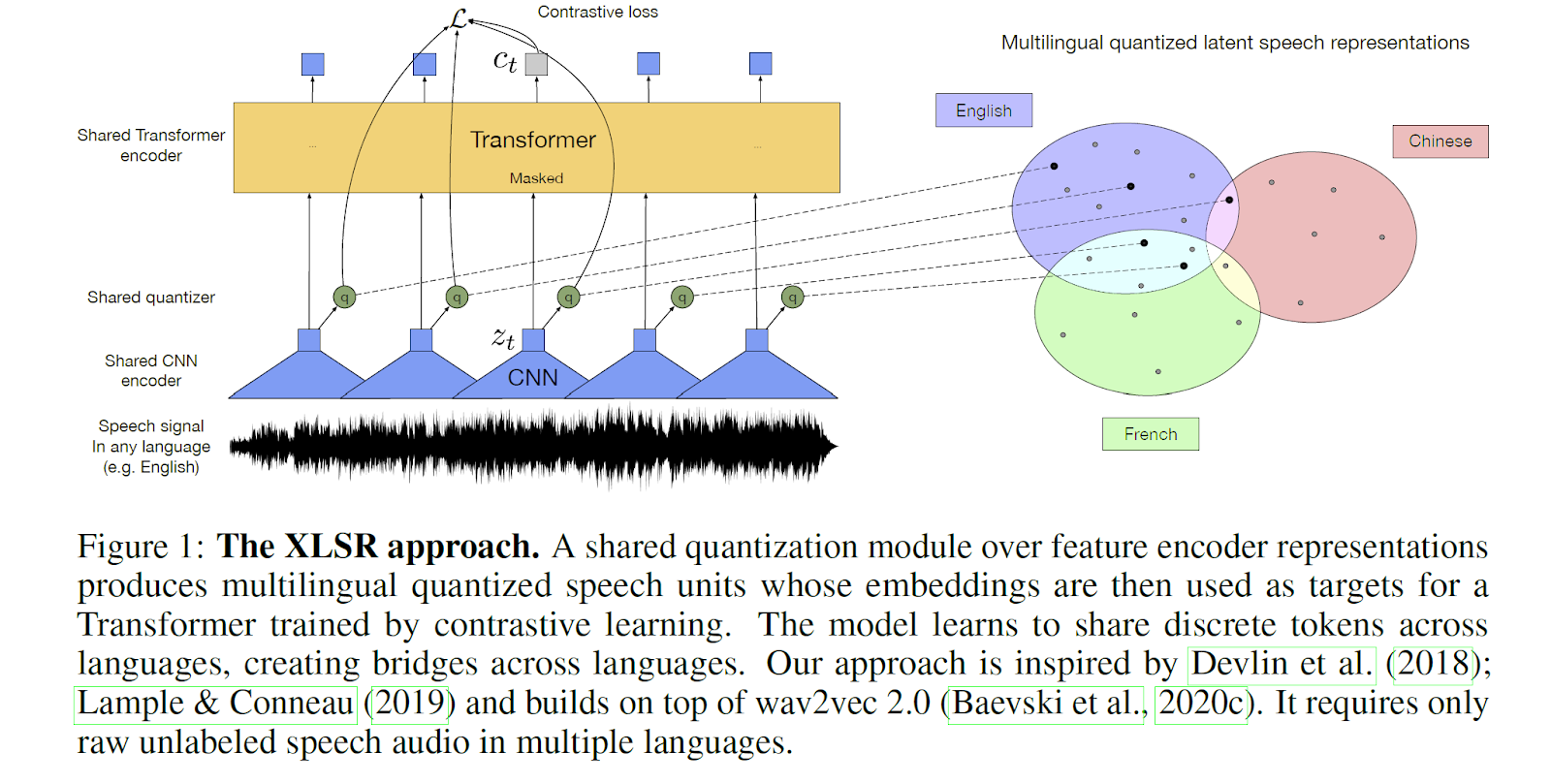
Supply: Conneau, Alexis, et al. “Unsupervised cross-lingual illustration studying for speech recognition.” arXiv preprint arXiv:2006.13979 (2020).
Right now’s commercially accessible ASR fashions are primarily educated utilizing English-language knowledge units and consequently exhibit larger accuracy for English-language enter. Resulting from knowledge availability and market calls for, academia and business have targeted on English for a really very long time. Accuracy for commercially well-liked languages like French, Spanish, Portuguese, and German can also be affordable, however there’s clearly a protracted tail of languages for which restricted coaching knowledge exists and ASR output high quality is correspondingly decrease.
Moreover, most industrial techniques are monolingual, which doesn’t accommodate the multilingual eventualities attribute of many societies. Multilinguality can take the type of back-to-back languages, for instance in a bilingual nation’s media programming. Amazon recently introduced a product integrating language identification (LID) and ASR that makes large strides towards dealing with this.In distinction, translanguaging (also called code switching) entails people using a linguistic system that comes with each phrases and grammar from two languages probably throughout the identical sentence. That is an space the place the analysis group continues to make interesting progress.
Simply as the sphere of Pure Language Processing has taken up multilingual approaches, we see the world of ASR doing the identical within the subsequent decade. As we discover ways to reap the benefits of rising end-to-end strategies, we can practice massively multilingual fashions that may exploit switch studying between a number of languages. A great instance of that is Facebook’s XLS-R: in one demo you’ll be able to converse any of 21 languages with out specifying which and it’ll translate to English. These smarter ASR techniques, by understanding and making use of similarities between languages, will allow high-quality ASR availability for each low-resource languages and mixed-language use instances, and they’re going to achieve this at a industrial quality-level.
Wealthy Standardized Output Objects
“Within the subsequent decade, we consider industrial ASR techniques will return a a lot richer transcript object that may comprise far more than easy phrases. Additional, we foresee this richer output will probably be agreed upon by a requirements group similar to W3C, so that every one APIs return equally constructed outputs. This can additional unlock the potential of voice purposes for everybody on the earth.”
Whereas there’s a lengthy custom of exploration into “wealthy transcription”, initially by NIST, there has not been a lot effort on standardized and extensible codecs for incorporating it into ASR output. The notion of wealthy transcription initially concerned capitalization, punctuation and diarization, however has expanded considerably into speaker roles and a spread of non-linguistic human speech occasions. Anticipated and desired improvements embody the power to transcribe probably simultaneous and overlapping speech from completely different audio system, feelings and different paralinguistic characterizations, and a spread of non-linguistic and even non-human speech scenes and occasions. It will even be attainable to incorporate stylistic or language variety-based data. Tanaka et al. describe a state of affairs the place a consumer would possibly need to select amongst transcription choices at completely different ranges of richness, and clearly the quantity and nature of the extra data we foresee can be specifiable, relying on the downstream software.
Conventional ASR techniques are able to producing a lattice of a number of hypotheses of their journey to determine spoken phrases, and these have proved helpful in human-assisted transcription, spoken dialog techniques, and data retrieval. Clearly, together with n-best data together with confidence in a wealthy output format will encourage extra customers to use it, enhancing consumer experiences. Whereas no commonplace at the moment exists for structuring or storing the extra data at the moment generated or attainable to generate through the speech decoding course of, one promising step on this route is CallMiner’s Open Voice Transcription Standard (OVTS) which makes it simpler for enterprises to discover and use a number of ASR distributors.
We predict that in future, ASR techniques will produce richer output in an ordinary format that may allow extra highly effective downstream purposes. For instance, an ASR system would possibly return the entire lattice of prospects as its output, and an software might use this extra knowledge for clever auto-complete when enhancing the transcript. Equally, ASR transcripts that embody extra metadata (similar to detected regional dialects, accents, environmental noise and/or feelings) might allow extra highly effective search purposes.
ASR for All and At Scale
“On this decade, ASR at scale, that means non-public, reasonably priced, dependable, and quick, will develop into the norm for everybody. These techniques will allow looking out by movies, indexing all media content material we take part in, and making each video accessible for hearing-impaired customers all over the world. ASR would be the key to show each audio and video into one thing accessible and actionable.”


We’re all consuming (and taking part in) huge quantities of content material: podcasts, social media streams, on-line movies, real-time group chats, Zoom conferences and lots of extra. Nevertheless, little or no of this content material is definitely transcribed. Right now, content material transcription is already one of many largest markets for ASR APIs and is about to develop exponentially within the subsequent decade, particularly given how correct and reasonably priced they’re turning into. Having mentioned this, ASR transcription is at the moment used solely in choose purposes (broadcast movies, some conferences, some podcasts, and so on.). Because of this, this media content material just isn’t accessible for many individuals and this can be very troublesome to seek out data after a broadcast or occasion is over.
Sooner or later, this can change. As Matt Thompson predicted in 2010, sooner or later ASR will probably be so low-cost and widespread that we’ll expertise what he known as “The Speakularity”. We are going to count on nearly all audio and video content material to be transcribed and develop into instantly accessible, storable and searchable at scale. And it will not cease there. We are going to need this content material to be actionable. We are going to need extra context for every bit of content material we devour or take part in, similar to auto-generated insights from podcasts or conferences, or automated summaries of key moments in movies… and we’ll count on our NLP techniques to provide these for us as a matter of routine.
Human-Machine Collaboration
“By the top of this decade, we predict we can have consistently evolving ASR techniques, very similar to a dwelling organism, that constantly be taught with the assistance of people or by self-supervision. These techniques will be taught from various sources in the actual world, in a stay trend fairly than in an asynchronous trend, understanding new phrases and language varieties, self-debugging and routinely monitoring for various usages.”

As ASR turns into extra mainstream and covers an ever-increasing variety of use instances, human-machine collaboration is about to play a key function. ASR mannequin coaching is an efficient instance of this. Right now, open supply knowledge units and pre-trained fashions have lowered the limitations to entry for ASR distributors. Nevertheless, the coaching course of remains to be pretty simplistic: accumulate knowledge, annotate the info, practice a mannequin, consider outcomes, repeat, to iteratively enhance the mannequin. This course of is gradual and, in lots of instances, error-prone because of difficulties in tuning or inadequate knowledge. Garnerin et al. have noticed {that a} lack of metadata and inconsistency in representations throughout corpora have made it more durable to supply equal accuracy to all communities in ASR efficiency; that is one thing that Reid & Walker are additionally making an attempt to deal with with the event of metadata requirements.
Sooner or later, people will play an more and more necessary function in accelerating machine studying by clever and environment friendly supervision of ASR coaching. The human-in-the-loop method locations human reviewers contained in the machine studying/suggestions cycle, permitting for ongoing assessment and tuning of mannequin outcomes. This leads to quicker and extra environment friendly machine studying resulting in higher-quality outputs. Earlier this yr we mentioned how ASR enhancements have enabled Rev’s human transcriptionists (often known as “Revvers”), who post-edit an ASR draft, to be much more productive. Revver transcriptions feed proper into improved ASR fashions, making a virtuous cycle.
One space the place human language specialists are nonetheless indispensable in ASR is inverse textual content normalization (ITN), the place acknowledged strings of phrases like “5 {dollars}” are transformed to anticipated written varieties like “$5”. Pusateri et al. describe a hybrid method utilizing “each handcrafted grammars and a statistical mannequin”; Zhang et al. proceed alongside these traces by constraining an RNN with human-crafted FSTs.
Accountable ASR
“ASR techniques of the longer term, like all AI techniques, will adhere to stricter accountable AI rules, in order that techniques deal with all folks equally, are extra explainable, accountable for his or her selections, and respect the privateness of customers and their knowledge.”

ASR techniques of the longer term will probably be anticipated to stick to the 4 rules of accountable AI: equity, explainability, accountability and respect for privateness.
-
Equity: Truthful ASR techniques will acknowledge speech whatever the speaker’s background, socio-economic standing or different traits. It is very important observe that constructing such techniques requires recognizing and decreasing bias in our fashions and coaching knowledge. Happily, governments, non-governmental organizations and companies have begun creating infrastructure for figuring out and assuaging bias.
-
Explainability: ASR techniques will now not be “black bins”: they’ll present, on request, explanations of how knowledge is collected and analyzed and on a mannequin’s efficiency and outputs. This extra transparency will end in higher human oversight of mannequin coaching and efficiency. Together with Gerlings et al., we view explainability with respect to a constellation of stakeholders, together with researchers, builders, prospects and in Rev’s case, transcriptionists. Researchers could need to know why misguided textual content was output to allow them to mitigate the issue, whereas transcriptionists might want some proof why ASR thought that’s what was mentioned, to assist with their evaluation of its validity, significantly in noisy instances the place ASR could “hear” higher than folks do. Weitz et al. have taken necessary preliminary steps in direction of end-user explanations within the context of audio key phrase recognizing. Laguarta & Subirana have integrated clinician-directed explanations right into a speech biomarker system for Alzheimer’s detection.
-
Respect for privateness: “Voice” is taken into account “private knowledge” beneath varied US and worldwide legal guidelines, and the gathering and processing of voice recordings is due to this fact topic to stringent private privateness protections. At Rev, we already provide data security and control features, and future ASR techniques will go even additional to respect each the privateness of consumer knowledge and the privateness of the mannequin. Almost definitely, in lots of instances, this can contain pushing ASR fashions to the sting (on units or browsers). The Voice Privacy Challenge is motivating analysis on this space, and lots of jurisdictions, such because the EU, have begun adopting tips and laws. The sector of Privacy Preserving Machine Learning guarantees to facilitate emphasis on this essential facet of our know-how in order that it may be broadly embraced and trusted by most of the people.
-
Accountability: ASR techniques will probably be monitored to make sure that they adhere to the earlier three rules. This in flip would require a dedication of sources and infrastructure to design and develop the mandatory monitoring techniques and take actions on their findings. Firms that deploy ASR techniques will probably be anticipated to be accountable for his or her use of the know-how and in making particular efforts to stick to accountable ASR rules.
It’s worthwhile mentioning that because the designers, maintainers and customers of ASR techniques, people will probably be liable for implementing and implementing these rules – one more instance of human-machine collaboration.
Conclusion
Many of those advances are already effectively beneath means, and we absolutely count on the subsequent ten years to be fairly an thrilling journey for ASR and associated applied sciences. At Rev, we’re excited to make progress in all these subjects, beginning with the discharge of our v2 model surpassing previous state of the art by 30% relative primarily based on inside and exterior take a look at suites. These all for watching these developments take kind, and catching up on the unbelievable advances of our sister applied sciences like text-to-speech (TTS) and speaker recognition, are inspired to attend the sphere’s upcoming technical conferences, Interspeech, ICASSP and SLT. For these with a extra linguistic bent, COLING and ICPhS are really helpful, and for a business-oriented overview, Voice Summit.
What do you suppose?
We might love to listen to your predictions as effectively.
Quotation
For attribution in tutorial contexts or books, please cite this work as
Migüel Jetté and Corey Miller, “The Way forward for Speech Recognition: The place will we be in 2030?”, The Gradient, 2022.
BibTeX quotation:
@article{miller2021futureofowork,
writer = {Jetté, Migüel and Miller, Corey},
title = {The Way forward for Speech Recognition: The place will we be in 2030?},
journal = {The Gradient},
yr = {2022},
howpublished = {url{https://thegradient.pub/the-future-of-speech-recognition/} },
}
[ad_2]
Source link
